Optimalizace zdrojů
Pro každý zdroj s výjimkou Azure SQL Database se doporučuje, abyste jako vybranou hodnotu ponecháli aktuální dělení . Při čtení ze všech ostatních zdrojových systémů toky dat automaticky rozdělují data rovnoměrně na základě velikosti dat. Vytvoří se nový oddíl přibližně pro každých 128 MB dat. S rostoucí velikostí dat se zvyšuje počet oddílů.
Jakékoli vlastní dělení probíhá po načtení Sparku v datech a negativní vliv na výkon toku dat. Vzhledem k tomu, že jsou data rovnoměrně rozdělená na čtení, nedoporučuje se, pokud nejdřív nerozumíte tvaru a kardinalitě dat.
Poznámka:
Rychlost čtení může být omezená propustností zdrojového systému.
Zdroje azure SQL Database
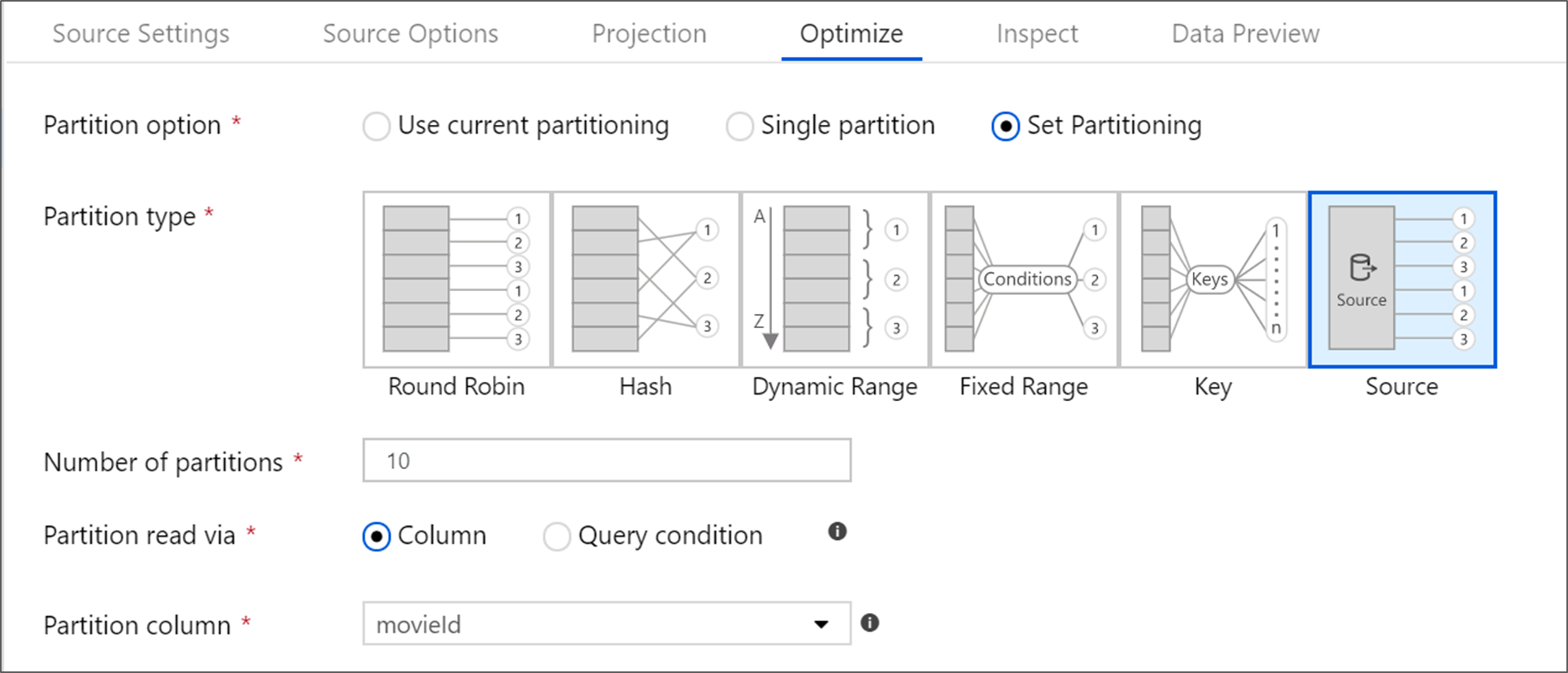
Azure SQL Database má jedinečnou možnost dělení s názvem Zdrojové dělení. Povolením zdrojového dělení můžete zlepšit dobu čtení ze služby Azure SQL Database povolením paralelních připojení ve zdrojovém systému. Zadejte počet oddílů a způsob rozdělení dat. Použijte sloupec oddílu s vysokou kardinalitou. Můžete také zadat dotaz, který odpovídá schématu dělení zdrojové tabulky.
Tip
Pro dělení zdroje je kritickým bodem vstupně-výstupní operace SQL Serveru. Přidání příliš velkého počtu oddílů může nasytit zdrojová databáze. Při použití této možnosti jsou obecně ideální čtyři nebo pět oddílů.
Úroveň izolace
Úroveň izolace čtení zdrojového systému Azure SQL ovlivňuje výkon. Výběr možnosti Číst nepotvrzené poskytuje nejrychlejší výkon a zabraňuje všem zámkům databáze. Další informace o úrovních izolace SQL najdete v tématu Vysvětlení úrovní izolace.
Čtení pomocí dotazu
Ze služby Azure SQL Database můžete číst pomocí tabulky nebo dotazu SQL. Pokud spouštíte dotaz SQL, musí se dotaz před zahájením transformace dokončit. Dotazy SQL můžou být užitečné při odesílání operací, které mohou být rychlejší a snižují množství dat načtených z SQL Serveru, jako jsou příkazy SELECT, WHERE a JOIN. Při odsílání operací ztratíte možnost sledovat rodokmen a výkon transformací před tím, než data přicházejí do toku dat.
Zdroje Azure Synapse Analytics
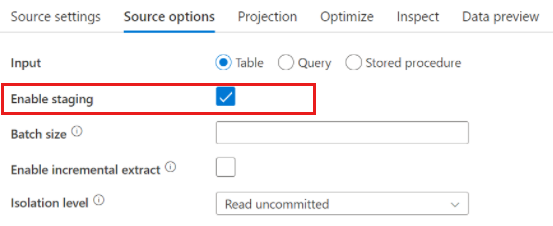
Pokud používáte Azure Synapse Analytics, ve zdrojových možnostech existuje nastavení s názvem Povolit přípravu . To umožňuje službě číst ze synapse pomocí Staging, což výrazně zlepšuje výkon čtení pomocí nejvýkonnější funkce hromadného načítání, jako je CETAS a COPY příkaz. Povolení Staging vyžaduje, abyste v nastavení aktivity toku dat zadali pracovní umístění Azure Blob Storage nebo Azure Data Lake Storage Gen2.
Zdroje založené na souborech
Parquet versus text s oddělovači
I když toky dat podporují různé typy souborů, pro optimální dobu čtení a zápisu se doporučuje nativní formát Parquet pro Spark.
Pokud používáte stejný tok dat na sadě souborů, doporučujeme číst ze složky, používat cesty se zástupnými znaky nebo číst ze seznamu souborů. Spuštění jedné aktivity toku dat může zpracovávat všechny vaše soubory v dávce. Další informace o konfiguraci těchto nastavení najdete v části Zdrojová transformace v dokumentaci ke konektoru Azure Blob Storage.
Pokud je to možné, nepoužívejte aktivitu For-Each ke spouštění toků dat přes sadu souborů. To způsobí, že každá iterace for-each se spouští ve vlastním clusteru Spark, který často není nutný a může být nákladný.
Vložené datové sady vs. sdílené datové sady
Datové sady ADF a Synapse jsou sdílené prostředky ve vašich továrnách a pracovních prostorech. Při čtení velkého počtu zdrojových složek a souborů s textem s oddělovači a zdroji JSON ale můžete zlepšit výkon zjišťování souborů toku dat nastavením možnosti "Projektované schéma uživatele" uvnitř projekce | Dialogové okno Možnosti schématu Tato možnost vypne výchozí automatické zjišťování schématu ADF a výrazně zlepšuje výkon zjišťování souborů. Před nastavením této možnosti nezapomeňte naimportovat projekci, aby služba ADF má existující schéma pro projekci. Tato možnost nefunguje s posunem schématu.
Související obsah
Podívejte se na další Tok dat články týkající se výkonu: