Použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark ve službě HDInsight prostřednictvím sítě VPN
Doporučujeme vzdáleně ladit aplikace Apache Spark přes SSH. Pokyny najdete v tématu Vzdálené ladění aplikací Apache Spark v clusteru HDInsight pomocí sady Azure Toolkit for IntelliJ prostřednictvím SSH.
Tento článek obsahuje podrobné pokyny k tomu, jak pomocí nástrojů HDInsight v sadě Azure Toolkit for IntelliJ odeslat úlohu Sparku v clusteru HDInsight Spark a pak ji vzdáleně ladit z počítače. Pokud chcete tyto úlohy dokončit, musíte provést následující základní kroky:
- Vytvořte virtuální síť Azure typu site-to-site nebo point-to-site. Kroky v tomto dokumentu předpokládají, že používáte síť typu site-to-site.
- Vytvořte cluster Spark ve službě HDInsight, který je součástí virtuální sítě site-to-site.
- Ověřte připojení mezi hlavním uzlem clusteru a počítačem.
- Vytvořte aplikaci Scala v IntelliJ IDEA a nakonfigurujte ji pro vzdálené ladění.
- Spusťte a ladit aplikaci.
Požadavky
- Předplatné Azure. Další informace najdete v tématu Získání bezplatné zkušební verze Azure.
- Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
- Sada Oracle Java Development Kit. Můžete ho nainstalovat z webu Oracle.
- IntelliJ IDEA Tento článek používá verzi 2017.1. Můžete ho nainstalovat z webu JetBrains.
- Nástroje HDInsight v sadě Azure Toolkit for IntelliJ Nástroje HDInsight pro IntelliJ jsou k dispozici jako součást sady Azure Toolkit for IntelliJ. Pokyny k instalaci sady Azure Toolkit najdete v tématu Instalace sady Azure Toolkit for IntelliJ.
- Přihlaste se ke svému předplatnému Azure z IntelliJ IDEA. Postupujte podle pokynů v tématu Použití sady Azure Toolkit for IntelliJ k vytvoření aplikací Apache Spark pro cluster HDInsight.
- Alternativní řešení výjimek Při spouštění aplikace Spark Scala pro vzdálené ladění na počítači s Windows se může zobrazit výjimka. Tato výjimka je vysvětlena ve SPARK-2356 a dochází k němu kvůli chybějícímu souboru WinUtils.exe ve Windows. Chcete-li tuto chybu obejít, musíte stáhnout Winutils.exe do umístění, jako je C:\WinUtils\bin. Přidejte HADOOP_HOME proměnnou prostředí a pak nastavte hodnotu proměnné na C\WinUtils.
Krok 1: Vytvoření virtuální sítě Azure
Podle pokynů z následujících odkazů vytvořte virtuální síť Azure a ověřte připojení mezi vaším stolním počítačem a virtuální sítí:
- Vytvoření virtuální sítě s připojením VPN typu site-to-site pomocí webu Azure Portal
- Vytvoření virtuální sítě s připojením VPN typu site-to-site pomocí PowerShellu
- Konfigurace připojení typu point-to-site k virtuální síti pomocí PowerShellu
Krok 2: Vytvoření clusteru HDInsight Spark
Doporučujeme také vytvořit cluster Apache Spark v Azure HDInsight, který je součástí vámi vytvořené virtuální sítě Azure. Použijte informace, které jsou k dispozici v vytváření linuxových clusterů ve službě HDInsight. Jako součást volitelné konfigurace vyberte virtuální síť Azure, kterou jste vytvořili v předchozím kroku.
Krok 3: Ověření připojení mezi hlavním uzlem clusteru a počítačem
Získejte IP adresu hlavního uzlu. Otevřete uživatelské rozhraní Ambari pro cluster. V okně clusteru vyberte Řídicí panel.
V uživatelském rozhraní Ambari vyberte Hostitelé.

Zobrazí se seznam hlavních uzlů, pracovních uzlů a uzlů zookeeper. Hlavní uzly mají předponu hn*. Vyberte první hlavní uzel.
V podokně Souhrn v dolní části stránky, která se otevře, zkopírujte IP adresu hlavního uzlu a název hostitele.
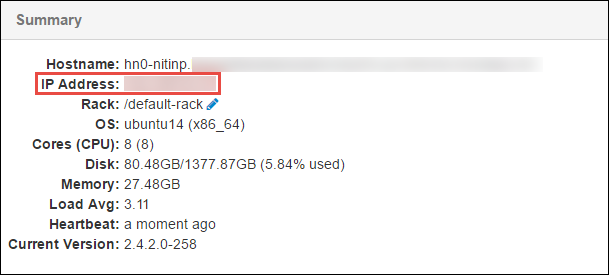
Přidejte IP adresu a název hostitele hlavního uzlu do souboru hostitelů v počítači, na kterém chcete spustit a vzdáleně ladit úlohu Sparku. To vám umožní komunikovat s hlavním uzlem pomocí IP adresy a názvu hostitele.
a. Otevřete soubor Poznámkový blok se zvýšenými oprávněními. V nabídce Soubor vyberte Otevřít a vyhledejte umístění souboru hostitelů. Na počítači s Windows je umístění C:\Windows\System32\Drivers\etc\hosts.
b. Do souboru hostitelů přidejte následující informace:
# For headnode0 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.net # For headnode1 192.xxx.xx.xx nitinp 192.xxx.xx.xx nitinp.lhwwghjkpqejawpqbwcdyp3.gx.internal.cloudapp.netZ počítače, který jste připojili k virtuální síti Azure používané clusterem HDInsight, ověřte, že pomocí IP adresy a názvu hostitele můžete hlavní uzly otestovat příkazem ping.
Pomocí protokolu SSH se připojte k hlavnímu uzlu clusteru podle pokynů v Připojení ke clusteru HDInsight pomocí SSH. Z hlavního uzlu clusteru odešlete příkazem ping IP adresu stolního počítače. Otestujte připojení k oběma IP adresům přiřazeným k počítači:
- Jedno pro síťové připojení
- Jedna pro virtuální síť Azure
Opakujte kroky pro druhý hlavní uzel.
Krok 4: Vytvoření aplikace Apache Spark Scala pomocí nástrojů HDInsight v sadě Azure Toolkit for IntelliJ a jeho konfigurace pro vzdálené ladění
Otevřete IntelliJ IDEA a vytvořte nový projekt. V dialogovém okně New Project (Nový projekt) proveďte následující kroky:
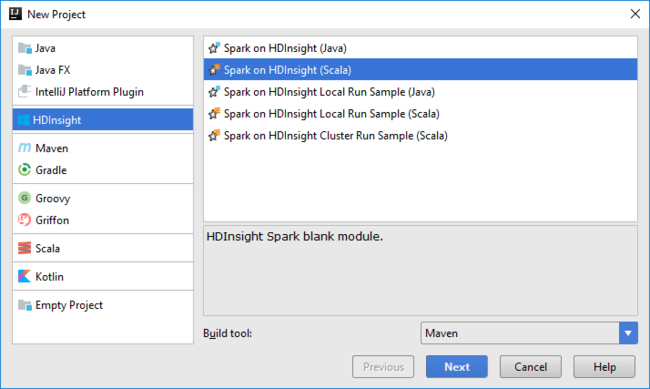
a. Vyberte HDInsight>Spark on HDInsight (Scala) (Spark v HDInsight (Scala)).
b. Vyberte Další.
V dalším dialogovém okně Nový projekt proveďte následující kroky a pak vyberte Dokončit:
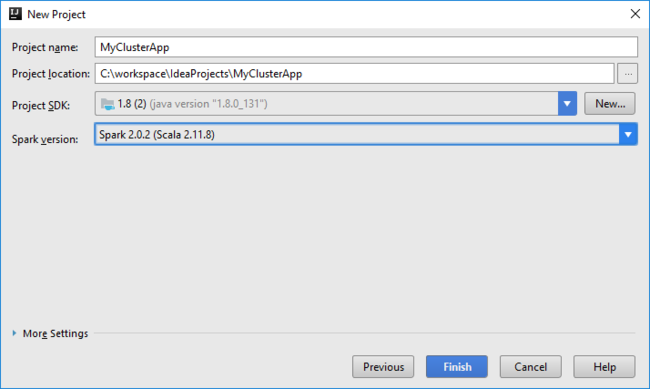
Zadejte název a umístění projektu.
V rozevíracím seznamu Project SDK (SDK projektu) vyberte Java 1.8 pro cluster Spark 2.x, nebo vyberte Java 1.7 pro cluster Spark 1.x.
V rozevíracím seznamu verzí Sparku průvodce vytvořením projektu Scala integruje správnou verzi sady Spark SDK a sady Scala SDK. Pokud je verze clusteru Spark nižší než 2.0, vyberte Spark 1.x. V opačném případě vyberte Spark 2.x. V tomto příkladu se používá Spark 2.0.2 (Scala 2.11.8).
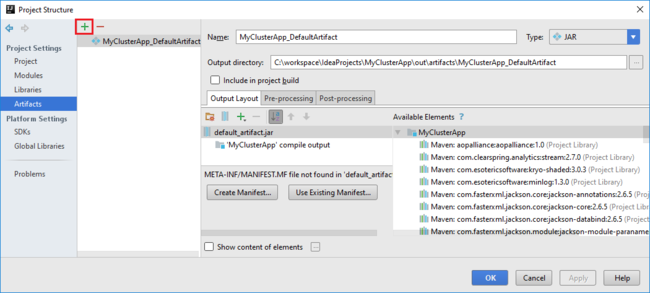
Projekt Spark automaticky vytvoří artefakt za vás. Pokud chcete zobrazit artefakt, postupujte takto:
a. V nabídce File (Soubor) vyberte Project Structure (Struktura projektu).
b. V dialogovém okně Struktura projektu vyberte Artefakty a zobrazte výchozí artefakt, který je vytvořen. Můžete také vytvořit vlastní artefakt výběrem znaménka plus (+).
Přidejte do projektu knihovny. Pokud chcete přidat knihovnu, postupujte takto:
a. Pravým tlačítkem myši klikněte na název projektu ve stromu projektu a pak vyberte Otevřít modul Nastavení.
b. V dialogovém okně Struktura projektu vyberte Knihovny, vyberte symbol (+) a pak vyberte Z Mavenu.
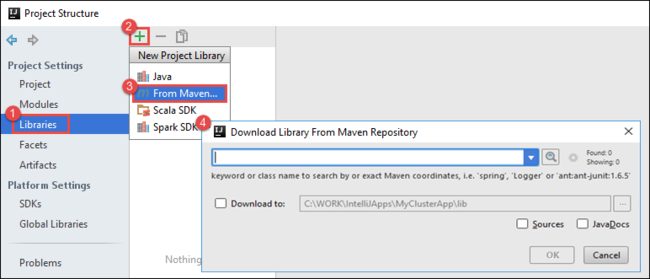
c. V dialogovém okně Stáhnout knihovnu z úložiště Maven vyhledejte a přidejte následující knihovny:
org.scalatest:scalatest_2.10:2.2.1org.apache.hadoop:hadoop-azure:2.7.1
Zkopírujte
yarn-site.xmlhlavní uzel clusteru acore-site.xmlpřidejte je do projektu. Ke zkopírování souborů použijte následující příkazy. Pomocí Cygwinu můžete spustit následujícíscppříkazy ke zkopírování souborů z hlavních uzlů clusteru:scp <ssh user name>@<headnode IP address or host name>://etc/hadoop/conf/core-site.xml .Protože jsme už přidali IP adresu a názvy hostitelů hlavního uzlu clusteru pro soubor hostitelů na ploše, můžeme příkazy použít
scpnásledujícím způsobem:scp sshuser@nitinp:/etc/hadoop/conf/core-site.xml . scp sshuser@nitinp:/etc/hadoop/conf/yarn-site.xml .Pokud chcete tyto soubory přidat do projektu, zkopírujte je do složky /src ve stromu projektu, například
<your project directory>\src.core-site.xmlAktualizujte soubor a proveďte následující změny:a. Nahraďte šifrovaný klíč. Soubor
core-site.xmlobsahuje šifrovaný klíč k účtu úložiště přidruženému ke clusteru.core-site.xmlV souboru, který jste přidali do projektu, nahraďte šifrovaný klíč skutečným klíčem úložiště přidruženým k výchozímu účtu úložiště. Další informace najdete v tématu Správa přístupových klíčů účtu úložiště.<property> <name>fs.azure.account.key.hdistoragecentral.blob.core.windows.net</name> <value>access-key-associated-with-the-account</value> </property>b. Odeberte následující položky z
core-site.xml:<property> <name>fs.azure.account.keyprovider.hdistoragecentral.blob.core.windows.net</name> <value>org.apache.hadoop.fs.azure.ShellDecryptionKeyProvider</value> </property> <property> <name>fs.azure.shellkeyprovider.script</name> <value>/usr/lib/python2.7/dist-packages/hdinsight_common/decrypt.sh</value> </property> <property> <name>net.topology.script.file.name</name> <value>/etc/hadoop/conf/topology_script.py</value> </property>c. Uložte soubor.
Přidejte hlavní třídu pro vaši aplikaci. V Průzkumníku projektů klikněte pravým tlačítkem myši na src, přejděte na příkaz Nový a vyberte Třídu Scala.
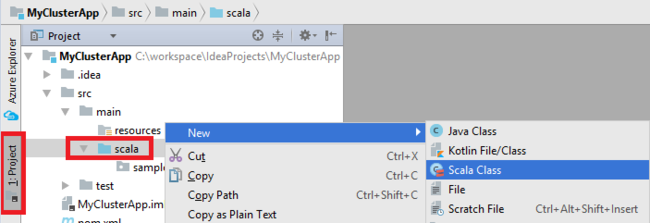
V dialogovém okně Vytvořit novou třídu Scala zadejte název, vyberte v poli Druh objekt a pak vyberte OK.
MyClusterAppMain.scalaDo souboru vložte následující kód. Tento kód vytvoří kontext Sparku a otevře zexecuteJobobjektu metoduSparkSample.import org.apache.spark.{SparkConf, SparkContext} object SparkSampleMain { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("SparkSample") .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Opakováním kroků 8 a 9 přidejte nový objekt Scala s názvem
*SparkSample. Přidejte do této třídy následující kód. Tento kód načte data z HVAC.csv (k dispozici ve všech clusterech HDInsight Spark). Načte řádky, které mají v souboru CSV pouze jednu číslici v sedmém sloupci, a potom zapíše výstup do /HVACOut pod výchozím kontejnerem úložiště clusteru.import org.apache.spark.SparkContext object SparkSample { def executeJob (sc: SparkContext, input: String, output: String): Unit = { val rdd = sc.textFile(input) //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) val s = sc.parallelize(rdd.take(5)).cartesian(rdd).count() println(s) rdd1.saveAsTextFile(output) //rdd1.collect().foreach(println) } }Opakováním kroků 8 a 9 přidejte novou třídu s názvem
RemoteClusterDebugging. Tato třída implementuje testovací architekturu Sparku, která se používá k ladění aplikací. Do třídy přidejte následující kódRemoteClusterDebugging:import org.apache.spark.{SparkConf, SparkContext} import org.scalatest.FunSuite class RemoteClusterDebugging extends FunSuite { test("Remote run") { val conf = new SparkConf().setAppName("SparkSample") .setMaster("yarn-client") .set("spark.yarn.am.extraJavaOptions", "-Dhdp.version=2.4") .set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar") .setJars(Seq("""C:\workspace\IdeaProjects\MyClusterApp\out\artifacts\MyClusterApp_DefaultArtifact\default_artifact.jar""")) .set("spark.hadoop.validateOutputSpecs", "false") val sc = new SparkContext(conf) SparkSample.executeJob(sc, "wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv", "wasb:///HVACOut") } }Je potřeba si uvědomit několik důležitých věcí:
- Ujistěte
.set("spark.yarn.jar", "wasb:///hdp/apps/2.4.2.0-258/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar")se, že je jar sestavení Sparku k dispozici v úložišti clusteru v zadané cestě. - Zadejte
setJarsumístění, kde se vytvoří soubor JAR artefaktu. Obvykle je<Your IntelliJ project directory>\out\<project name>_DefaultArtifact\default_artifact.jarto .
- Ujistěte
*RemoteClusterDebuggingVe třídě klikněte pravým tlačítkem myši natestklíčové slovo a pak vyberte Vytvořit konfiguraci vzdáleného ladění.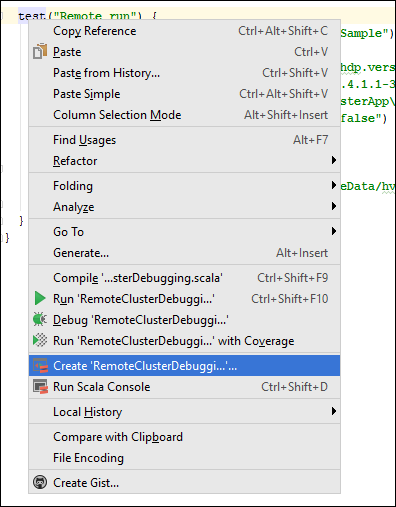
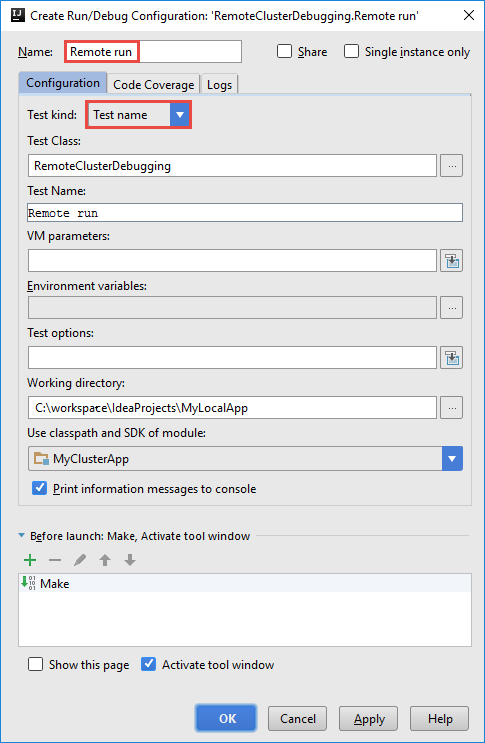
V dialogovém okně Vytvořit konfiguraci vzdáleného ladění zadejte název konfigurace a jako název testu vyberte Typ testu. Ponechte všechny ostatní hodnoty jako výchozí nastavení. Vyberte Apply (Použít) a pak vyberte OK.
V řádku nabídek by se teď měl zobrazit rozevírací seznam konfigurace vzdáleného spuštění .

Krok 5: Spuštění aplikace v režimu ladění
V projektu IntelliJ IDEA otevřete
SparkSample.scalaa vytvořte zarážku vedleval rdd1. V místní nabídce Vytvořit zarážku vyberte řádek ve funkci executeJob.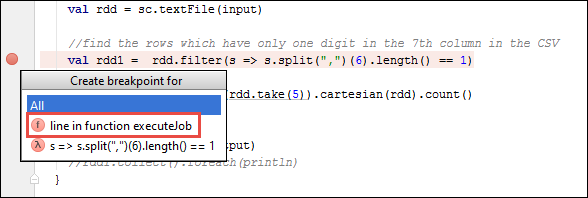
Pokud chcete aplikaci spustit, vyberte tlačítko Spustit ladění vedle rozevíracího seznamu Konfigurace vzdáleného spuštění .

Když provádění programu dosáhne zarážky, zobrazí se v dolním podokně karta ladicího programu .
Pokud chcete přidat hodinky, vyberte ikonu (+).
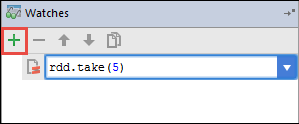
V tomto příkladu se aplikace před vytvořením proměnné
rdd1přerušila. Pomocí tohoto kukátku vidíme prvních pět řádků v proměnnérdd. Stiskněte klávesu Enter.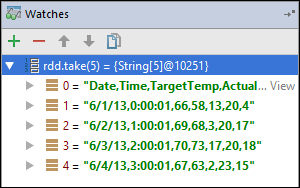
To, co vidíte na předchozím obrázku, je to, že za běhu můžete zadávat dotazy na terabajty dat a ladit průběh aplikace. Například ve výstupu zobrazeném na předchozím obrázku vidíte, že první řádek výstupu je záhlaví. Na základě tohoto výstupu můžete upravit kód aplikace tak, aby v případě potřeby přeskočí řádek záhlaví.
Teď můžete vybrat ikonu Pokračovat v programu a pokračovat ve spuštění aplikace.
Pokud se aplikace úspěšně dokončí, měl by se zobrazit výstup podobný tomuto:
Další kroky
Scénáře
- Apache Spark s BI: Provádění interaktivní analýzy dat pomocí Sparku ve službě HDInsight s nástroji BI
- Apache Spark se strojovým Učení: Použití Sparku v HDInsight k analýze teploty budovy pomocí dat TVK
- Apache Spark se strojovým Učení: Použití Sparku v HDInsight k predikci výsledků kontroly potravin
- Analýza webových protokolů pomocí Apache Sparku ve službě HDInsight
Vytvoření a spouštění aplikací
- Vytvoření samostatné aplikace pomocí Scala
- Vzdálené spouštění úloh v clusteru Apache Spark pomocí Apache Livy
Nástroje a rozšíření
- Použití sady Azure Toolkit for IntelliJ k vytvoření aplikací Apache Spark pro cluster HDInsight
- Použití sady Azure Toolkit for IntelliJ k vzdálenému ladění aplikací Apache Spark prostřednictvím SSH
- Vytváření aplikací Apache Spark pomocí nástrojů HDInsight v sadě Azure Toolkit for Eclipse
- Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě HDInsight
- Jádra dostupná pro Poznámkový blok Jupyter v clusteru Apache Spark pro HDInsight
- Použití externích balíčků s poznámkovými bloky Jupyter
- Instalace Jupyteru do počítače a připojení ke clusteru HDInsight Spark