Jak vygenerovat dokončování chatu pomocí odvozování modelu Azure AI
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro dokončování chatu s modely nasazenými do odvozování modelů Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat modely dokončování chatu, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.

Nasazení modelu dokončení chatu. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI a přidat do prostředku model dokončení chatu.
Nainstalujte balíček odvození Azure AI pomocí následujícího příkazu:
pip install -U azure-ai-inference
Použití dokončování chatu
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.core.credentials import AzureKeyCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=AzureKeyCredential(os.environ["AZURE_INFERENCE_CREDENTIAL"]),
model="mistral-large-2407"
)
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
import os
from azure.ai.inference import ChatCompletionsClient
from azure.identity import DefaultAzureCredential
client = ChatCompletionsClient(
endpoint=os.environ["AZURE_INFERENCE_ENDPOINT"],
credential=DefaultAzureCredential(),
model="mistral-large-2407"
)
Vytvoření žádosti o dokončení chatu
Následující příklad ukazuje, jak můžete vytvořit základní požadavek na dokončení chatu do modelu.
from azure.ai.inference.models import SystemMessage, UserMessage
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
)
Poznámka:
Některé modely nepodporují systémové zprávy (role="system"). Když použijete rozhraní API pro odvozování modelu Azure AI, přeloží se systémové zprávy na uživatelské zprávy, což je nejbližší dostupná funkce. Tento překlad se nabízí pro usnadnění, ale je důležité ověřit, že model odpovídá pokynům v systémové zprávě se správnou úrovní spolehlivosti.
Odpověď je následující, kde vidíte statistiku využití modelu:
print("Response:", response.choices[0].message.content)
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Zkontrolujte část v odpovědi a podívejte se na počet tokenů použitých pro výzvu, celkový počet vygenerovaných tokenů a počet tokenů použitých k dokončení.
Streamování obsahu
Ve výchozím nastavení rozhraní API pro dokončování vrátí celý vygenerovaný obsah v jedné odpovědi. Pokud generujete dlouhé dokončení, čekání na odpověď může trvat mnoho sekund.
Obsah můžete streamovat , abyste ho získali při generování. Streamování obsahu umožňuje zahájit zpracování dokončení, jakmile bude obsah k dispozici. Tento režim vrátí objekt, který streamuje odpověď zpět jako události odesílané pouze serverem. Extrahujte bloky dat z rozdílového pole, nikoli z pole zprávy.
Pokud chcete streamovat dokončení, nastavte stream=True při volání modelu.
result = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
temperature=0,
top_p=1,
max_tokens=2048,
stream=True,
)
Pokud chcete vizualizovat výstup, definujte pomocnou funkci pro tisk datového proudu.
def print_stream(result):
"""
Prints the chat completion with streaming.
"""
import time
for update in result:
if update.choices:
print(update.choices[0].delta.content, end="")
Můžete vizualizovat, jak streamování generuje obsah:
print_stream(result)
Prozkoumání dalších parametrů podporovaných klientem odvozováním
Prozkoumejte další parametry, které můžete zadat v klientovi odvození. Úplný seznam všech podporovaných parametrů a jejich odpovídající dokumentace najdete v referenčních informacích k rozhraní API pro odvozování modelů Azure AI.
from azure.ai.inference.models import ChatCompletionsResponseFormatText
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
presence_penalty=0.1,
frequency_penalty=0.8,
max_tokens=2048,
stop=["<|endoftext|>"],
temperature=0,
top_p=1,
response_format={ "type": ChatCompletionsResponseFormatText() },
)
Některé modely nepodporují formátování výstupu JSON. Vždy můžete vyzvat model, aby vygeneroval výstupy JSON. Takové výstupy ale nejsou zaručené jako platné JSON.
Pokud chcete předat parametr, který není v seznamu podporovaných parametrů, můžete ho předat podkladovému modelu pomocí dalších parametrů. Viz Předání dalších parametrů do modelu.
Vytváření výstupů JSON
Některé modely můžou vytvářet výstupy JSON. Nastavte response_format na json_object povolení režimu JSON a zaručte, že zpráva, kterou model vygeneruje, je platný JSON. Model také musíte instruovat, aby vygeneroval JSON sami prostřednictvím systémové nebo uživatelské zprávy. Obsah zprávy může být také částečně oříznut, pokud finish_reason="length", což znamená, že generování překročilo max_tokens nebo že konverzace překročila maximální délku kontextu.
from azure.ai.inference.models import ChatCompletionsResponseFormatJSON
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant that always generate responses in JSON format, using."
" the following format: { ""answer"": ""response"" }."),
UserMessage(content="How many languages are in the world?"),
],
response_format={ "type": ChatCompletionsResponseFormatJSON() }
)
Předání dalších parametrů do modelu
Rozhraní API pro odvozování modelů Azure AI umožňuje předat do modelu další parametry. Následující příklad kódu ukazuje, jak předat další parametr logprobs modelu.
response = client.complete(
messages=[
SystemMessage(content="You are a helpful assistant."),
UserMessage(content="How many languages are in the world?"),
],
model_extras={
"logprobs": True
}
)
Než předáte do rozhraní API pro odvozování modelů Azure AI další parametry, ujistěte se, že váš model tyto dodatečné parametry podporuje. Při provedení požadavku do podkladového modelu se hlavička extra-parameters předá modelu s hodnotou pass-through. Tato hodnota říká koncovému bodu, aby předal do modelu další parametry. Použití dalších parametrů s modelem nezaručuje, že je model dokáže skutečně zpracovat. Přečtěte si dokumentaci k modelu, abyste pochopili, které další parametry jsou podporované.
Použití nástrojů
Některé modely podporují použití nástrojů, které mohou být mimořádným zdrojem, když potřebujete z jazykového modelu přesměrovat konkrétní úlohy a místo toho se spoléhají na deterministický systém nebo dokonce jiný jazykový model. Rozhraní API pro odvozování modelů Azure AI umožňuje definovat nástroje následujícím způsobem.
Následující příklad kódu vytvoří definici nástroje, která dokáže hledat z informací o letu ze dvou různých měst.
from azure.ai.inference.models import FunctionDefinition, ChatCompletionsFunctionToolDefinition
flight_info = ChatCompletionsFunctionToolDefinition(
function=FunctionDefinition(
name="get_flight_info",
description="Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters={
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates",
},
"destination_city": {
"type": "string",
"description": "The flight destination city",
},
},
"required": ["origin_city", "destination_city"],
},
)
)
tools = [flight_info]
V tomto příkladu výstup funkce spočívá v tom, že pro vybranou trasu nejsou k dispozici žádné lety, ale uživatel by měl zvážit pořízení vlaku.
def get_flight_info(loc_origin: str, loc_destination: str):
return {
"info": f"There are no flights available from {loc_origin} to {loc_destination}. You should take a train, specially if it helps to reduce CO2 emissions."
}
Poznámka:
Modely cohere vyžadují, aby odpovědi nástroje byly platným obsahem JSON formátovaným jako řetězec. Při vytváření zpráv typu Tool se ujistěte, že odpověď je platný řetězec JSON.
Vyzvat model k rezervaci letů pomocí této funkce:
messages = [
SystemMessage(
content="You are a helpful assistant that help users to find information about traveling, how to get"
" to places and the different transportations options. You care about the environment and you"
" always have that in mind when answering inqueries.",
),
UserMessage(
content="When is the next flight from Miami to Seattle?",
),
]
response = client.complete(
messages=messages, tools=tools, tool_choice="auto"
)
Můžete zkontrolovat odpověď a zjistit, jestli je potřeba nástroj volat. Zkontrolujte důvod dokončení a zjistěte, jestli se má nástroj volat. Mějte na paměti, že lze určit více typů nástrojů. Tento příklad ukazuje nástroj typu function.
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
print("Finish reason:", response.choices[0].finish_reason)
print("Tool call:", tool_calls)
Pokud chcete pokračovat, připojte tuto zprávu do historie chatu:
messages.append(
response_message
)
Teď je čas volat příslušnou funkci pro zpracování volání nástroje. Následující fragment kódu iteruje přes všechna volání nástroje uvedená v odpovědi a volá odpovídající funkci s příslušnými parametry. Odpověď je také připojena k historii chatu.
import json
from azure.ai.inference.models import ToolMessage
for tool_call in tool_calls:
# Get the tool details:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments.replace("\'", "\""))
tool_call_id = tool_call.id
print(f"Calling function `{function_name}` with arguments {function_args}")
# Call the function defined above using `locals()`, which returns the list of all functions
# available in the scope as a dictionary. Notice that this is just done as a simple way to get
# the function callable from its string name. Then we can call it with the corresponding
# arguments.
callable_func = locals()[function_name]
function_response = callable_func(**function_args)
print("->", function_response)
# Once we have a response from the function and its arguments, we can append a new message to the chat
# history. Notice how we are telling to the model that this chat message came from a tool:
messages.append(
ToolMessage(
tool_call_id=tool_call_id,
content=json.dumps(function_response)
)
)
Zobrazte odpověď z modelu:
response = client.complete(
messages=messages,
tools=tools,
)
Použití bezpečnosti obsahu
Rozhraní API pro odvozování modelů Azure AI podporuje bezpečnost obsahu Azure AI. Když používáte nasazení se zapnutou bezpečností obsahu Azure AI, vstupy a výstupy procházejí sadou klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Následující příklad ukazuje, jak zpracovat události, když model zjistí škodlivý obsah ve vstupní výzvě a bezpečnost obsahu je povolen.
from azure.ai.inference.models import AssistantMessage, UserMessage, SystemMessage
try:
response = client.complete(
messages=[
SystemMessage(content="You are an AI assistant that helps people find information."),
UserMessage(content="Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."),
]
)
print(response.choices[0].message.content)
except HttpResponseError as ex:
if ex.status_code == 400:
response = ex.response.json()
if isinstance(response, dict) and "error" in response:
print(f"Your request triggered an {response['error']['code']} error:\n\t {response['error']['message']}")
else:
raise
raise
Tip
Další informace o tom, jak nakonfigurovat a řídit nastavení zabezpečení obsahu Azure AI, najdete v dokumentaci k zabezpečení obsahu Azure AI.
Použití dokončování chatu s obrázky
Některé modely můžou zdůvodnět text a obrázky a generovat dokončování textu na základě obou typů vstupu. V této části prozkoumáte možnosti některých modelů pro vizi způsobem chatu:
Důležité
Některé modely podporují pro každou konverzaci chatu jenom jeden obrázek a v kontextu se zachová jenom poslední obrázek. Pokud přidáte více obrázků, dojde k chybě.
Pokud chcete tuto funkci zobrazit, stáhněte si obrázek a zakódujte informace jako base64 řetězec. Výsledná data by měla být uvnitř adresy URL dat:
from urllib.request import urlopen, Request
import base64
image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg"
image_format = "jpeg"
request = Request(image_url, headers={"User-Agent": "Mozilla/5.0"})
image_data = base64.b64encode(urlopen(request).read()).decode("utf-8")
data_url = f"data:image/{image_format};base64,{image_data}"
Vizualizace obrázku:
import requests
import IPython.display as Disp
Disp.Image(requests.get(image_url).content)

Teď vytvořte žádost o dokončení chatu s obrázkem:
from azure.ai.inference.models import TextContentItem, ImageContentItem, ImageUrl
response = client.complete(
messages=[
SystemMessage("You are a helpful assistant that can generate responses based on images."),
UserMessage(content=[
TextContentItem(text="Which conclusion can be extracted from the following chart?"),
ImageContentItem(image=ImageUrl(url=data_url))
]),
],
temperature=0,
top_p=1,
max_tokens=2048,
)
Odpověď je následující, kde vidíte statistiku využití modelu:
print(f"{response.choices[0].message.role}:\n\t{response.choices[0].message.content}\n")
print("Model:", response.model)
print("Usage:")
print("\tPrompt tokens:", response.usage.prompt_tokens)
print("\tCompletion tokens:", response.usage.completion_tokens)
print("\tTotal tokens:", response.usage.total_tokens)
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro dokončování chatu s modely nasazenými do odvozování modelů Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat modely dokončování chatu, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu dokončení chatu. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI a přidat do prostředku model dokončení chatu.
Pomocí následujícího příkazu nainstalujte knihovnu Azure Inference pro JavaScript:
npm install @azure-rest/ai-inference
Použití dokončování chatu
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { AzureKeyCredential } from "@azure/core-auth";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new AzureKeyCredential(process.env.AZURE_INFERENCE_CREDENTIAL)
);
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
import ModelClient from "@azure-rest/ai-inference";
import { isUnexpected } from "@azure-rest/ai-inference";
import { DefaultAzureCredential } from "@azure/identity";
const client = new ModelClient(
process.env.AZURE_INFERENCE_ENDPOINT,
new DefaultAzureCredential()
);
Vytvoření žádosti o dokončení chatu
Následující příklad ukazuje, jak můžete vytvořit základní požadavek na dokončení chatu do modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
Poznámka:
Některé modely nepodporují systémové zprávy (role="system"). Když použijete rozhraní API pro odvozování modelu Azure AI, přeloží se systémové zprávy na uživatelské zprávy, což je nejbližší dostupná funkce. Tento překlad se nabízí pro usnadnění, ale je důležité ověřit, že model odpovídá pokynům v systémové zprávě se správnou úrovní spolehlivosti.
Odpověď je následující, kde vidíte statistiku využití modelu:
if (isUnexpected(response)) {
throw response.body.error;
}
console.log("Response: ", response.body.choices[0].message.content);
console.log("Model: ", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Zkontrolujte část v odpovědi a podívejte se na počet tokenů použitých pro výzvu, celkový počet vygenerovaných tokenů a počet tokenů použitých k dokončení.
Streamování obsahu
Ve výchozím nastavení rozhraní API pro dokončování vrátí celý vygenerovaný obsah v jedné odpovědi. Pokud generujete dlouhé dokončení, čekání na odpověď může trvat mnoho sekund.
Obsah můžete streamovat , abyste ho získali při generování. Streamování obsahu umožňuje zahájit zpracování dokončení, jakmile bude obsah k dispozici. Tento režim vrátí objekt, který streamuje odpověď zpět jako události odesílané pouze serverem. Extrahujte bloky dat z rozdílového pole, nikoli z pole zprávy.
K dokončení datových proudů použijte .asNodeStream() při volání modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
}).asNodeStream();
Můžete vizualizovat, jak streamování generuje obsah:
var stream = response.body;
if (!stream) {
stream.destroy();
throw new Error(`Failed to get chat completions with status: ${response.status}`);
}
if (response.status !== "200") {
throw new Error(`Failed to get chat completions: ${response.body.error}`);
}
var sses = createSseStream(stream);
for await (const event of sses) {
if (event.data === "[DONE]") {
return;
}
for (const choice of (JSON.parse(event.data)).choices) {
console.log(choice.delta?.content ?? "");
}
}
Prozkoumání dalších parametrů podporovaných klientem odvozováním
Prozkoumejte další parametry, které můžete zadat v klientovi odvození. Úplný seznam všech podporovaných parametrů a jejich odpovídající dokumentace najdete v referenčních informacích k rozhraní API pro odvozování modelů Azure AI.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
presence_penalty: "0.1",
frequency_penalty: "0.8",
max_tokens: 2048,
stop: ["<|endoftext|>"],
temperature: 0,
top_p: 1,
response_format: { type: "text" },
}
});
Některé modely nepodporují formátování výstupu JSON. Vždy můžete vyzvat model, aby vygeneroval výstupy JSON. Takové výstupy ale nejsou zaručené jako platné JSON.
Pokud chcete předat parametr, který není v seznamu podporovaných parametrů, můžete ho předat podkladovému modelu pomocí dalších parametrů. Viz Předání dalších parametrů do modelu.
Vytváření výstupů JSON
Některé modely můžou vytvářet výstupy JSON. Nastavte response_format na json_object povolení režimu JSON a zaručte, že zpráva, kterou model vygeneruje, je platný JSON. Model také musíte instruovat, aby vygeneroval JSON sami prostřednictvím systémové nebo uživatelské zprávy. Obsah zprávy může být také částečně oříznut, pokud finish_reason="length", což znamená, že generování překročilo max_tokens nebo že konverzace překročila maximální délku kontextu.
var messages = [
{ role: "system", content: "You are a helpful assistant that always generate responses in JSON format, using."
+ " the following format: { \"answer\": \"response\" }." },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
response_format: { type: "json_object" }
}
});
Předání dalších parametrů do modelu
Rozhraní API pro odvozování modelů Azure AI umožňuje předat do modelu další parametry. Následující příklad kódu ukazuje, jak předat další parametr logprobs modelu.
var messages = [
{ role: "system", content: "You are a helpful assistant" },
{ role: "user", content: "How many languages are in the world?" },
];
var response = await client.path("/chat/completions").post({
headers: {
"extra-params": "pass-through"
},
body: {
messages: messages,
logprobs: true
}
});
Než předáte do rozhraní API pro odvozování modelů Azure AI další parametry, ujistěte se, že váš model tyto dodatečné parametry podporuje. Při provedení požadavku do podkladového modelu se hlavička extra-parameters předá modelu s hodnotou pass-through. Tato hodnota říká koncovému bodu, aby předal do modelu další parametry. Použití dalších parametrů s modelem nezaručuje, že je model dokáže skutečně zpracovat. Přečtěte si dokumentaci k modelu, abyste pochopili, které další parametry jsou podporované.
Použití nástrojů
Některé modely podporují použití nástrojů, které mohou být mimořádným zdrojem, když potřebujete z jazykového modelu přesměrovat konkrétní úlohy a místo toho se spoléhají na deterministický systém nebo dokonce jiný jazykový model. Rozhraní API pro odvozování modelů Azure AI umožňuje definovat nástroje následujícím způsobem.
Následující příklad kódu vytvoří definici nástroje, která dokáže hledat z informací o letu ze dvou různých měst.
const flight_info = {
name: "get_flight_info",
description: "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
parameters: {
type: "object",
properties: {
origin_city: {
type: "string",
description: "The name of the city where the flight originates",
},
destination_city: {
type: "string",
description: "The flight destination city",
},
},
required: ["origin_city", "destination_city"],
},
}
const tools = [
{
type: "function",
function: flight_info,
},
];
V tomto příkladu výstup funkce spočívá v tom, že pro vybranou trasu nejsou k dispozici žádné lety, ale uživatel by měl zvážit pořízení vlaku.
function get_flight_info(loc_origin, loc_destination) {
return {
info: "There are no flights available from " + loc_origin + " to " + loc_destination + ". You should take a train, specially if it helps to reduce CO2 emissions."
}
}
Poznámka:
Modely cohere vyžadují, aby odpovědi nástroje byly platným obsahem JSON formátovaným jako řetězec. Při vytváření zpráv typu Tool se ujistěte, že odpověď je platný řetězec JSON.
Vyzvat model k rezervaci letů pomocí této funkce:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
tool_choice: "auto"
}
});
Můžete zkontrolovat odpověď a zjistit, jestli je potřeba nástroj volat. Zkontrolujte důvod dokončení a zjistěte, jestli se má nástroj volat. Mějte na paměti, že lze určit více typů nástrojů. Tento příklad ukazuje nástroj typu function.
const response_message = response.body.choices[0].message;
const tool_calls = response_message.tool_calls;
console.log("Finish reason: " + response.body.choices[0].finish_reason);
console.log("Tool call: " + tool_calls);
Pokud chcete pokračovat, připojte tuto zprávu do historie chatu:
messages.push(response_message);
Teď je čas volat příslušnou funkci pro zpracování volání nástroje. Následující fragment kódu iteruje přes všechna volání nástroje uvedená v odpovědi a volá odpovídající funkci s příslušnými parametry. Odpověď je také připojena k historii chatu.
function applyToolCall({ function: call, id }) {
// Get the tool details:
const tool_params = JSON.parse(call.arguments);
console.log("Calling function " + call.name + " with arguments " + tool_params);
// Call the function defined above using `window`, which returns the list of all functions
// available in the scope as a dictionary. Notice that this is just done as a simple way to get
// the function callable from its string name. Then we can call it with the corresponding
// arguments.
const function_response = tool_params.map(window[call.name]);
console.log("-> " + function_response);
return function_response
}
for (const tool_call of tool_calls) {
var tool_response = tool_call.apply(applyToolCall);
messages.push(
{
role: "tool",
tool_call_id: tool_call.id,
content: tool_response
}
);
}
Zobrazte odpověď z modelu:
var result = await client.path("/chat/completions").post({
body: {
messages: messages,
tools: tools,
}
});
Použití bezpečnosti obsahu
Rozhraní API pro odvozování modelů Azure AI podporuje bezpečnost obsahu Azure AI. Když používáte nasazení se zapnutou bezpečností obsahu Azure AI, vstupy a výstupy procházejí sadou klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Následující příklad ukazuje, jak zpracovat události, když model zjistí škodlivý obsah ve vstupní výzvě a bezpečnost obsahu je povolen.
try {
var messages = [
{ role: "system", content: "You are an AI assistant that helps people find information." },
{ role: "user", content: "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills." },
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
}
});
console.log(response.body.choices[0].message.content);
}
catch (error) {
if (error.status_code == 400) {
var response = JSON.parse(error.response._content);
if (response.error) {
console.log(`Your request triggered an ${response.error.code} error:\n\t ${response.error.message}`);
}
else
{
throw error;
}
}
}
Tip
Další informace o tom, jak nakonfigurovat a řídit nastavení zabezpečení obsahu Azure AI, najdete v dokumentaci k zabezpečení obsahu Azure AI.
Použití dokončování chatu s obrázky
Některé modely můžou zdůvodnět text a obrázky a generovat dokončování textu na základě obou typů vstupu. V této části prozkoumáte možnosti některých modelů pro vizi způsobem chatu:
Důležité
Některé modely podporují pro každou konverzaci chatu jenom jeden obrázek a v kontextu se zachová jenom poslední obrázek. Pokud přidáte více obrázků, dojde k chybě.
Pokud chcete tuto funkci zobrazit, stáhněte si obrázek a zakódujte informace jako base64 řetězec. Výsledná data by měla být uvnitř adresy URL dat:
const image_url = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
const image_format = "jpeg";
const response = await fetch(image_url, { headers: { "User-Agent": "Mozilla/5.0" } });
const image_data = await response.arrayBuffer();
const image_data_base64 = Buffer.from(image_data).toString("base64");
const data_url = `data:image/${image_format};base64,${image_data_base64}`;
Vizualizace obrázku:
const img = document.createElement("img");
img.src = data_url;
document.body.appendChild(img);
Teď vytvořte žádost o dokončení chatu s obrázkem:
var messages = [
{ role: "system", content: "You are a helpful assistant that can generate responses based on images." },
{ role: "user", content:
[
{ type: "text", text: "Which conclusion can be extracted from the following chart?" },
{ type: "image_url", image:
{
url: data_url
}
}
]
}
];
var response = await client.path("/chat/completions").post({
body: {
messages: messages,
temperature: 0,
top_p: 1,
max_tokens: 2048,
}
});
Odpověď je následující, kde vidíte statistiku využití modelu:
console.log(response.body.choices[0].message.role + ": " + response.body.choices[0].message.content);
console.log("Model:", response.body.model);
console.log("Usage:");
console.log("\tPrompt tokens:", response.body.usage.prompt_tokens);
console.log("\tCompletion tokens:", response.body.usage.completion_tokens);
console.log("\tTotal tokens:", response.body.usage.total_tokens);
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro dokončování chatu s modely nasazenými do odvozování modelů Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat modely dokončování chatu, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu dokončení chatu. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI a přidat do prostředku model dokončení chatu.
Přidejte do projektu balíček pro odvození Azure AI:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-ai-inference</artifactId> <version>1.0.0-beta.1</version> </dependency>Pokud používáte ID Entra, potřebujete také následující balíček:
<dependency> <groupId>com.azure</groupId> <artifactId>azure-identity</artifactId> <version>1.13.3</version> </dependency>Naimportujte následující obor názvů:
package com.azure.ai.inference.usage; import com.azure.ai.inference.EmbeddingsClient; import com.azure.ai.inference.EmbeddingsClientBuilder; import com.azure.ai.inference.models.EmbeddingsResult; import com.azure.ai.inference.models.EmbeddingItem; import com.azure.core.credential.AzureKeyCredential; import com.azure.core.util.Configuration; import java.util.ArrayList; import java.util.List;
Použití dokončování chatu
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
Vytvoření žádosti o dokončení chatu
Následující příklad ukazuje, jak můžete vytvořit základní požadavek na dokončení chatu do modelu.
Poznámka:
Některé modely nepodporují systémové zprávy (role="system"). Když použijete rozhraní API pro odvozování modelu Azure AI, přeloží se systémové zprávy na uživatelské zprávy, což je nejbližší dostupná funkce. Tento překlad se nabízí pro usnadnění, ale je důležité ověřit, že model odpovídá pokynům v systémové zprávě se správnou úrovní spolehlivosti.
Odpověď je následující, kde vidíte statistiku využití modelu:
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Zkontrolujte část v odpovědi a podívejte se na počet tokenů použitých pro výzvu, celkový počet vygenerovaných tokenů a počet tokenů použitých k dokončení.
Streamování obsahu
Ve výchozím nastavení rozhraní API pro dokončování vrátí celý vygenerovaný obsah v jedné odpovědi. Pokud generujete dlouhé dokončení, čekání na odpověď může trvat mnoho sekund.
Obsah můžete streamovat , abyste ho získali při generování. Streamování obsahu umožňuje zahájit zpracování dokončení, jakmile bude obsah k dispozici. Tento režim vrátí objekt, který streamuje odpověď zpět jako události odesílané pouze serverem. Extrahujte bloky dat z rozdílového pole, nikoli z pole zprávy.
Můžete vizualizovat, jak streamování generuje obsah:
Prozkoumání dalších parametrů podporovaných klientem odvozováním
Prozkoumejte další parametry, které můžete zadat v klientovi odvození. Úplný seznam všech podporovaných parametrů a jejich odpovídající dokumentace najdete v referenčních informacích k rozhraní API pro odvozování modelů Azure AI. Některé modely nepodporují formátování výstupu JSON. Vždy můžete vyzvat model, aby vygeneroval výstupy JSON. Takové výstupy ale nejsou zaručené jako platné JSON.
Pokud chcete předat parametr, který není v seznamu podporovaných parametrů, můžete ho předat podkladovému modelu pomocí dalších parametrů. Viz Předání dalších parametrů do modelu.
Vytváření výstupů JSON
Některé modely můžou vytvářet výstupy JSON. Nastavte response_format na json_object povolení režimu JSON a zaručte, že zpráva, kterou model vygeneruje, je platný JSON. Model také musíte instruovat, aby vygeneroval JSON sami prostřednictvím systémové nebo uživatelské zprávy. Obsah zprávy může být také částečně oříznut, pokud finish_reason="length", což znamená, že generování překročilo max_tokens nebo že konverzace překročila maximální délku kontextu.
Předání dalších parametrů do modelu
Rozhraní API pro odvozování modelů Azure AI umožňuje předat do modelu další parametry. Následující příklad kódu ukazuje, jak předat další parametr logprobs modelu.
Než předáte do rozhraní API pro odvozování modelů Azure AI další parametry, ujistěte se, že váš model tyto dodatečné parametry podporuje. Při provedení požadavku do podkladového modelu se hlavička extra-parameters předá modelu s hodnotou pass-through. Tato hodnota říká koncovému bodu, aby předal do modelu další parametry. Použití dalších parametrů s modelem nezaručuje, že je model dokáže skutečně zpracovat. Přečtěte si dokumentaci k modelu, abyste pochopili, které další parametry jsou podporované.
Použití nástrojů
Některé modely podporují použití nástrojů, které mohou být mimořádným zdrojem, když potřebujete z jazykového modelu přesměrovat konkrétní úlohy a místo toho se spoléhají na deterministický systém nebo dokonce jiný jazykový model. Rozhraní API pro odvozování modelů Azure AI umožňuje definovat nástroje následujícím způsobem.
Následující příklad kódu vytvoří definici nástroje, která dokáže hledat z informací o letu ze dvou různých měst.
V tomto příkladu výstup funkce spočívá v tom, že pro vybranou trasu nejsou k dispozici žádné lety, ale uživatel by měl zvážit pořízení vlaku.
Poznámka:
Modely cohere vyžadují, aby odpovědi nástroje byly platným obsahem JSON formátovaným jako řetězec. Při vytváření zpráv typu Tool se ujistěte, že odpověď je platný řetězec JSON.
Vyzvat model k rezervaci letů pomocí této funkce:
Můžete zkontrolovat odpověď a zjistit, jestli je potřeba nástroj volat. Zkontrolujte důvod dokončení a zjistěte, jestli se má nástroj volat. Mějte na paměti, že lze určit více typů nástrojů. Tento příklad ukazuje nástroj typu function.
Pokud chcete pokračovat, připojte tuto zprávu do historie chatu:
Teď je čas volat příslušnou funkci pro zpracování volání nástroje. Následující fragment kódu iteruje přes všechna volání nástroje uvedená v odpovědi a volá odpovídající funkci s příslušnými parametry. Odpověď je také připojena k historii chatu.
Zobrazte odpověď z modelu:
Použití bezpečnosti obsahu
Rozhraní API pro odvozování modelů Azure AI podporuje bezpečnost obsahu Azure AI. Když používáte nasazení se zapnutou bezpečností obsahu Azure AI, vstupy a výstupy procházejí sadou klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Následující příklad ukazuje, jak zpracovat události, když model zjistí škodlivý obsah ve vstupní výzvě a bezpečnost obsahu je povolen.
Tip
Další informace o tom, jak nakonfigurovat a řídit nastavení zabezpečení obsahu Azure AI, najdete v dokumentaci k zabezpečení obsahu Azure AI.
Použití dokončování chatu s obrázky
Některé modely můžou zdůvodnět text a obrázky a generovat dokončování textu na základě obou typů vstupu. V této části prozkoumáte možnosti některých modelů pro vizi způsobem chatu:
Důležité
Některé modely podporují pro každou konverzaci chatu jenom jeden obrázek a v kontextu se zachová jenom poslední obrázek. Pokud přidáte více obrázků, dojde k chybě.
Pokud chcete tuto funkci zobrazit, stáhněte si obrázek a zakódujte informace jako base64 řetězec. Výsledná data by měla být uvnitř adresy URL dat:
Vizualizace obrázku:
Teď vytvořte žádost o dokončení chatu s obrázkem:
Odpověď je následující, kde vidíte statistiku využití modelu:
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro dokončování chatu s modely nasazenými do odvozování modelů Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat modely dokončování chatu, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
Nasazení modelu dokončení chatu. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI a přidat do prostředku model dokončení chatu.
Nainstalujte balíček odvození Azure AI pomocí následujícího příkazu:
dotnet add package Azure.AI.Inference --prereleasePokud používáte ID Entra, potřebujete také následující balíček:
dotnet add package Azure.Identity
Použití dokončování chatu
Nejprve vytvořte klienta, který bude model využívat. Následující kód používá adresu URL koncového bodu a klíč, které jsou uložené v proměnných prostředí.
ChatCompletionsClient client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new AzureKeyCredential(Environment.GetEnvironmentVariable("AZURE_INFERENCE_CREDENTIAL")),
"mistral-large-2407"
);
Pokud jste nakonfigurovali prostředek na podporu Microsoft Entra ID , můžete k vytvoření klienta použít následující fragment kódu.
client = new ChatCompletionsClient(
new Uri(Environment.GetEnvironmentVariable("AZURE_INFERENCE_ENDPOINT")),
new DefaultAzureCredential(includeInteractiveCredentials: true),
"mistral-large-2407"
);
Vytvoření žádosti o dokončení chatu
Následující příklad ukazuje, jak můžete vytvořit základní požadavek na dokončení chatu do modelu.
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
};
Response<ChatCompletions> response = client.Complete(requestOptions);
Poznámka:
Některé modely nepodporují systémové zprávy (role="system"). Když použijete rozhraní API pro odvozování modelu Azure AI, přeloží se systémové zprávy na uživatelské zprávy, což je nejbližší dostupná funkce. Tento překlad se nabízí pro usnadnění, ale je důležité ověřit, že model odpovídá pokynům v systémové zprávě se správnou úrovní spolehlivosti.
Odpověď je následující, kde vidíte statistiku využití modelu:
Console.WriteLine($"Response: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
Response: As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.
Model: mistral-large-2407
Usage:
Prompt tokens: 19
Total tokens: 91
Completion tokens: 72
usage Zkontrolujte část v odpovědi a podívejte se na počet tokenů použitých pro výzvu, celkový počet vygenerovaných tokenů a počet tokenů použitých k dokončení.
Streamování obsahu
Ve výchozím nastavení rozhraní API pro dokončování vrátí celý vygenerovaný obsah v jedné odpovědi. Pokud generujete dlouhé dokončení, čekání na odpověď může trvat mnoho sekund.
Obsah můžete streamovat , abyste ho získali při generování. Streamování obsahu umožňuje zahájit zpracování dokončení, jakmile bude obsah k dispozici. Tento režim vrátí objekt, který streamuje odpověď zpět jako události odesílané pouze serverem. Extrahujte bloky dat z rozdílového pole, nikoli z pole zprávy.
K dokončení streamu použijte CompleteStreamingAsync metodu při volání modelu. Všimněte si, že v tomto příkladu je volání zabaleno do asynchronní metody.
static async Task StreamMessageAsync(ChatCompletionsClient client)
{
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world? Write an essay about it.")
},
MaxTokens=4096
};
StreamingResponse<StreamingChatCompletionsUpdate> streamResponse = await client.CompleteStreamingAsync(requestOptions);
await PrintStream(streamResponse);
}
Pokud chcete vizualizovat výstup, definujte asynchronní metodu pro tisk datového proudu v konzole.
static async Task PrintStream(StreamingResponse<StreamingChatCompletionsUpdate> response)
{
await foreach (StreamingChatCompletionsUpdate chatUpdate in response)
{
if (chatUpdate.Role.HasValue)
{
Console.Write($"{chatUpdate.Role.Value.ToString().ToUpperInvariant()}: ");
}
if (!string.IsNullOrEmpty(chatUpdate.ContentUpdate))
{
Console.Write(chatUpdate.ContentUpdate);
}
}
}
Můžete vizualizovat, jak streamování generuje obsah:
StreamMessageAsync(client).GetAwaiter().GetResult();
Prozkoumání dalších parametrů podporovaných klientem odvozováním
Prozkoumejte další parametry, které můžete zadat v klientovi odvození. Úplný seznam všech podporovaných parametrů a jejich odpovídající dokumentace najdete v referenčních informacích k rozhraní API pro odvozování modelů Azure AI.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
PresencePenalty = 0.1f,
FrequencyPenalty = 0.8f,
MaxTokens = 2048,
StopSequences = { "<|endoftext|>" },
Temperature = 0,
NucleusSamplingFactor = 1,
ResponseFormat = new ChatCompletionsResponseFormatText()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Některé modely nepodporují formátování výstupu JSON. Vždy můžete vyzvat model, aby vygeneroval výstupy JSON. Takové výstupy ale nejsou zaručené jako platné JSON.
Pokud chcete předat parametr, který není v seznamu podporovaných parametrů, můžete ho předat podkladovému modelu pomocí dalších parametrů. Viz Předání dalších parametrů do modelu.
Vytváření výstupů JSON
Některé modely můžou vytvářet výstupy JSON. Nastavte response_format na json_object povolení režimu JSON a zaručte, že zpráva, kterou model vygeneruje, je platný JSON. Model také musíte instruovat, aby vygeneroval JSON sami prostřednictvím systémové nebo uživatelské zprávy. Obsah zprávy může být také částečně oříznut, pokud finish_reason="length", což znamená, že generování překročilo max_tokens nebo že konverzace překročila maximální délku kontextu.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage(
"You are a helpful assistant that always generate responses in JSON format, " +
"using. the following format: { \"answer\": \"response\" }."
),
new ChatRequestUserMessage(
"How many languages are in the world?"
)
},
ResponseFormat = new ChatCompletionsResponseFormatJSON()
};
response = client.Complete(requestOptions);
Console.WriteLine($"Response: {response.Value.Content}");
Předání dalších parametrů do modelu
Rozhraní API pro odvozování modelů Azure AI umožňuje předat do modelu další parametry. Následující příklad kódu ukazuje, jak předat další parametr logprobs modelu.
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are a helpful assistant."),
new ChatRequestUserMessage("How many languages are in the world?")
},
AdditionalProperties = { { "logprobs", BinaryData.FromString("true") } },
};
response = client.Complete(requestOptions, extraParams: ExtraParameters.PassThrough);
Console.WriteLine($"Response: {response.Value.Content}");
Než předáte do rozhraní API pro odvozování modelů Azure AI další parametry, ujistěte se, že váš model tyto dodatečné parametry podporuje. Při provedení požadavku do podkladového modelu se hlavička extra-parameters předá modelu s hodnotou pass-through. Tato hodnota říká koncovému bodu, aby předal do modelu další parametry. Použití dalších parametrů s modelem nezaručuje, že je model dokáže skutečně zpracovat. Přečtěte si dokumentaci k modelu, abyste pochopili, které další parametry jsou podporované.
Použití nástrojů
Některé modely podporují použití nástrojů, které mohou být mimořádným zdrojem, když potřebujete z jazykového modelu přesměrovat konkrétní úlohy a místo toho se spoléhají na deterministický systém nebo dokonce jiný jazykový model. Rozhraní API pro odvozování modelů Azure AI umožňuje definovat nástroje následujícím způsobem.
Následující příklad kódu vytvoří definici nástroje, která dokáže hledat z informací o letu ze dvou různých měst.
FunctionDefinition flightInfoFunction = new FunctionDefinition("getFlightInfo")
{
Description = "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
Parameters = BinaryData.FromObjectAsJson(new
{
Type = "object",
Properties = new
{
origin_city = new
{
Type = "string",
Description = "The name of the city where the flight originates"
},
destination_city = new
{
Type = "string",
Description = "The flight destination city"
}
}
},
new JsonSerializerOptions() { PropertyNamingPolicy = JsonNamingPolicy.CamelCase }
)
};
ChatCompletionsFunctionToolDefinition getFlightTool = new ChatCompletionsFunctionToolDefinition(flightInfoFunction);
V tomto příkladu výstup funkce spočívá v tom, že pro vybranou trasu nejsou k dispozici žádné lety, ale uživatel by měl zvážit pořízení vlaku.
static string getFlightInfo(string loc_origin, string loc_destination)
{
return JsonSerializer.Serialize(new
{
info = $"There are no flights available from {loc_origin} to {loc_destination}. You " +
"should take a train, specially if it helps to reduce CO2 emissions."
});
}
Poznámka:
Modely cohere vyžadují, aby odpovědi nástroje byly platným obsahem JSON formátovaným jako řetězec. Při vytváření zpráv typu Tool se ujistěte, že odpověď je platný řetězec JSON.
Vyzvat model k rezervaci letů pomocí této funkce:
var chatHistory = new List<ChatRequestMessage>(){
new ChatRequestSystemMessage(
"You are a helpful assistant that help users to find information about traveling, " +
"how to get to places and the different transportations options. You care about the" +
"environment and you always have that in mind when answering inqueries."
),
new ChatRequestUserMessage("When is the next flight from Miami to Seattle?")
};
requestOptions = new ChatCompletionsOptions(chatHistory);
requestOptions.Tools.Add(getFlightTool);
requestOptions.ToolChoice = ChatCompletionsToolChoice.Auto;
response = client.Complete(requestOptions);
Můžete zkontrolovat odpověď a zjistit, jestli je potřeba nástroj volat. Zkontrolujte důvod dokončení a zjistěte, jestli se má nástroj volat. Mějte na paměti, že lze určit více typů nástrojů. Tento příklad ukazuje nástroj typu function.
var responseMessage = response.Value;
var toolsCall = responseMessage.ToolCalls;
Console.WriteLine($"Finish reason: {response.Value.Choices[0].FinishReason}");
Console.WriteLine($"Tool call: {toolsCall[0].Id}");
Pokud chcete pokračovat, připojte tuto zprávu do historie chatu:
requestOptions.Messages.Add(new ChatRequestAssistantMessage(response.Value));
Teď je čas volat příslušnou funkci pro zpracování volání nástroje. Následující fragment kódu iteruje přes všechna volání nástroje uvedená v odpovědi a volá odpovídající funkci s příslušnými parametry. Odpověď je také připojena k historii chatu.
foreach (ChatCompletionsToolCall tool in toolsCall)
{
if (tool is ChatCompletionsFunctionToolCall functionTool)
{
// Get the tool details:
string callId = functionTool.Id;
string toolName = functionTool.Name;
string toolArgumentsString = functionTool.Arguments;
Dictionary<string, object> toolArguments = JsonSerializer.Deserialize<Dictionary<string, object>>(toolArgumentsString);
// Here you have to call the function defined. In this particular example we use
// reflection to find the method we definied before in an static class called
// `ChatCompletionsExamples`. Using reflection allows us to call a function
// by string name. Notice that this is just done for demonstration purposes as a
// simple way to get the function callable from its string name. Then we can call
// it with the corresponding arguments.
var flags = BindingFlags.Instance | BindingFlags.Public | BindingFlags.NonPublic | BindingFlags.Static;
string toolResponse = (string)typeof(ChatCompletionsExamples).GetMethod(toolName, flags).Invoke(null, toolArguments.Values.Cast<object>().ToArray());
Console.WriteLine("->", toolResponse);
requestOptions.Messages.Add(new ChatRequestToolMessage(toolResponse, callId));
}
else
throw new Exception("Unsupported tool type");
}
Zobrazte odpověď z modelu:
response = client.Complete(requestOptions);
Použití bezpečnosti obsahu
Rozhraní API pro odvozování modelů Azure AI podporuje bezpečnost obsahu Azure AI. Když používáte nasazení se zapnutou bezpečností obsahu Azure AI, vstupy a výstupy procházejí sadou klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Následující příklad ukazuje, jak zpracovat události, když model zjistí škodlivý obsah ve vstupní výzvě a bezpečnost obsahu je povolen.
try
{
requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage(
"Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
),
},
};
response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
}
catch (RequestFailedException ex)
{
if (ex.ErrorCode == "content_filter")
{
Console.WriteLine($"Your query has trigger Azure Content Safety: {ex.Message}");
}
else
{
throw;
}
}
Tip
Další informace o tom, jak nakonfigurovat a řídit nastavení zabezpečení obsahu Azure AI, najdete v dokumentaci k zabezpečení obsahu Azure AI.
Použití dokončování chatu s obrázky
Některé modely můžou zdůvodnět text a obrázky a generovat dokončování textu na základě obou typů vstupu. V této části prozkoumáte možnosti některých modelů pro vizi způsobem chatu:
Důležité
Některé modely podporují pro každou konverzaci chatu jenom jeden obrázek a v kontextu se zachová jenom poslední obrázek. Pokud přidáte více obrázků, dojde k chybě.
Pokud chcete tuto funkci zobrazit, stáhněte si obrázek a zakódujte informace jako base64 řetězec. Výsledná data by měla být uvnitř adresy URL dat:
string imageUrl = "https://news.microsoft.com/source/wp-content/uploads/2024/04/The-Phi-3-small-language-models-with-big-potential-1-1900x1069.jpg";
string imageFormat = "jpeg";
HttpClient httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("User-Agent", "Mozilla/5.0");
byte[] imageBytes = httpClient.GetByteArrayAsync(imageUrl).Result;
string imageBase64 = Convert.ToBase64String(imageBytes);
string dataUrl = $"data:image/{imageFormat};base64,{imageBase64}";
Vizualizace obrázku:
Teď vytvořte žádost o dokončení chatu s obrázkem:
ChatCompletionsOptions requestOptions = new ChatCompletionsOptions()
{
Messages = {
new ChatRequestSystemMessage("You are an AI assistant that helps people find information."),
new ChatRequestUserMessage([
new ChatMessageTextContentItem("Which conclusion can be extracted from the following chart?"),
new ChatMessageImageContentItem(new Uri(dataUrl))
]),
},
MaxTokens=2048,
};
var response = client.Complete(requestOptions);
Console.WriteLine(response.Value.Content);
Odpověď je následující, kde vidíte statistiku využití modelu:
Console.WriteLine($"{response.Value.Role}: {response.Value.Content}");
Console.WriteLine($"Model: {response.Value.Model}");
Console.WriteLine("Usage:");
Console.WriteLine($"\tPrompt tokens: {response.Value.Usage.PromptTokens}");
Console.WriteLine($"\tTotal tokens: {response.Value.Usage.TotalTokens}");
Console.WriteLine($"\tCompletion tokens: {response.Value.Usage.CompletionTokens}");
ASSISTANT: The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.
Model: mistral-large-2407
Usage:
Prompt tokens: 2380
Completion tokens: 126
Total tokens: 2506
Důležité
Položky označené (Preview) v tomto článku jsou aktuálně ve verzi Public Preview. Tato verze Preview je poskytována bez smlouvy o úrovni služeb a nedoporučujeme ji pro produkční úlohy. Některé funkce se nemusí podporovat nebo mohou mít omezené možnosti. Další informace najdete v dodatečných podmínkách použití pro verze Preview v Microsoft Azure.
Tento článek vysvětluje, jak používat rozhraní API pro dokončování chatu s modely nasazenými do odvozování modelů Azure AI ve službách Azure AI.
Požadavky
Pokud chcete ve své aplikaci používat modely dokončování chatu, potřebujete:
Předplatné Azure. Pokud používáte modely GitHubu, můžete prostředí upgradovat a v procesu vytvořit předplatné Azure. Pokud se jedná o váš případ, přečtěte si upgrade z modelů GitHubu na odvození modelu Azure AI.
Prostředek služeb Azure AI Další informace najdete v tématu Vytvoření prostředku Azure AI Services.
Adresa URL a klíč koncového bodu.
- Nasazení modelu dokončení chatu. Pokud nemáte možnost Přidat a nakonfigurovat modely do služeb Azure AI a přidat do prostředku model dokončení chatu.
Použití dokončování chatu
Pokud chcete použít vkládání textu, použijte trasu /chat/completions připojenou k základní adrese URL spolu s přihlašovacími údaji uvedenými v api-key.
Authorization záhlaví je podporováno také ve formátu Bearer <key>.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
api-key: <key>
Pokud jste nakonfigurovali prostředek s podporou Microsoft Entra ID , předejte token v Authorization hlavičce:
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Content-Type: application/json
Authorization: Bearer <token>
Vytvoření žádosti o dokončení chatu
Následující příklad ukazuje, jak můžete vytvořit základní požadavek na dokončení chatu do modelu.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
]
}
Poznámka:
Některé modely nepodporují systémové zprávy (role="system"). Když použijete rozhraní API pro odvozování modelu Azure AI, přeloží se systémové zprávy na uživatelské zprávy, což je nejbližší dostupná funkce. Tento překlad se nabízí pro usnadnění, ale je důležité ověřit, že model odpovídá pokynům v systémové zprávě se správnou úrovní spolehlivosti.
Odpověď je následující, kde vidíte statistiku využití modelu:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
usage Zkontrolujte část v odpovědi a podívejte se na počet tokenů použitých pro výzvu, celkový počet vygenerovaných tokenů a počet tokenů použitých k dokončení.
Streamování obsahu
Ve výchozím nastavení rozhraní API pro dokončování vrátí celý vygenerovaný obsah v jedné odpovědi. Pokud generujete dlouhé dokončení, čekání na odpověď může trvat mnoho sekund.
Obsah můžete streamovat , abyste ho získali při generování. Streamování obsahu umožňuje zahájit zpracování dokončení, jakmile bude obsah k dispozici. Tento režim vrátí objekt, který streamuje odpověď zpět jako události odesílané pouze serverem. Extrahujte bloky dat z rozdílového pole, nikoli z pole zprávy.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"stream": true,
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Můžete vizualizovat, jak streamování generuje obsah:
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": ""
},
"finish_reason": null,
"logprobs": null
}
]
}
Poslední zpráva ve streamu je nastavená finish_reason , což označuje důvod zastavení procesu generování.
{
"id": "23b54589eba14564ad8a2e6978775a39",
"object": "chat.completion.chunk",
"created": 1718726371,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"delta": {
"content": ""
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Prozkoumání dalších parametrů podporovaných klientem odvozováním
Prozkoumejte další parametry, které můžete zadat v klientovi odvození. Úplný seznam všech podporovaných parametrů a jejich odpovídající dokumentace najdete v referenčních informacích k rozhraní API pro odvozování modelů Azure AI.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"presence_penalty": 0.1,
"frequency_penalty": 0.8,
"max_tokens": 2048,
"stop": ["<|endoftext|>"],
"temperature" :0,
"top_p": 1,
"response_format": { "type": "text" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "As of now, it's estimated that there are about 7,000 languages spoken around the world. However, this number can vary as some languages become extinct and new ones develop. It's also important to note that the number of speakers can greatly vary between languages, with some having millions of speakers and others only a few hundred.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 19,
"total_tokens": 91,
"completion_tokens": 72
}
}
Některé modely nepodporují formátování výstupu JSON. Vždy můžete vyzvat model, aby vygeneroval výstupy JSON. Takové výstupy ale nejsou zaručené jako platné JSON.
Pokud chcete předat parametr, který není v seznamu podporovaných parametrů, můžete ho předat podkladovému modelu pomocí dalších parametrů. Viz Předání dalších parametrů do modelu.
Vytváření výstupů JSON
Některé modely můžou vytvářet výstupy JSON. Nastavte response_format na json_object povolení režimu JSON a zaručte, že zpráva, kterou model vygeneruje, je platný JSON. Model také musíte instruovat, aby vygeneroval JSON sami prostřednictvím systémové nebo uživatelské zprávy. Obsah zprávy může být také částečně oříznut, pokud finish_reason="length", což znamená, že generování překročilo max_tokens nebo že konverzace překročila maximální délku kontextu.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that always generate responses in JSON format, using the following format: { \"answer\": \"response\" }"
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"response_format": { "type": "json_object" }
}
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718727522,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "{\"answer\": \"There are approximately 7,117 living languages in the world today, according to the latest estimates. However, this number can vary as some languages become extinct and others are newly discovered or classified.\"}",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 39,
"total_tokens": 87,
"completion_tokens": 48
}
}
Předání dalších parametrů do modelu
Rozhraní API pro odvozování modelů Azure AI umožňuje předat do modelu další parametry. Následující příklad kódu ukazuje, jak předat další parametr logprobs modelu.
POST https://<resource>.services.ai.azure.com/models/chat/completions?api-version=2024-05-01-preview
Authorization: Bearer <TOKEN>
Content-Type: application/json
extra-parameters: pass-through
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "How many languages are in the world?"
}
],
"logprobs": true
}
Než předáte do rozhraní API pro odvozování modelů Azure AI další parametry, ujistěte se, že váš model tyto dodatečné parametry podporuje. Při provedení požadavku do podkladového modelu se hlavička extra-parameters předá modelu s hodnotou pass-through. Tato hodnota říká koncovému bodu, aby předal do modelu další parametry. Použití dalších parametrů s modelem nezaručuje, že je model dokáže skutečně zpracovat. Přečtěte si dokumentaci k modelu, abyste pochopili, které další parametry jsou podporované.
Použití nástrojů
Některé modely podporují použití nástrojů, které mohou být mimořádným zdrojem, když potřebujete z jazykového modelu přesměrovat konkrétní úlohy a místo toho se spoléhají na deterministický systém nebo dokonce jiný jazykový model. Rozhraní API pro odvozování modelů Azure AI umožňuje definovat nástroje následujícím způsobem.
Následující příklad kódu vytvoří definici nástroje, která dokáže hledat z informací o letu ze dvou různých měst.
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
V tomto příkladu výstup funkce spočívá v tom, že pro vybranou trasu nejsou k dispozici žádné lety, ale uživatel by měl zvážit pořízení vlaku.
Poznámka:
Modely cohere vyžadují, aby odpovědi nástroje byly platným obsahem JSON formátovaným jako řetězec. Při vytváření zpráv typu Tool se ujistěte, že odpověď je platný řetězec JSON.
Vyzvat model k rezervaci letů pomocí této funkce:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters": {
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": [
"origin_city",
"destination_city"
]
}
}
}
]
}
Můžete zkontrolovat odpověď a zjistit, jestli je potřeba nástroj volat. Zkontrolujte důvod dokončení a zjistěte, jestli se má nástroj volat. Mějte na paměti, že lze určit více typů nástrojů. Tento příklad ukazuje nástroj typu function.
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726007,
"model": "mistral-large-2407",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0dF1gh",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
"finish_reason": "tool_calls",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 190,
"total_tokens": 226,
"completion_tokens": 36
}
}
Pokud chcete pokračovat, připojte tuto zprávu do historie chatu:
Teď je čas volat příslušnou funkci pro zpracování volání nástroje. Následující fragment kódu iteruje přes všechna volání nástroje uvedená v odpovědi a volá odpovídající funkci s příslušnými parametry. Odpověď je také připojena k historii chatu.
Zobrazte odpověď z modelu:
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant that help users to find information about traveling, how to get to places and the different transportations options. You care about the environment and you always have that in mind when answering inqueries"
},
{
"role": "user",
"content": "When is the next flight from Miami to Seattle?"
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "abc0DeFgH",
"type": "function",
"function": {
"name": "get_flight_info",
"arguments": "{\"origin_city\": \"Miami\", \"destination_city\": \"Seattle\"}",
"call_id": null
}
}
]
},
{
"role": "tool",
"content": "{ \"info\": \"There are no flights available from Miami to Seattle. You should take a train, specially if it helps to reduce CO2 emissions.\" }",
"tool_call_id": "abc0DeFgH"
}
],
"tool_choice": "auto",
"tools": [
{
"type": "function",
"function": {
"name": "get_flight_info",
"description": "Returns information about the next flight between two cities. This includes the name of the airline, flight number and the date and time of the next flight",
"parameters":{
"type": "object",
"properties": {
"origin_city": {
"type": "string",
"description": "The name of the city where the flight originates"
},
"destination_city": {
"type": "string",
"description": "The flight destination city"
}
},
"required": ["origin_city", "destination_city"]
}
}
}
]
}
Použití bezpečnosti obsahu
Rozhraní API pro odvozování modelů Azure AI podporuje bezpečnost obsahu Azure AI. Když používáte nasazení se zapnutou bezpečností obsahu Azure AI, vstupy a výstupy procházejí sadou klasifikačních modelů určených k detekci a zabránění výstupu škodlivého obsahu. Systém filtrování obsahu zjistí a provede akce s konkrétními kategoriemi potenciálně škodlivého obsahu ve vstupních výzev i dokončení výstupu.
Následující příklad ukazuje, jak zpracovat události, když model zjistí škodlivý obsah ve vstupní výzvě a bezpečnost obsahu je povolen.
{
"model": "mistral-large-2407",
"messages": [
{
"role": "system",
"content": "You are an AI assistant that helps people find information."
},
{
"role": "user",
"content": "Chopping tomatoes and cutting them into cubes or wedges are great ways to practice your knife skills."
}
]
}
{
"error": {
"message": "The response was filtered due to the prompt triggering Microsoft's content management policy. Please modify your prompt and retry.",
"type": null,
"param": "prompt",
"code": "content_filter",
"status": 400
}
}
Tip
Další informace o tom, jak nakonfigurovat a řídit nastavení zabezpečení obsahu Azure AI, najdete v dokumentaci k zabezpečení obsahu Azure AI.
Použití dokončování chatu s obrázky
Některé modely můžou zdůvodnět text a obrázky a generovat dokončování textu na základě obou typů vstupu. V této části prozkoumáte možnosti některých modelů pro vizi způsobem chatu:
Důležité
Některé modely podporují pro každou konverzaci chatu jenom jeden obrázek a v kontextu se zachová jenom poslední obrázek. Pokud přidáte více obrázků, dojde k chybě.
Pokud chcete tuto funkci zobrazit, stáhněte si obrázek a zakódujte informace jako base64 řetězec. Výsledná data by měla být uvnitř adresy URL dat:
Tip
Budete muset vytvořit adresu URL dat pomocí skriptování nebo programovacího jazyka. Tento kurz používá tento ukázkový obrázek ve formátu JPEG. Adresa URL dat má následující formát: data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ....
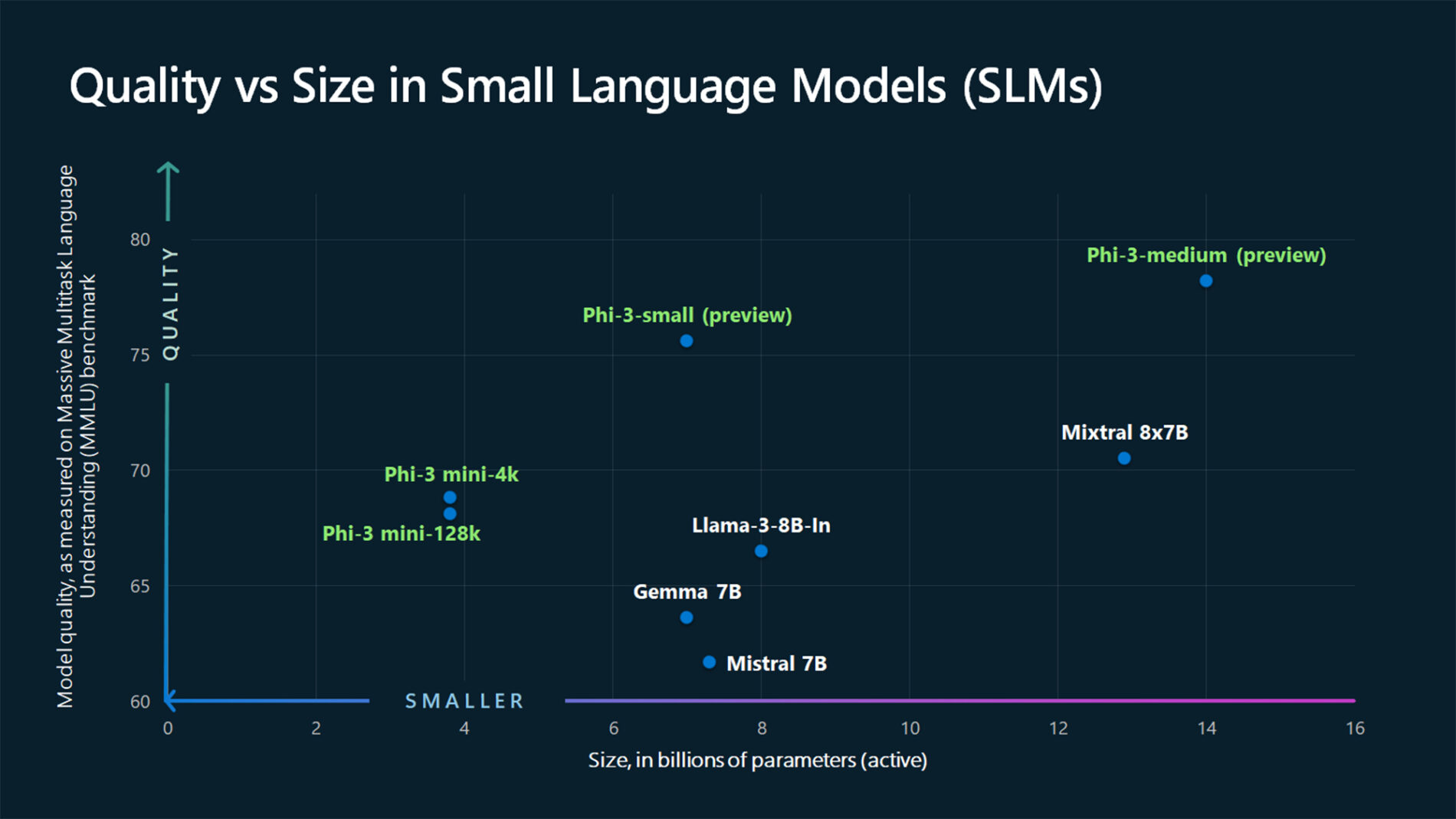{kind=link}
Vizualizace obrázku:
Teď vytvořte žádost o dokončení chatu s obrázkem:
{
"model": "phi-3.5-vision-instruct",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which peculiar conclusion about LLMs and SLMs can be extracted from the following chart?"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpg;base64,0xABCDFGHIJKLMNOPQRSTUVWXYZ..."
}
}
]
}
],
"temperature": 0,
"top_p": 1,
"max_tokens": 2048
}
Odpověď je následující, kde vidíte statistiku využití modelu:
{
"id": "0a1234b5de6789f01gh2i345j6789klm",
"object": "chat.completion",
"created": 1718726686,
"model": "phi-3.5-vision-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "The chart illustrates that larger models tend to perform better in quality, as indicated by their size in billions of parameters. However, there are exceptions to this trend, such as Phi-3-medium and Phi-3-small, which outperform smaller models in quality. This suggests that while larger models generally have an advantage, there might be other factors at play that influence a model's performance.",
"tool_calls": null
},
"finish_reason": "stop",
"logprobs": null
}
],
"usage": {
"prompt_tokens": 2380,
"completion_tokens": 126,
"total_tokens": 2506
}
}