Použití poznámkových bloků Apache Zeppelin s clusterem Apache Spark ve službě Azure HDInsight
Clustery HDInsight Spark zahrnují poznámkové bloky Apache Zeppelin . Pomocí poznámkových bloků můžete spouštět úlohy Apache Sparku. V tomto článku se dozvíte, jak používat poznámkový blok Zeppelin v clusteru HDInsight.
Požadavky
- Cluster Apache Spark ve službě HDInsight. Pokyny najdete v tématu Vytváření clusterů Apache Spark ve službě Azure HDInsight.
- Schéma identifikátoru URI pro primární úložiště clusterů. Schéma by bylo
wasb://pro Azure Blob Storage,abfs://pro Azure Data Lake Storage Gen2 neboadl://Pro Azure Data Lake Storage Gen1. Pokud je pro Blob Storage povolený zabezpečený přenos, identifikátor URI by bylwasbs://. Další informace najdete v tématu Vyžadování zabezpečeného přenosu ve službě Azure Storage .
Spuštění poznámkového bloku Apache Zeppelin
V přehledu clusteru Spark vyberte poznámkový blok Zeppelin z řídicích panelů clusteru. Zadejte přihlašovací údaje správce clusteru.
Poznámka:
K poznámkovému bloku Zeppelin pro váš cluster se také můžete dostat tak, že v prohlížeči otevřete následující adresu URL. Nahraďte CLUSTERNAME názvem clusteru:
https://CLUSTERNAME.azurehdinsight.net/zeppelinVytvořte nový poznámkový blok. V podokně záhlaví přejděte do poznámkového bloku>Vytvořit novou poznámku.
Zadejte název poznámkového bloku a pak vyberte Vytvořit poznámku.
Ujistěte se, že záhlaví poznámkového bloku zobrazuje stav připojení. Označuje se zelenou tečkou v pravém horním rohu.
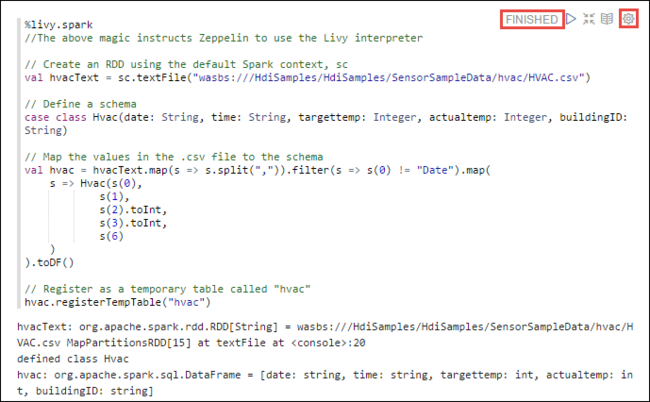
Načtěte vzorová data do dočasné tabulky. Při vytváření clusteru Spark v HDInsight se ukázkový datový soubor
hvac.csvzkopíruje do přidruženého účtu úložiště v části\HdiSamples\SensorSampleData\hvac.Do prázdného odstavce vytvořeného ve výchozím nastavení v novém poznámkovém bloku vložte následující fragment kódu.
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Stiskněte SHIFT+ENTER nebo vyberte tlačítko Přehrát pro odstavec a spusťte fragment kódu. Stav v pravém rohu odstavce by měl pocházet od READY, PENDING, RUNNING to FINISHED. Výstup se zobrazí v dolní části stejného odstavce. Snímek obrazovky vypadá jako na následujícím obrázku:
Můžete také zadat název každého odstavce. V pravém rohu odstavce vyberte ikonu Nastavení (závorka) a pak vyberte Zobrazit název.
Poznámka:
Překladač %spark2 se v poznámkových blocích Zeppelinu nepodporuje ve všech verzích HDInsight a překladač %sh se nepodporuje od HDInsight 4.0 dál.
V tabulce teď můžete spouštět příkazy
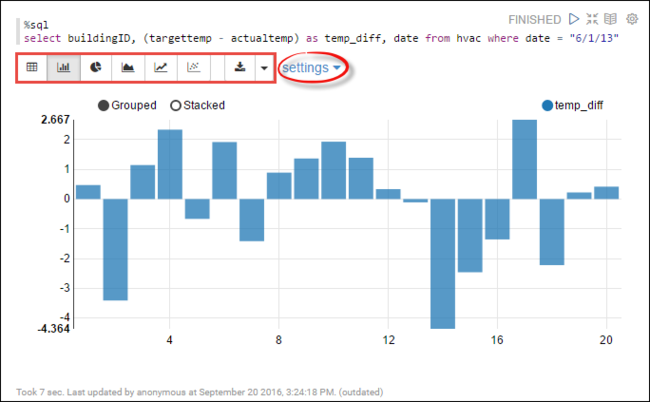
hvacSpark SQL. Do nového odstavce vložte následující dotaz. Dotaz načte ID budovy. Rozdíl mezi cílovým a skutečnými teplotami pro každou budovu v daném datu. Stiskněte SHIFT+ENTER.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Příkaz %sql na začátku říká poznámkovému bloku, aby používal interpret Livy Scala.
Výběrem ikony pruhového grafu změňte zobrazení. po výběru pruhového grafu se zobrazí nastavení, které vám umožní zvolit klíče a hodnoty. Následující snímek obrazovky ukazuje výstup.
Příkazy Spark SQL můžete také spouštět pomocí proměnných v dotazu. Další fragment kódu ukazuje, jak definovat proměnnou , v dotazu s možnými hodnotami,
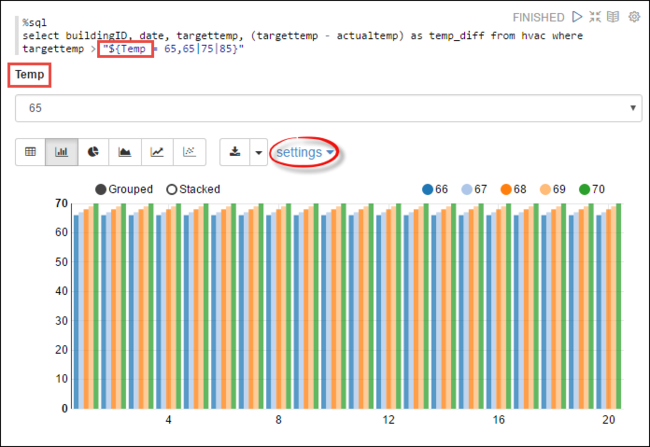
Tempse kterými se chcete dotazovat. Při prvním spuštění dotazu se automaticky vyplní rozevírací seznam hodnotami, které jste zadali pro proměnnou.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Vložte tento fragment kódu do nového odstavce a stiskněte SHIFT+ENTER. V rozevíracím seznamu Temp vyberte hodnotu 65.
Výběrem ikony pruhového grafu změňte zobrazení. Pak vyberte nastavení a proveďte následující změny:
Skupiny: Přidejte targettemp.
Hodnoty: 1. Odebrat datum. 2. Přidejte temp_diff. 3. Změňte agregátor ze sumy na AVG.
Následující snímek obrazovky ukazuje výstup.
Návody používat externí balíčky s poznámkovým blokem?
Poznámkový blok Zeppelin v clusteru Apache Spark ve službě HDInsight může používat externí balíčky, které nejsou součástí clusteru. V úložišti Maven vyhledejte úplný seznam dostupných balíčků. Můžete také získat seznam dostupných balíčků z jiných zdrojů. Úplný seznam balíčků, které přispěli komunitou, je například k dispozici ve Spark Packages.
V tomto článku se dozvíte, jak používat balíček spark-csv s poznámkovým blokem Jupyter.
Otevřete nastavení interpreta. V pravém horním rohu vyberte přihlášené uživatelské jméno a pak vyberte Interpret.
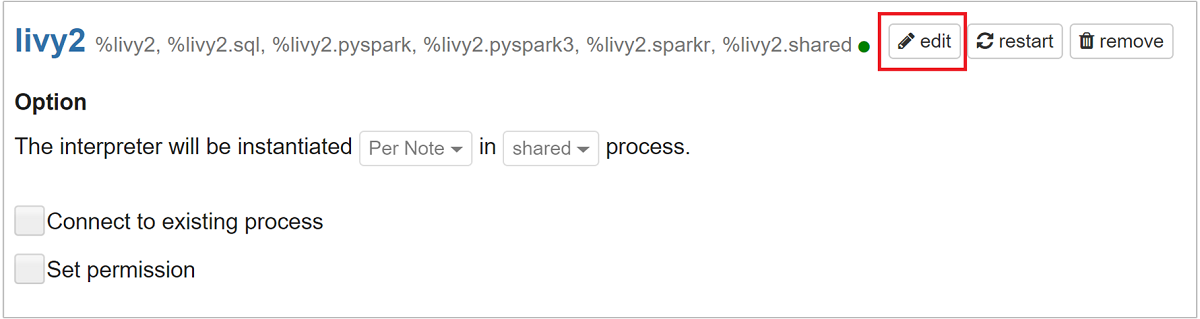
Přejděte na livy2 a vyberte upravit.
Přejděte na klíč
livy.spark.jars.packagesa nastavte jeho hodnotu ve formátugroup:id:version. Pokud tedy chcete použít balíček spark-csv , musíte nastavit hodnotu klíče nacom.databricks:spark-csv_2.10:1.4.0.
Výběrem možnosti Uložit a pak OK restartujte interpret Livy.
Pokud chcete pochopit, jak získat hodnotu zadaného klíče, tady je postup.
a. Vyhledejte balíček v úložišti Maven. V tomto článku jsme použili spark-csv.
b. Z úložiště shromážděte hodnoty GroupId, ArtifactId a Version.
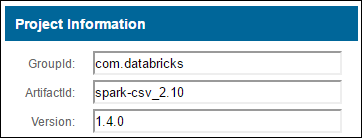
c. Zřetězení tří hodnot oddělených dvojtečkam (:).
com.databricks:spark-csv_2.10:1.4.0
Kde jsou uložené poznámkové bloky Zeppelin?
Poznámkové bloky Zeppelin uložené v hlavních uzlech clusteru. Pokud tedy cluster odstraníte, poznámkové bloky se odstraní i. Pokud chcete zachovat poznámkové bloky pro pozdější použití v jiných clusterech, musíte je po dokončení spuštění úloh exportovat. Pokud chcete exportovat poznámkový blok, vyberte ikonu Exportovat , jak je znázorněno na obrázku následujícím způsobem.
Tato akce uloží poznámkový blok jako soubor JSON do umístění pro stažení.
Poznámka:
V HDI 4.0 je cesta k adresáři poznámkového bloku zeppelin
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Např. /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
vzhledem k tomu, že v HDI 5.0 a tato cesta se liší
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Např. /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Uložený název souboru se liší v HDI 5.0. Uloží se jako
<notebook_name>_<sessionid>.zplnNapř. testzeppelin_2JJK53XQA.zpln
V HDI 4.0 je název souboru pouze note.json uložen v adresáři session_id.
Např. /2JMC9BZ8X/note.json
HDI Zeppelin vždy ukládá poznámkový blok do cesty
/usr/hdp/<version>/zeppelin/notebook/na místním disku hn0.Pokud chcete, aby byl poznámkový blok dostupný i po odstranění clusteru, můžete zkusit použít úložiště souborů Azure (pomocí protokolu SMB) a propojit ho s místní cestou. Další informace najdete v tématu Připojení sdílené složky Azure SMB v Linuxu.
Po jeho připojení můžete upravit konfiguraci zeppelin zeppelin.notebook.dir na připojenou cestu v uživatelském rozhraní Ambari.
- Sdílené složky SMB jako úložiště GitNotebookRepo se nedoporučuje pro zeppelin verze 0.10.1.
Konfigurace Shiro přístupu k interpretům Zeppelin v clusterech ENTERPRISE Security Package (ESP)
Jak je uvedeno výše, %sh interpret není podporován ve službě HDInsight 4.0 dále. Vzhledem k tomu, že %sh interpret zavádí potenciální problémy se zabezpečením, jako jsou například přístupové klávesové zkratky pomocí příkazů prostředí, byl odebrán také z clusterů ESP SLUŽBY HDInsight 3.6. Znamená to, že %sh interpret není ve výchozím nastavení dostupný při kliknutí na Vytvořit novou poznámku nebo v uživatelském rozhraní interpreta.
Uživatelé privilegované domény můžou soubor použít Shiro.ini k řízení přístupu k uživatelskému rozhraní interpreta. Pouze tito uživatelé mohou vytvářet nové %sh interprety a nastavovat oprávnění pro každý nový %sh interpret. Pokud chcete řídit přístup pomocí shiro.ini souboru, postupujte takto:
Definujte novou roli pomocí existujícího názvu skupiny domén. V následujícím příkladu
adminGroupNameje skupina privilegovaných uživatelů v ID Microsoft Entra. V názvu skupiny nepoužívejte speciální znaky ani prázdné znaky. Znaky po=udělení oprávnění pro tuto roli.*znamená, že skupina má úplná oprávnění.[roles] adminGroupName = *Přidejte novou roli pro přístup k interpretům Zeppelinu. V následujícím příkladu mají všichni uživatelé
adminGroupNamepřístup k interpretům Zeppelin a mohou vytvářet nové interprety. Mezi hranaté závorky můžete umístit několik rolí oddělenýchroles[]čárkami. Uživatelé, kteří mají potřebná oprávnění, pak mají přístup k interpretům Zeppelinu.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Příklad shiro.ini pro více skupin domén:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Správa relací Livy
První odstavec kódu v poznámkovém bloku Zeppelin vytvoří novou relaci Livy ve vašem clusteru. Tato relace se sdílí ve všech poznámkových blocích Zeppelin, které vytvoříte později. Pokud se relace Livy z nějakého důvodu ukončí, úlohy se nespustí z poznámkového bloku Zeppelin.
V takovém případě musíte před spuštěním úloh z poznámkového bloku Zeppelin provést následující kroky.
Restartujte interpret Livy z poznámkového bloku Zeppelin. Uděláte to tak, že v pravém horním rohu vyberete přihlášené uživatelské jméno a pak vyberete Interpret.
Přejděte na livy2 a vyberte restartovat.
Spusťte buňku kódu z existujícího poznámkového bloku Zeppelin. Tento kód vytvoří novou relaci Livy v clusteru HDInsight.
Obecné informace
Ověření služby
Pokud chcete ověřit službu z Ambari, přejděte na https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary místo, kde clusterNAME je název vašeho clusteru.
Pokud chcete službu ověřit z příkazového řádku, připojte se přes SSH k hlavnímu uzlu. Přepněte uživatele na zeppelin pomocí příkazu sudo su zeppelin. Příkazy stavu:
| Příkaz | Popis |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Stav služby. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Verze služby. |
ps -aux | grep zeppelin |
Identifikace PID |
Umístění protokolu
| Služba | Cesta |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Protokoly serveru | /var/log/zeppelin |
Interpret konfigurace, Shirosite.xml, log4j |
/usr/hdp/current/zeppelin-server/conf nebo /etc/zeppelin/conf |
| Adresář PID | /var/run/zeppelin |
Povolení protokolování ladění
Přejděte na
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summarymísto, kde clusterNAME je název vašeho clusteru.Přejděte na configs>Advanced zeppelin-log4j-properties>log4j_properties_content.
Změnit
log4j.appender.dailyfile.Threshold = INFOnalog4j.appender.dailyfile.Threshold = DEBUG.Přidat
log4j.logger.org.apache.zeppelin.realm=DEBUG.Uložte změny a restartujte službu.