Optimalizace transformací
Následující strategie slouží k optimalizaci výkonu transformací při mapování toků dat v kanálech Azure Data Factory a Azure Synapse Analytics.
Optimalizace spojení, existence a vyhledávání
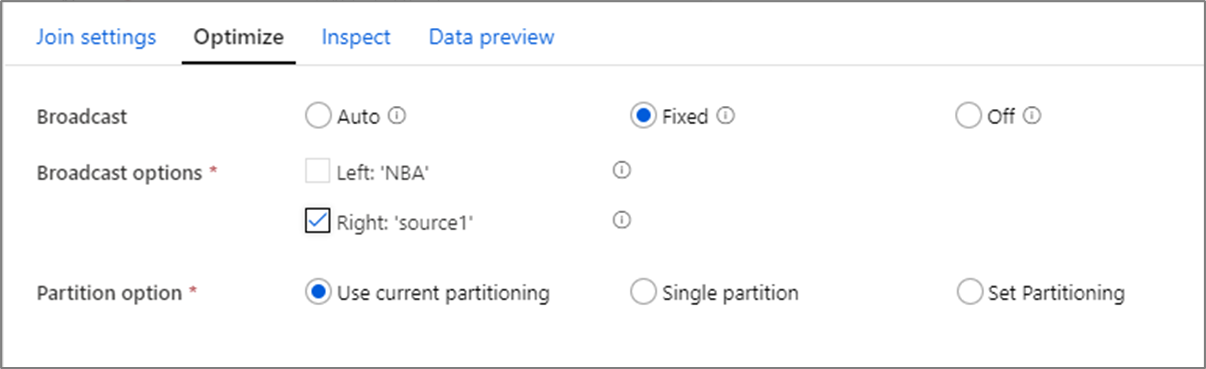
Vysílání
Ve spojeních, vyhledáváních a existuje transformace, pokud jeden nebo oba datové proudy jsou dostatečně malé, aby se vešly do paměti pracovních uzlů, můžete optimalizovat výkon povolením vysílání. Vysílání je, když odesíláte malé datové rámce do všech uzlů v clusteru. Díky tomu může modul Spark provádět spojení bez opětovného zamíchání dat ve velkém datovém proudu. Ve výchozím nastavení modul Spark automaticky rozhodne, zda má vysílat jednu stranu spojení. Pokud znáte příchozí data a víte, že jeden datový proud je menší než druhý, můžete vybrat Pevné vysílání. Pevné vysílání vynutí Spark, aby vysílal vybraný datový proud.
Pokud je velikost vysílaných dat pro uzel Spark příliš velká, může dojít k chybě nedostatku paměti. Abyste se vyhnuli chybám nedostatku paměti, použijte clustery optimalizované pro paměť. Pokud během provádění toku dat zaznamenáte vypršení časových limitů vysílání, můžete optimalizaci vysílání vypnout. Výsledkem je ale pomalejší provádění toků dat.
Při práci se zdroji dat, které můžou dotazovat delší dobu, jako jsou velké databázové dotazy, se doporučuje vypnout vysílání pro připojení. Zdroj s dlouhými dobami dotazu může způsobit vypršení časového limitu Sparku, když se cluster pokusí vysílat do výpočetních uzlů. Další dobrou volbou pro vypnutí všesměrového vysílání je, když máte datový proud ve svém toku dat, který agreguje hodnoty pro pozdější použití ve vyhledávací transformaci. Tento model může zmást optimalizátor Sparku a způsobit vypršení časových limitů.
Křížové spojení
Pokud v podmínkách spojení používáte hodnoty literálů nebo máte na obou stranách spojení více shod, Spark spojení spustí jako křížové spojení. Křížové spojení je úplný kartézský produkt, který pak vyfiltruje spojené hodnoty. To je pomalejší než jiné typy spojení. Ujistěte se, že máte odkazy na sloupce na obou stranách podmínek spojení, abyste se vyhnuli dopadu na výkon.
Řazení před spojením
Na rozdíl od sloučení spojení v nástrojích, jako je SSIS, transformace spojení není povinná operace sloučení spojení. Klíče spojení nevyžadují řazení před transformací. Použití transformací řazení v mapování toků dat se nedoporučuje.
Výkon transformace oken
Transformace okna při mapování toku dat rozdělí data podle hodnoty ve sloupcích, které vyberete jako součást over() klauzule v nastavení transformace. Existuje mnoho oblíbených agregačních a analytických funkcí, které jsou vystaveny v transformaci Windows. Pokud je však vaším případem použití vygenerovat okno nad celou datovou sadou pro řazení rank() nebo číslo rowNumber()řádku, doporučujeme místo toho použít transformaci pořadí a transformaci náhradního klíče. Tyto transformace provádějí lépe úplné operace datových sad pomocí těchto funkcí.
Změna rozdělení nerovnoměrných dat
Některé transformace, jako jsou spojení a agregace, se znovu prohodí vaše datové oddíly a někdy můžou vést ke nerovnoměrné distribuci dat. Nerovnoměrná data znamenají, že data nejsou rovnoměrně rozdělená mezi oddíly. Silně nerovnoměrná data můžou vést k pomalejším podřízeným transformacím a zápisům jímky. Kliknutím na transformaci v zobrazení monitorování můžete zkontrolovat nerovnoměrnou distribuci dat v jakémkoli okamžiku spuštění toku dat.
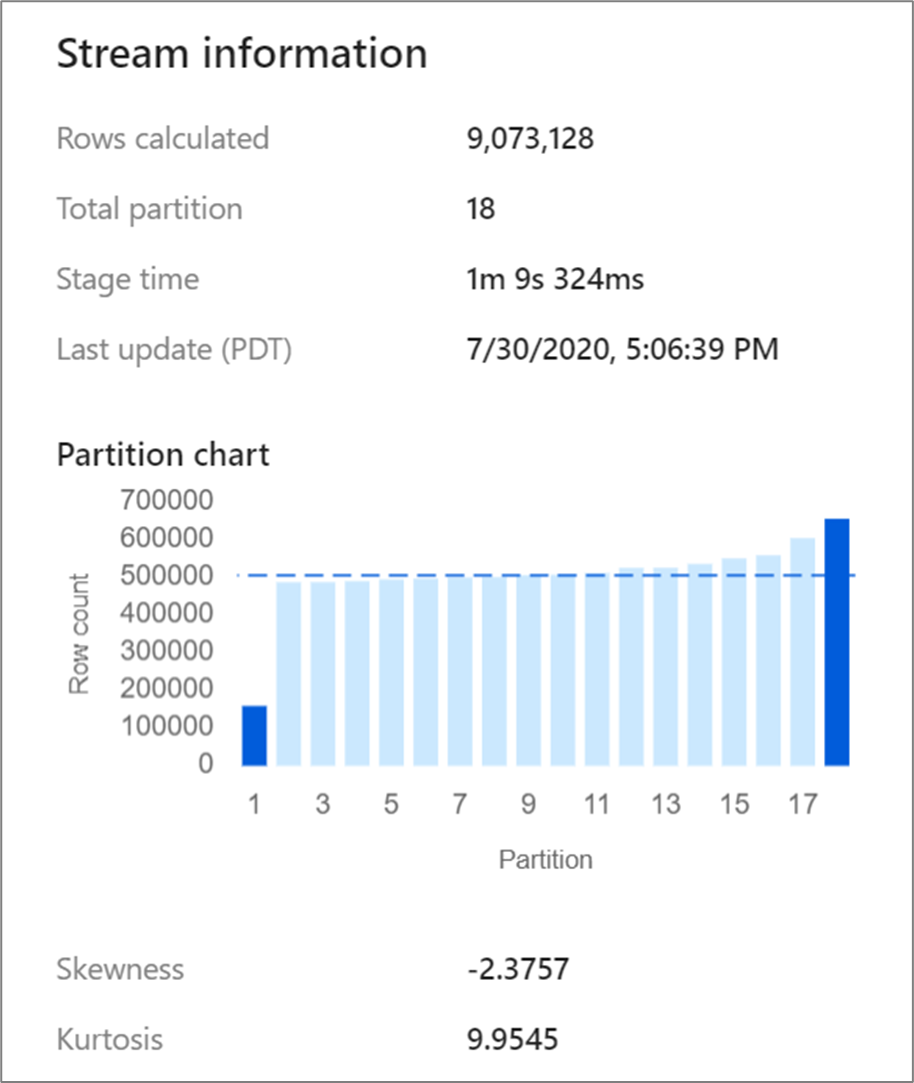
Zobrazení monitorování ukazuje, jak se data distribuují napříč jednotlivými oddíly spolu se dvěma metrikami, zkoseností a kurtózou. Nerovnoměrná distribuce je míra, jak asymetrická data jsou a můžou mít kladnou, nulovou, zápornou nebo nedefinovanou hodnotu. Záporná nerovnoměrná distribuce znamená, že levý ocas je delší než pravý. Kurtóza je míra, zda jsou data těžká nebo světlá. Vysoké kurtózy hodnoty nejsou žádoucí. Ideální rozsahy šikmosti leží mezi -3 a 3 a rozsahy kurtózy jsou menší než 10. Jednoduchý způsob, jak tato čísla interpretovat, je zobrazení grafu oddílů a zobrazení, jestli je 1 pruh větší než zbytek.
Pokud vaše data nejsou rovnoměrně rozdělená po transformaci, můžete k opětovnému rozdělení použít kartu optimalizace. Opětovné zamíchání dat nějakou dobu trvá a nemusí zlepšit výkon toku dat.
Tip
Pokud data znovu rozdělíte, ale máte podřízené transformace, které znovu prohodí vaše data, použijte dělení hash ve sloupci použitém jako spojovací klíč.
Poznámka:
Transformace uvnitř toku dat (s výjimkou transformace jímky) neupravují neaktivní uložená data v souboru a složce. Dělení v každé transformaci znovu rozděluje data uvnitř datových rámců dočasného bezserverového clusteru Spark, který ADF spravuje pro každé spuštění toku dat.
Související obsah
Podívejte se na další Tok dat články týkající se výkonu: