準確地分析 Direct3D API 呼叫 (Direct3D 9)
一旦您擁有功能Microsoft Direct3D 應用程式,而且想要改善其效能,您通常會使用現成的分析工具或一些自定義測量技術來測量執行一或多個應用程式開發介面 (API) 呼叫所需的時間。 如果您已完成這項操作,但取得的時間結果在每次轉譯序列中有所不同,或是您提出的假設不符合實際實驗結果,下列資訊可幫助您了解其中的原因。
此處提供的資訊是以您具備下列知識及經驗的假設為基礎:
- C/C++程序設計
- Direct3D API 程序設計
- 測量 API 時間
- 視頻卡及其軟體驅動程式
- 之前分析經驗中可能難以解釋的結果
精確剖析 Direct3D 是困難的
分析工具會報告每個 API 呼叫所花費的時間量。 這是藉由尋找和調整熱點來提升效能。 有不同類型的分析工具和分析技術。
- 取樣分析工具會閒置大部分時間,在特定間隔覺醒以取樣(或記錄)正在執行中的函式。 它會傳回每個呼叫所花費時間的百分比。 一般而言,取樣分析工具對應用程式而言並不非常侵入性,而且對應用程式的額外負荷影響最小。
- 檢測分析工具會測量呼叫傳回的實際時間。 它需要將起始與結束界定符編譯到應用程式中。 檢測分析工具比取樣分析工具對應用程式更具侵入性。
- 您也可以搭配高效能定時器使用自定義分析技術。 這會產生非常類似於檢測分析工具的結果。
所使用的分析工具或分析技術類型只是產生精確測量挑戰的一部分。
分析提供可協助您預算效能的解答。 例如,假設您知道 API 呼叫平均執行一千個時鐘週期。 您可以判斷有關效能的一些結論,例如:
- 2 GHz CPU(花費 50% 的時間渲染)每秒只能呼叫此 API 100 萬次。
- 若要達到 30 FPS,您不能在每個畫面中呼叫此 API 超過 33,000 次。
- 每個畫面只能轉譯 3.3K 個物件(假設每個物件的轉譯序列有 10 個這些 API 呼叫)。
換句話說,如果每次 API 呼叫有足夠的時間,您可以回答資源分配問題,例如可以互動渲染的基本圖元數目。 但是檢測分析工具傳回的原始數位不會準確地回答預算問題。 這是因為圖形管線有複雜的設計問題,例如需要工作的元件數目、控制元件之間工作流程的處理器數目,以及運行時間中實作的優化策略,以及設計成讓管線更有效率的驅動程式。
每個 API 呼叫都會經過數個元件
每個呼叫都會由數個元件在從應用程式到視訊卡的途中處理。 例如,請考慮下列轉譯序列,其中包含繪製單一三角形的兩個呼叫:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
下列概念圖顯示呼叫必須通過的不同元件。

應用程式會叫用 Direct3D 以控制場景、處理用戶互動,以及決定轉譯的完成方式。 所有這些工作都會在轉譯序列中指定,並透過 Direct3D API 呼叫將其傳送到執行階段。 轉譯順序幾乎與硬體無關(也就是說,API 呼叫與硬體無關,但應用程式知道視頻卡支援的功能)。
運行時間會將這些呼叫轉換成與裝置無關的格式。 運行時間會處理應用程式與驅動程式之間的所有通訊,讓應用程式在多個相容的硬體上執行(視所需的功能而定)。 測量函式呼叫時,檢測分析工具會測量函式執行的時間,以及函式執行並返回所需的時間。 檢測分析工具的其中一個限制是,它可能不包含驅動程式將產生的工作傳送到視頻卡的時間,也不包含處理工作的時間。 換句話說,現成的插裝剖析器無法將與每個函式呼叫相關的所有工作歸因。
軟體驅動程式會使用有關視訊卡的硬體特定知識,將裝置無關的命令轉換成一連串的視訊卡命令。 驅動程式也可以優化傳送至視訊卡的命令順序,以便有效率地在視訊卡上進行轉譯。 這些優化可能會造成分析上的問題,因為實際完成的工作量與表面上看到的不一致(您可能需要了解這些優化以便能夠對其進行調整)。 驅動程式通常會在視訊卡完成處理所有命令之前,將控制權傳回運行時間。
顯示卡會結合頂點和索引緩衝區、紋理、繪製狀態資訊和圖形命令的數據,來執行大部分的渲染。 當視訊卡完成轉譯時,從轉譯順序建立的工作就會完成。
每個元件(運行時間、驅動程序和視訊卡)都必須處理每個 Direct3D API 呼叫,才能轉譯任何專案。
有一個以上的處理器控制元件
這些元件之間的關聯性更為複雜,因為應用程式、運行時間和驅動程式是由一個處理器所控制,而視訊卡是由個別處理器所控制。 下圖顯示兩種處理器:中央處理器(CPU)和圖形處理器(GPU)。
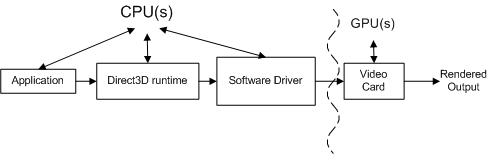
計算機系統至少有一個CPU和一個 GPU,但可以有多個或兩者。 CPU 位於主機板上,GPU 位於主機板或視頻卡上。 CPU 的速度是由主機板上的時鐘晶元決定,GPU 的速度是由個別的時鐘晶元所決定。 CPU 時鐘會控制應用程式、運行時間和驅動程式所完成的工作速度。 應用程式會透過運行時間和驅動程式將工作傳送至 GPU。
CPU 和 GPU 通常會以不同的速度執行,彼此獨立。 GPU 可能會在工作可用時立即回應工作(假設 GPU 已完成先前的工作處理)。 GPU 工作會與 CPU 工作平行完成,如上圖中的曲線所醒目提示。 分析工具通常會測量CPU的效能,而不是 GPU。 這讓分析更具挑戰性,因為檢測分析工具所做的測量包含 CPU 時間,但可能不會包含 GPU 時間。
GPU 的目的是將 CPU 的負載處理從 CPU 卸載到專為圖形工作設計的處理器。 在新式視訊卡上,GPU 會取代管線中從 CPU 到 GPU 的大部分轉換和光源工作。 這可大幅減少 CPU 工作負載,讓更多 CPU 週期可供其他處理使用。 若要微調圖形化應用程式以達到尖峰效能,您必須測量CPU和 GPU 的效能,並平衡這兩種處理器類型之間的工作。
本檔未涵蓋測量 GPU 效能或平衡 CPU 與 GPU 之間工作的相關主題。 如果您想要進一步瞭解 GPU(或特定視訊卡)的效能,請造訪廠商的網站以尋找 GPU 效能的詳細資訊。 相反地,本檔著重於運行時間和驅動程式所完成的工作,方法是將 GPU 工作縮減為可忽略的數量。 這部分是根據遇到效能問題的應用程式通常受 CPU 限制的經驗。
運行時間和驅動程式優化可以遮罩 API 度量
執行時期內建的效能優化功能可能會影響單個呼叫的測量。 以下是示範此問題的範例案例。 請考慮下列轉譯順序:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
範例 1:簡單渲染序列
查看轉譯序列中兩個呼叫的結果,檢測分析工具可能會傳回類似下列的結果:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
分析工具會傳回處理與每個呼叫相關聯的工作所需的CPU週期數目(請記住,GPU並未包含在這些數位中,因為 GPU 尚未開始處理這些命令)。 由於 IDirect3DDevice9::DrawPrimitive 需要近 100 萬個週期來處理,所以您可以得出結論,效率不高。 不過,您很快就會看到為什麼這個結論不正確,以及如何產生可用於預算的結果。
狀態變更的測量需要仔細的渲染順序
IDirect3DDevice9::DrawPrimitive、DrawIndexedPrimitive、或 Clear(例如 SetTexture、SetVertexDeclaration和 SetRenderState)以外的所有呼叫都會產生狀態變更。 每個狀態變更都會設定管線狀態,以控制轉譯的完成方式。
運行時間和/或驅動程式中的優化設計目的是藉由減少所需的工作量來加速轉譯。 以下是可能會污染配置檔平均值的幾個狀態變更優化:
- 驅動程式(或運行時間)可以將狀態變更儲存為本機狀態。 因為驅動程式可以在「延遲」演算法中運作(延遲工作直到絕對必要),所以與某些狀態變更相關聯的工作可能會延遲。
- 運行時間(或驅動程式)可能會藉由優化來移除狀態變更。 其中一個範例可能是移除因多餘而不必要的停用光源狀態變更,因為光源先前已被停用。
沒有萬全的方法可以查看渲染序列,並判斷哪些狀態變更會設置髒位元並延遲工作,或在優化過程中被直接移除。 即使您可以在今天的運行時間或驅動程序中識別優化的狀態變更,明天的運行時間或驅動程式可能會更新。 您也不知道先前的狀態為何,因此很難識別多餘的狀態變更。 驗證狀態變更成本的唯一方法是測量包含狀態變更的轉譯順序。
如您所見,由於有多個處理器、多個元件正在處理命令所造成的複雜狀況,以及元件內建的優化,使得分析難以預測。 在下一節中,將會解決每個分析挑戰。 將會顯示範例 Direct3D 轉譯序列,並隨附測量技術。 透過這項知識,您將能夠在個別呼叫上產生精確的可重複測量。
如何準確地分析 Direct3D 轉譯序列
現在,已經被強調一些剖析挑戰,本節將說明可以幫助您生成可用於預算的剖析數據測量方法。 如果您瞭解 CPU 所控制元件之間的關聯性,以及如何避免運行時間和驅動程式所實作的效能優化,則可以進行精確的可重複分析測量。
若要開始,您必須能夠準確地測量單一 API 呼叫的運行時間。
挑選精確的測量工具,例如 QueryPerformanceCounter
Microsoft Windows作系統包含高解析度定時器,可用來測量高解析度耗用時間。 您可以使用 QueryPerformanceCounter傳回一個這類定時器的目前值。 叫用 QueryPerformanceCounter 以傳回開始和停止值之後,兩個值之間的差異可以使用 queryPerformanceCounter轉換成實際經過的時間(以秒為單位)。
使用 QueryPerformanceCounter 的優點是可在 Windows 中使用,而且很容易使用。 只要使用 QueryPerformanceCounter 來包圍呼叫, 呼叫並儲存開始和停止值。 因此,本文將示範如何使用 QueryPerformanceCounter 來分析運行時間,類似於檢測分析工具測量它的方式。 以下範例示範如何在原始程式碼中內嵌 QueryPerformanceCounter:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
範例 2:使用 QPC 的自定義分析實作
start 和 stop 是兩個大整數,可保存高效能定時器所傳回的開始和停止值。 請注意,QueryPerformanceCounter(&start)會在 SetTexture 之前立即被呼叫,而 QueryPerformanceCounter(&stop)則會在 DrawPrimitive之後立即被呼叫。 取得停止值之後,會呼叫 QueryPerformanceFrequency 以傳回 freq,這是高解析度定時器的頻率。 在此假設範例中,假設您取得下列啟動、停止和頻率的結果:
| 局部變數 | 刻度數目 |
|---|---|
| 開始 | 1792998845094 |
| 停 | 1792998845102 |
| 頻率 | 3579545 |
您可以將這些值轉換成執行 API 呼叫所花費的週期數目,如下所示:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
換句話說,在這台 2 GHz 的機器上,處理 SetTexture 和 DrawPrimitive 大約需要 4568 個時鐘週期。 您可以將這些值轉換成執行所有呼叫的實際時間,如下所示:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
使用 QueryPerformanceCounter 需要您將開始和停止度量新增至轉譯序列,並使用 QueryPerformanceFrequency 將差異(刻度數目)轉換為 CPU 週期數目或實際時間。 識別測量技術是開發自定義分析實作的良好起點。 但在您跳入並開始進行測量之前,您需要知道如何處理顯示卡。
專注於CPU測量
如先前所述,CPU 和 GPU 會平行運作,以處理 API 呼叫所產生的工作。 真實世界應用程式需要分析這兩種類型的處理器,以瞭解您的應用程式是否受限於 CPU 或 GPU 限制。 由於 GPU 效能是廠商特定的,因此在本文中產生涵蓋各種可用視訊卡的結果將非常具有挑戰性。
相反地,本文只會使用自定義技術來測量運行時間和驅動程式工作,專注於分析 CPU 所執行的工作。 GPU 工作會縮減為微不足道的數量,讓 CPU 結果更容易顯示。 這種方法的其中一個優點是,這項技術的結果將出現在附錄中,您應該能夠將其與您的度量相互關聯。 若要將視訊卡所需的工作減少到微不足道的層級,只需將轉譯工作減少到可能最少的數量即可。 這可以藉由限制繪圖呼叫來渲染單一三角形來完成,而且可以進一步限制,讓每個三角形只包含一個像素。
本文中用來測量 CPU 工作的測量單位將是 CPU 時鐘週期數目,而不是實際時間。 CPU 時鐘週期的優點在於,對於 CPU 限制的應用程式來說,相較於在不同 CPU 速度的機器上實際耗用的時間,它具有更好的可攜性。 如有需要,這可以輕鬆地轉換成實際時間。
本檔未涵蓋與平衡 CPU 與 GPU 之間工作負載相關的主題。 請記住,本文的目標是不測量應用程式的整體效能,而是要示範如何準確測量運行時間和驅動程序處理 API 呼叫所需的時間。 透過這些精確的測量,您可以進行 CPU 資源管理,以瞭解某些效能情境。
控制運行時間和驅動程序優化
藉由識別出測量技術,以及降低 GPU 工作量的策略,下一個步驟是了解在分析時會影響執行時間和驅動程序優化的因素。
CPU 工作可以分成三個貯體:應用程式工作、運行時間工作和驅動程式工作。 忽略應用程式的運作方式,因為這在程式設計人員控制之下。 從應用程式的觀點來看,運行時間和驅動程式就像黑匣子一樣,因為應用程式無法控制它們中實作的內容。 關鍵是瞭解可在運行時間和驅動程式中實作的優化技術。 如果您不瞭解這些優化,很容易根據剖析測量對 CPU 所做的工作量得出錯誤的結論。 特別是,有兩個主題與稱為命令緩衝區的內容相關,以及可用來混淆程式代碼剖析的動作。 這些主題包括:
- 使用命令緩衝區進行運行時間優化。 命令緩衝區是運行時間優化,可減少模式轉換的影響。 若要控制模式轉換的時間,請參閱 控制命令緩衝區。
- 消除命令緩衝區的計時效果。 模式轉換的經過時間可能會對分析量值產生重大影響。 此策略是 將渲染序列設置得比模式轉換更大。
控制命令緩衝區
當應用程式進行 API 呼叫時,運行時間會將 API 呼叫轉換成裝置無關的格式(我們將呼叫命令),並將它儲存在命令緩衝區中。 命令緩衝區會新增至下圖。
cpu 元件的 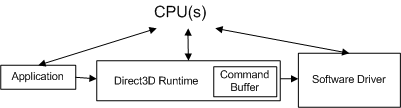
每次應用程式進行另一個 API 呼叫時,運行時間都會重複此序列,並將另一個命令新增至命令緩衝區。 在某些時候,運行時間會清空緩衝區(將命令傳送至驅動程式)。 在 Windows XP 中,清空命令緩衝區會導致模式轉換,因為作系統會從運行時間(在使用者模式中執行)切換至驅動程式(在核心模式中執行),如下圖所示。
- 使用者模式 - 執行應用程式程式代碼的非特殊許可權處理器模式。 使用者模式應用程式無法透過系統服務存取系統數據。
- 核心模式 - Windows 核心代碼執行的高權限處理器模式。 在核心模式中執行的驅動程式或線程可以存取所有系統記憶體、直接存取硬體,以及使用硬體執行 I/O 的 CPU 指示。
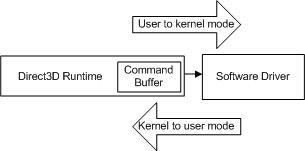
每次 CPU 從使用者切換到核心模式時,都會進行轉換,而且相較於個別 API 呼叫,它所需的週期數目會很大。 如果運行時間在叫用驅動程式時傳送每個 API 呼叫,則每個 API 呼叫都會產生模式轉換的成本。
相反地,命令緩衝區是運行時間優化,其設計目的是降低模式轉換的有效成本。 命令緩衝區會排入許多驅動程式命令,以準備單一模式轉換。 當運行時間將命令新增至命令緩衝區時,控件會傳回至應用程式。 分析工具無法得知驅動程式命令可能尚未傳送至驅動程式。 因此,現成檢測分析工具傳回的數位會誤導,因為它會測量運行時間工作,但不會測量相關聯的驅動程式工作。
設定檔沒有模式轉換的結果
使用範例 2 的渲染序列,以下是一些典型的計時測量,說明模式轉換的幅度。 假設 SetTexture 和 DrawPrimitive 呼叫不會造成模式轉換,現成的檢測分析工具可能會傳回類似下列的結果:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
這些數位都是運行時間將這些呼叫新增至命令緩衝區所花費的時間量。 由於沒有模式轉換,因此驅動程式尚未完成任何工作。 性能分析器的結果是準確的,但它們不測量渲染序列最終將導致 CPU 執行的所有工作。
型態轉換後的分析結果
現在,查看模式轉換發生時,相同範例會發生什麼情況。 這次,假設 SetTexture 和 DrawPrimitive 會導致模式轉換。 同樣地,現成的檢測分析工具可能會傳回類似下列的結果:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
SetTexture 所測量的時間大致相同,不過,DrawPrimitive 所花費時間的大幅增加是由於模式轉換。 以下是正在發生的事情:
- 假設指令緩衝區在渲染序列開始之前能夠容納一個指令。
- SetTexture 會轉換成與裝置無關的格式,並新增至命令緩衝區。 在此案例中,此呼叫會填入命令緩衝區。
- 運行時間會嘗試將 DrawPrimitive 新增至命令緩衝區,但無法,因為它已滿。 相反地,運行時間會清空命令緩衝區。 這會導致內核模式轉換。 假設轉換大約需要5000個週期。 這段時間會貢獻於在 DrawPrimitive 所花費的時間。
- 然後,驅動程式會處理與從命令緩衝區清空的所有命令相關聯的工作。 假設驅動程式處理幾乎填滿命令緩衝區的命令時間大約是935,000個迴圈。 假設驅動程式與 SetTexture 的相關工作約需要 2750 個週期。 這次計入在 DrawPrimitive上所花的時間。
- 當驅動程式完成其工作時,使用者模式轉換會將控制權傳回運行時間。 命令緩衝區現在是空的。 假設轉換大約需要5000個週期。
- 渲染序列會透過轉換 DrawPrimitive 並將其新增至命令緩衝區來完成。 假設這大約需要900個週期。 這段時間會算作在 DrawPrimitive上所花費的時間。
摘要說明結果,您會看到:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
就像測量 DrawPrimitive 在沒有模式轉換的情況下(900 個週期)一樣,測量 DrawPrimitive 在有模式轉換的情況下(947,950 個週期)雖然準確,但在分配 CPU 工作預算方面則無用。 結果包含正確的運行時間工作、SetTexture的驅動程式工作、驅動程式適用於 在 SetTexture之前的任何命令,以及兩個模式轉換。 不過,測量遺漏了驅動程序的DrawPrimitive工作。
模式轉換可能會因應任何呼叫而發生。 這取決於命令緩衝區中先前的內容。 您需要控制模式轉換,以瞭解與每個呼叫相關聯的CPU工作量(運行時間和驅動程式)。 若要這樣做,您需要一個機制來控制命令緩衝區和模式轉換的時間。
查詢機制
Microsoft Direct3D 9 中的查詢機制設計為允許運行時間查詢 GPU 以取得進度,並從 GPU 傳回特定數據。 在分析時,如果 GPU 工作最小化,使其對效能造成微不足道的影響,您可以從 GPU 傳回狀態,以協助測量驅動程式工作。 畢竟,當 GPU 看到驅動程式命令時,驅動程式工作就會完成。 此外,查詢機制可以調整兩個對性能分析很重要的命令緩衝區特性:命令緩衝區何時清空,以及緩衝區中有多少工作量。
以下是使用查詢機制的相同轉譯順序:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
範例 3:使用查詢來控制命令緩衝區
以下是每一行程式代碼的更詳細說明:
- 透過建立 D3DQUERYTYPE_EVENT 查詢物件來建立事件查詢。
- 藉由呼叫 問題(D3DISSUE_END), 將查詢事件標記新增至命令緩衝區。 此標記會指示驅動程序追蹤 GPU 何時完成執行標記之前的任何命令。
- 第一個呼叫會清空命令緩衝區,因為使用 D3DGETDATA_FLUSH 呼叫 GetData 會強制清空命令緩衝區。 每個後續呼叫都會檢查 GPU,以查看它何時完成處理所有命令緩衝區的工作。 在 GPU 閑置之前,此迴圈不會傳回S_OK。
- 取樣開始時間。
- 叫用正在分析的 API 呼叫。
- 將第二個查詢事件標記新增至命令緩衝區。 此標記將用來追蹤呼叫的完成。
- 第一次呼叫會清空命令緩衝區,因為呼叫 GetData 並使用 D3DGETDATA_FLUSH 將強制清空命令緩衝區。 當 GPU 完成處理所有命令緩衝區工作時,GetData 會傳回S_OK,而且循環會因為 GPU 閑置而結束。
- 取樣停止時間。
以下是使用 QueryPerformanceCounter 和 QueryPerformanceFrequency 測量的結果:
| 局部變數 | 刻度數目 |
|---|---|
| 開始 | 1792998845060 |
| 停 | 1792998845090 |
| 頻率 | 3579545 |
再次將刻度轉換為迴圈 (在 2 GHz 計算機上):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
以下是每個呼叫的週期數目明細:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
查詢機制可讓我們控制所測量的運行時間和驅動程式工作。 若要瞭解每個數字,請參考以下在回應每個 API 呼叫時發生的情況以及預估的時間:
藉由呼叫 GetData 並使用 D3DGETDATA_FLUSH,第一個呼叫將清空命令緩衝區。 當 GPU 完成處理所有命令緩衝區工作時,GetData 會傳回S_OK,而且循環會因為 GPU 閑置而結束。
轉譯序列會先將 SetTexture 轉換成與裝置無關的格式,並將其新增至命令緩衝區。 假設這大約需要100個週期。
DrawPrimitive 會轉換並新增至命令緩衝區。 假設這大約需要900個週期。
問題 將查詢標記新增至命令緩衝區。 假設這大約需要 200 個週期。
GetData 會導致命令緩衝區清空,以強制進行內核模式轉換。 假設這大約需要 5000 個週期。
驅動程式接著會處理與這四個呼叫相關聯的工作。 假設驅動程序處理 SetTexture 大約是 2964 個週期,DrawPrimitive 大約 3600 個迴圈,問題 大約是 200 個迴圈。 因此,這四個命令的總驅動程序時間約為 6450 個週期。
注意
驅動程式還需要一點時間才能查看 GPU 的狀態。 因為 GPU 工作很簡單,應該已經完成相關的處理。 GetData 會根據 GPU 完成的可能性傳回S_OK。
當驅動程式完成其工作時,使用者模式轉換會將控制權傳回運行時間。 命令緩衝區現在是空的。 假設這大約需要 5000 個週期。
GetData 的數字包括:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
與 QueryPerformanceCounter 搭配使用的查詢機制會測量所有 CPU 工作。 這會使用查詢標記和查詢狀態比較的組合來完成。 新增至命令緩衝區的啟動和停止查詢標記可用來控制緩衝區中有多少工作。 藉由等待正確的回傳碼,開始量測是在整潔的渲染序列開始之前進行,而停止量測是在驅動程式完成與命令緩衝區內容相關的工作之後進行。 這會有效地擷取運行時間和驅動程式所完成的CPU工作。
既然您已知道命令緩衝區及其在程式代碼剖析上的效果,您應該知道有一些其他條件可能會導致運行時間清空命令緩衝區。 您需要留意渲染序列中的這些事項。 其中有些條件是回應 API 呼叫,有些則是回應運行時間中的資源變更。 下列任何條件都會導致模式轉換:
- 當在特定條件和特定旗標下於頂點緩衝區、索引緩衝區或紋理上呼叫其中一個鎖定方法(Lock)時。
- 建立裝置或頂點緩衝區、索引緩衝區或紋理時。
- 當裝置、頂點緩衝區、索引緩衝區或紋理在最後一次釋放時被銷毀。
- 當 呼叫 的 ValidateDevice 時。
- 呼叫 Present 時。
- 當命令緩衝區填滿時。
- 當 使用 D3DGETDATA_FLUSH 呼叫 GetData 時。
請小心在轉譯序列中監看這些條件。 每次新增模式轉換時,都會將10,000個循環的驅動程式工作加入到您的分析量測中。 此外,命令緩衝區不會以靜態方式調整大小。 運行時間可能會變更緩衝區的大小,以回應應用程式所產生的工作量。 這是另一個相依於渲染序列的優化。
因此,請小心控制剖析期間的模式轉換。 查詢機制提供健全的方法,可用來清空命令緩衝區,以便控制模式轉換的時機,以及緩衝區所包含的工作量。 不過,即使這項技術也可以藉由減少模式轉換時間來改善,使其在測量結果方面微不足道。
讓轉譯序列與模式轉換相較之下變大
在上一個範例中,內核模式參數和使用者模式參數會耗用大約 10,000 個迴圈,與運行時間和驅動程序無關。 由於模式轉換內建於作系統中,因此無法將其縮減為零。 若要讓模式轉換變得微不足道,渲染序列必須調整,以便驅動程式和運行時工作比模式切換大一個數量級。 您可以嘗試執行減法來移除轉換,但將成本分攤到更大的轉譯序列成本會更可靠。
在模式轉換變得微不足道之前,減少模式轉換的策略是將迴圈新增至轉譯序列。 讓我們看看分析結果,例如,如果新增一個迴圈將重複渲染序列1500次:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
範例 4:將迴圈新增至轉譯序列
以下是使用 QueryPerformanceCounter 和 QueryPerformanceFrequency 測量的結果:
| 局部變數 | 抽搐數目 |
|---|---|
| 開始 | 1792998845000 |
| 停 | 1792998847084 |
| 頻率 | 3579545 |
現在使用 QueryPerformanceCounter 計算 2,840 個時間單位。 將時間刻度轉換為週期,與我們之前展示的方法相同。
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
換句話說,此 2 GHz 機器需要大約 690 萬個週期來處理轉譯迴圈中的 1500 個呼叫。 在 690 萬個週期中,模式轉換的時間量約為 10k,因此現在配置文件結果幾乎完全測量與 setTexture 相關聯的工作,DrawPrimitive。
請注意,程式代碼範例需要兩個紋理的陣列。 若要避免因運行時間優化而移除 SetTexture,如果每次呼叫時都會設定相同的紋理指標,只需使用兩個紋理的陣列即可。 如此一來,每次透過迴圈時,紋理指標會變更,並執行與 SetTexture 相關的所有工作。 請確保這兩個紋理的大小和格式都相同,以免紋理更改時影響到其他狀態。
現在您有分析 Direct3D 的技術。 它依賴於高性能計數器(QueryPerformanceCounter)來記錄 CPU 處理任務所需的刻度數。 工作會謹慎控制為運行時間,而驅動程式會使用查詢機制與 API 呼叫相關聯。 查詢提供兩種控制方式:先在轉譯順序開始前清空命令緩衝區,第二個是在 GPU 工作完成時傳回。
到目前為止,本文已示範如何分析轉譯序列。 每個轉譯序列都相當簡單,其中包含單一 DrawPrimitive 调用,以及 SetTexture 调用。 這樣做是為了將焦點放在命令緩衝區,並使用查詢機制來控制它。 以下是如何分析任意轉譯序列的簡短摘要:
- 使用類似 QueryPerformanceCounter 的高效能計數器來測量處理每個 API 呼叫所需的時間。 使用 QueryPerformanceFrequency 和 CPU 時鐘速率,將此轉換為每個 API 呼叫的 CPU 週期數目。
- 藉由繪製每個三角形僅包含一個像素的三角形列表,將 GPU 的工作量降到最低。
- 使用查詢機制在轉譯順序之前清空命令緩衝區。 這可確保分析會捕捉與渲染順序相關聯的正確執行時間和驅動程式工作量。
- 使用查詢事件標記控制新增至命令緩衝區的工作量。 這個相同的查詢會在 GPU 完成工作時偵測到。 由於 GPU 工作是微不足道的,這幾乎相當於測量驅動程式工作完成的時間。
所有這些技術都用來分析狀態變更。 假設您已讀取並瞭解如何控制命令緩衝區,且已順利完成 DrawPrimitive的基準測量,您就可以開始將狀態變更新增至轉譯序列。 當將狀態變更添加到渲染序列時,還有一些額外的分析挑戰。 如果您想要將狀態變更新增至轉譯序列,請務必繼續下一節。
分析 Direct3D 狀態變更
Direct3D 使用許多渲染狀態來控制管線的幾乎每個層面。 造成狀態變更的 API 包含 Draw*Primitive 呼叫以外的任何函式或方法。
狀態變更很棘手,因為您可能無法在不轉譯的情況下看到狀態變更的成本。 這是驅動程式和 GPU 使用的惰性演算法的結果,這種演算法會把工作延後直到絕對必須完成為止。 一般而言,您應該遵循下列步驟來測量單一狀態變更:
- 首先處理 Profile DrawPrimitive。
- 將一個狀態變更新增至轉譯序列,並分析新的序列。
- 減去兩個序列之間的差異,以取得狀態變更的成本。
當然,您過去所學的使用查詢機制並將渲染序列放入迴圈以減少模式切換成本的方法仍然適用。
簡單狀態變更剖析
從包含 drawPrimitive的轉譯序列開始,以下是用來測量新增 SetTexture成本的程式代碼序列:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
範例 5:測量一個狀態變更 API 呼叫
請注意,迴圈包含兩個呼叫,SetTexture 和 DrawPrimitive。 轉譯序列會迴圈 1500 次,併產生類似下列的結果:
| 局部變數 | 抽搐次數 |
|---|---|
| 開始 | 1792998860000 |
| 停 | 1792998870260 |
| 頻率 | 3579545 |
將時鐘脈沖再一次轉換為週期會產生:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
除以迴圈中的反覆項目數目會產生:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
迴圈的每次迭代都包含狀態變更和繪圖呼叫。 減去 DrawPrimitive 轉譯序列的結果:
3850 - 1100 = 2750 cycles for SetTexture
這是將 SetTexture 新增至此渲染序列的平均週期數。 這個相同的技術可以套用至其他狀態變更。
為什麼 SetTexture 稱為簡單狀態變更? 因為所設定的狀態受到限制,所以每次變更狀態時管線都會執行相同的工作量。 將這兩個紋理限制為相同的大小和格式可確保每個 SetTexture 呼叫的相同工作量。
分析需要切換的狀態變更
還有其他狀態變更會導致圖形管線在渲染迴圈的每次反覆運算中所執行的工作量發生變化。 例如,如果已啟用「z-testing」,則每個像素色彩只有在測試新像素的 z 值與現有像素的 z 值之後,才會更新渲染目標。 如果 z 测试已停用,則不會進行這個每像素測試,而且輸出寫入速度會更快。 啟用或停用 z-test 狀態會大幅變更轉譯期間完成的工作量(由 CPU 和 GPU)。
SetRenderState 需要特定的轉譯狀態和狀態值,才能啟用或停用 z-testing。 特定狀態值會在運行時間進行評估,以判斷需要多少工作。 很難在渲染迴圈中測量此狀態變更,同時仍然預設管線狀態以便切換。 唯一的解決方案是在渲染序列中切換狀態變更。
例如,分析技術必須重複兩次,如下所示:
- 從剖析 DrawPrimitive 渲染序列開始。 將此設為基準。
- 剖析第二個切換狀態變更的轉譯順序。 轉譯序列迴圈包含:
- 狀態變更,將狀態設定為 「false」 條件。
- DrawPrimitive 就像原始序列一樣。
- 狀態變更,將狀態設定為「true」值。
- 第二個 DrawPrimitive 強制實現第二個狀態變更。
- 尋找兩個轉譯序列之間的差異。 這是透過下列方式完成:
- 將基準 DrawPrimitive 序列乘以 2,因為在新序列中,有兩次 DrawPrimitive 呼叫。
- 從原始序列減去新序列的結果。
- 將結果除以 2,以取得 「false」 和 「true」 狀態變更的平均成本。
透過渲染序列中使用的迴圈技術,改變管線狀態的成本需要通過在渲染序列的每次迭代中將狀態由「true」切換成「false 」條件來測量,相反過程也需測量。 這裡的“true”和“false”的意義不是字面意思,這只是意味著狀態需要設置為相反的條件。 這會導致分析期間測量這兩種狀態變更。 當然,您所學到的關於使用查詢機制以及將渲染序列放入迴圈中來降低模式轉換成本的方法仍然適用。
例如,以下是用來測量切換 z 測試開啟或關閉時成本的程式代碼順序:
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
範例 5:檢測切換狀態變更
迴圈會執行兩個 SetRenderState 呼叫來切換狀態。 第一個 SetRenderState 呼叫會停用 z-testing,而第二個 SetRenderState 會啟用 z-testing。 每個 SetRenderState 後面接著 DrawPrimitive,以便驅動程式處理與狀態變更相關聯的工作,而不只是在驅動程式中設定髒位。
這些數字對於這個轉譯序列而言是合理的:
| 局部變數 | 刻度數目 |
|---|---|
| 開始 | 1792998845000 |
| 停 | 1792998861740 |
| 頻率 | 3579545 |
再次將刻度轉換為循環的結果是:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
除以迴圈中的反覆項目數目會產生:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
迴圈的每個迭代都包含兩個狀態變更和兩個繪圖呼叫。 減去繪圖呼叫(假設有1100個週期)剩下的是:
6200 - 1100 - 1100 = 4000 cycles for both state changes
這是這兩個狀態變更的平均週期數目,因此每個狀態變更的平均時間為:
4000 / 2 = 2000 cycles for each state change
因此,啟用或停用 z-testing 的平均週期數目是 2000 個週期。 值得注意的是,QueryPerformanceCounter 正在測量 z-enable 一半的時間和 z-disable 一半的時間。 這項技術實際上會測量這兩種狀態變更的平均值。 換句話說,您要測量切換狀態的時間。 使用這項技術時,您無法知道啟用和停用時間是否相等,因為您已測量這兩者的平均。 不過,當預算考量切換狀態時,這是一個合理的數值,因為只有透過切換才能產生狀態變更的應用程式。
現在,您可以套用這些技術和分析您想要的所有狀態變更,對吧? 不完全是這樣。 您仍然需要小心優化,其設計目的是要減少需要完成的工作量。 設計轉譯序列時,您應該注意兩種類型的優化。
注意狀態變更優化
上一節介紹了如何分析兩種狀態變更:一種是在每次迭代中受到限制以產生相同工作量的簡單狀態變更,以及一種會大幅改變完成工作量的切換型狀態變更。 如果您採用先前的轉譯順序,並將另一個狀態變更新增至該順序,會發生什麼情況? 例如,此範例會採用 z>-enable 渲染序列,並將 z-func 比較新增至它:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
z-func 狀態會在寫入 z 緩衝區時設定比較層級(在目前圖元的 z 值與深度緩衝區中像素的 z 值之間)。 D3DCMP_NEVER 關閉 z 測試比較,而 D3DCMP_ALWAYS 在每次進行 z 測試時都執行比較。
使用 DrawPrimitive 在轉譯序列中分析下列其中一個狀態變更, 會產生類似下列結果:
| 單一狀態變更 | 平均週期數目 |
|---|---|
| 僅限D3DRS_ZENABLE | 2000 |
或
| 單一狀態變更 | 平均週期數目 |
|---|---|
| 僅限D3DRS_ZFUNC | 600 |
但是,如果您在相同的轉譯序列中分析D3DRS_ZENABLE和D3DRS_ZFUNC,您可能會看到如下的結果:
| 這兩種狀態變更 | 平均週期數目 |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
您可以預期結果會是 2000 和 600 個 (或 2600) 循環的總和,因為驅動程式正在執行與設定這兩個轉譯狀態相關聯的所有工作。 相反地,平均值是 2000 個週期。
此結果會反映運行時間、驅動程式或 GPU 中實作的狀態變更優化。 在此情況下,驅動程式可以看到第一個 SetRenderState,並設定會延後工作到稍後的骯髒狀態。 當驅動程式看到第二個 SetRenderState時,可能會重複設定相同的骯髒狀態,而且相同的工作會再次延遲。 呼叫 DrawPrimitive 時,最後會處理與骯髒狀態相關聯的工作。 驅動程式會執行工作一次,這表示驅動程式會有效地合併前兩個狀態變更。 同樣地,當呼叫第二個 DrawPrimitive 時,驅動程式實際上會將第三個和第四個狀態變更合併成單一狀態變更。 最終結果是驅動程式和 GPU 會針對每個繪製呼叫處理單一狀態變更。
這是序列相依驅動程序優化的良好範例。 驅動程式會藉由設定骯髒狀態來延後工作兩次,然後執行工作一次以清除骯髒狀態。 這是一個很好的範例,說明在工作延遲到絕對必要之前,可以進行的效率改進類型。
您如何知道哪些狀態變更會在內部設定骯髒的狀態,因而將工作延後到稍後? 只有測試渲染序列(或與驅動程式開發者交談)。 驅動程式會定期更新和改善,因此優化清單不是靜態的。 只有一種方式可以絕對知道特定一組硬體上指定轉譯序列中的狀態變更成本:也就是測量它。
留意 DrawPrimitive 的優化
除了狀態變更優化之外,執行時還會嘗試優化驅動程式必須處理的繪圖呼叫數目。 例如,請考慮這些回溯繪製呼叫:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
範例 5a:兩個繪圖指令
此序列包含兩個繪圖呼叫,執行時會合併成相當於:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
範例 5b:單一合併繪製指令
運行時間會將這兩個特定繪製呼叫串連成單一呼叫,這會將驅動程式的工作減少 50%,因為驅動程式現在只需要處理一個繪製呼叫。
一般而言,運行時間會在以下情況下串連兩個以上連續的 DrawPrimitive 呼叫:
- 基本類型是三角形清單(D3DPT_TRIANGLELIST)。
- 每次後續的 DrawPrimitive 呼叫必須參考頂點緩衝區內的連續頂點。
同樣地,接連不斷地串接兩個或以上的 DrawIndexedPrimitive 呼叫的正確條件如下:
- 基本類型是三角形清單(D3DPT_TRIANGLELIST)。
- 每個連續 DrawIndexedPrimitive 呼叫都必須在索引緩衝區內循序參考連續索引。
- 每個連續的 DrawIndexedPrimitive 呼叫都必須使用相同的 BaseVertexIndex 的值。
若要在分析時防止串接,請修改渲染序列,使原始類型不是三角形列表,或修改渲染序列,避免有連續使用頂點或索引的背靠背繪製呼叫。 更具體來說,執行階段也會串連符合下列兩個條件的繪圖呼叫:
- 當先前的呼叫是 DrawPrimitive時,如果下一個繪圖呼叫:
- 使用三角形清單和
- 指定 StartVertex = 上一個 StartVertex + 上一個 PrimitiveCount * 3
- 使用 DrawIndexedPrimitive時,如果下一個繪製呼叫:
- 使用三角形清單並且
- 指定 StartIndex = 上一個 StartIndex + 上一個 PrimitiveCount * 3,並且
- 指定 BaseVertexIndex = 先前的 BaseVertexIndex
以下是一個繪製呼叫串連的更微妙範例,在進行分析時很容易被忽略。 假設轉譯序列看起來像這樣:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
範例 5c:一個狀態變更和一個繪圖呼叫
迴圈會逐一查看 1500 個三角形,設定紋理並繪製每個三角形。 此轉譯循環大約需要 2750 個迴圈,SetTexture 和 1100 個循環,DrawPrimitive,如前幾節所示。 您可能會直覺地預期,將 SetTexture 移到渲染迴圈外部,應該將驅動程式的工作量減少 1500 * 2750 週期,這是與呼叫 SetTexture 1500 次相關的工作量。 代碼段看起來會像這樣:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
範例 5d:範例 5c 與迴圈外部的狀態變更
將 SetTexture 移出渲染迴圈,確實減少了與 SetTexture 相關的工作量,因為它只需呼叫一次,而不是 1500 次。 較不明顯的次要影響是,DrawPrimitive 的工作也會從 1500 個呼叫減少到 1 個呼叫,因為所有串連繪製呼叫的條件都滿足。 處理渲染序列時,執行時會將 1500 個呼叫轉為單一驅動程式呼叫。 藉由移動這一行程式代碼,驅動程式的工作量已大幅減少:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
這些結果是完全正確的,但在原始問題的內容中非常誤導。 繪圖指令調整已導致驅動程式工作量顯著降低。 執行自定義分析時,這是一個常見問題。 在從渲染序列中移除呼叫時,請小心避免繪圖呼叫串接。 事實上,此案例是此運行時間優化可能改善驅動程式效能的強大範例。
因此,您現在知道如何測量狀態變更。 請從剖析 DrawPrimitive開始。 然後將每個額外的狀態變更新增至序列(在某些情況下新增一個呼叫,在其他情況下新增兩個呼叫),並測量兩個序列之間的差異。 您可以將結果轉換成刻度或週期或時間。 就像使用QueryPerformanceCounter測量轉譯序列一樣,測量個別狀態變更依賴查詢機制來控制命令緩衝區,並將狀態變更放在迴圈中,以將模式轉換的影響降到最低。 這項技術會測量切換狀態的成本,因為分析工具會傳回啟用和停用狀態的平均值。
透過這項功能,您可以開始產生任意轉譯序列,並準確地測量相關聯的運行時間和驅動程式工作。 然後,數字可用來回答預算問題,例如在轉譯序列中還能進行多少額外呼叫,同時仍能維持合理的幀速率,假設是在 CPU 限制的情境下。
總結
本文示範如何控制命令緩衝區,以便能夠準確地分析個別呼叫。 分析編號可以在刻度、週期或絕對時間中產生。 它們代表與每個 API 呼叫相關聯的運行時間和驅動程序數量。
首先,在轉譯序列中分析 Draw*Primitive 呼叫。 請記得:
- 使用 QueryPerformanceCounter 測量每個 API 呼叫的刻度數目。 如有需要,請使用QueryPerformanceFrequency將結果轉換成循環或時間。
- 在啟動之前,使用查詢機制來清空命令緩衝區。
- 在迴圈中包含轉譯順序,以將模式轉換的影響降到最低。
- 使用查詢機制來測量 GPU 何時完成其工作。
- 請留意運行時串接,將對工作量產生重大影響。
這可讓您使用可用來建置的 DrawPrimitive 基準效能。 若要分析一個狀態變更,請遵循下列其他秘訣:
- 將狀態變更新增至已知的渲染序列,並為新序列建立配置檔。 由於測試是在迴圈中完成,因此這需要將狀態設定為相反的值兩次(例如,例如啟用和停用實例)。
- 比較兩個序列之間的循環時間差異。
- 對於大幅變更管線的狀態變更(例如 SetTexture),請減去兩個序列之間的差異,以取得狀態變更的時間。
- 對於大幅變更管線的狀態變更(因此需要切換 SetRenderState等狀態),請減去渲染序列的差異,然後除以 2。 這會產生每個狀態變更的平均週期數目。
但是在進行程式效能剖析時,請小心那些可能導致非預期結果的優化。 狀態變更優化可能會設定導致工作延遲的骯髒狀態。 這可能會導致個人檔案結果不如預期般直觀。 串聯的繪製呼叫將大幅減少驅動程式的工作負荷,這可能導致誤導性的結論。 謹慎規劃的渲染序列可用來防止發生狀態變更和繪製呼叫串接。 訣竅是防止優化在剖析期間發生,以便您產生的數字是合理的預算數字。
注意
在沒有查詢機制的情況下,在應用程式中複製此分析策略會比較困難。 在 Direct3D 9 之前,將命令緩衝區清空的唯一可預測方式是鎖定使用中表面(例如轉譯目標),以等待 GPU 閑置。 這是因為鎖定表面會強制執行緒將命令緩衝區清空,以防緩衝區中有任何轉譯命令,應該在表面鎖定之前更新表面,並且需要等待 GPU 完成。 雖然這項技術功能上是可行的,但相較於 Direct3D 9 中引入的查詢機制,它更加顯眼。
附錄
此表中的數字是與每個狀態變更相關的執行時間和驅動程式工作量的近似值範圍。 近似值是根據使用論文中顯示的技術,對駕駛員進行的實際測量。 這些數字是使用 Direct3D 9 執行時產生的,而且取決於驅動程式。
本文中的技術是設計來測量運行時間和驅動程式工作。 一般而言,提供符合每個應用程式中CPU和 GPU 效能的結果是不切實際的,因為這需要詳盡的轉譯序列數位。 此外,特別難以對 GPU 的效能進行效能評定,因為它高度相依於轉譯順序之前管線中的狀態設定。 例如,啟用 Alpha 混合不會影響所需的 CPU 工作量,但可能會對 GPU 完成的工作量產生很大影響。 因此,本文中的技術會藉由限制需要轉譯的數據量,將 GPU 工作限制為可能的最低數量。 這表示數據表中的數位最符合從 CPU 有限應用程式取得的結果(而不是 GPU 所限制的應用程式)。
建議您使用呈現的技術來涵蓋您最重要的案例和組態。 數據表中的值可用來與您產生的數字進行比較。 由於每個驅動各有不同,產生您將看到的實際數字的唯一方式是利用您的情境來產生分析結果。
| API 呼叫 | 週期的平均數目 |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| SPECULARENABLE | 1900 - 11200 |
| SetRenderTarget (設定渲染目標) | 6000 - 6250 |
| SetPixelShaderConstant (1 常數) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| 照明 | 1700 - 7500 |
| DIFFUSEMATERIALSOURCE | 900 - 8300 |
| 環境材質來源 | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| 設定燈光 | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| 設定索引 | 900 - 5600 |
| 氛圍 | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| 镜面材质来源 | 900 - 4600 |
| 放射材料來源 | 900 - 4500 |
| 設定材質 | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 常數) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| 裁剪 | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| STENCILPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| 雙面板模式 | 450 - 590 |
| 啟用Alpha測試 (ALPHATESTENABLE) | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| 螢幕寫入啟用 | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
相關主題