Fence-Based 資源管理
示範如何透過圍欄追蹤 GPU 進度來管理資源數據生命週期。 記憶體可以有效地與柵欄搭配使用,以仔細管理記憶體中可用空間的可用性,例如在上傳堆積的通道緩衝區實作中。
信號緩衝區案例
以下是一個範例,其中應用程式遇到上傳堆積記憶體的罕見需求。
通道緩衝區是管理上傳堆積的其中一種方式。 信號緩衝區會保存接下來幾個畫面格所需的數據。 應用程式會維護目前的數據輸入指標,以及框架位移佇列來記錄每個畫面,以及開始該畫面的資源數據位移。
應用程式會根據緩衝區建立通道緩衝區,以將數據上傳至每個畫面的 GPU。 目前已轉譯框架 2、信號緩衝區會圍繞畫面 4 的數據換行,畫面 5 所需的所有數據都存在,而框架 6 所需的大型常數緩衝區必須進行子配置。
圖 1:應用程式會嘗試針對常數緩衝區進行子配置,但發現可用記憶體不足。
此通道緩衝區中的可用記憶體不足 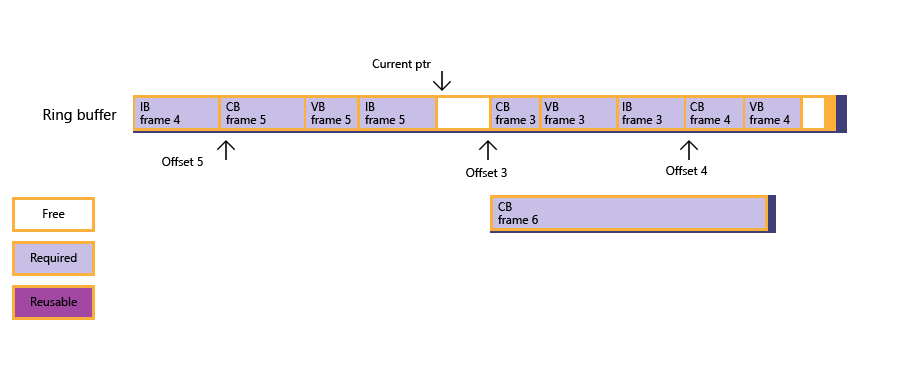
圖 2:透過圍欄輪詢,應用程式發現畫面格 3 已轉譯,然後更新框架位移佇列,而信號緩衝區的目前狀態會隨之而來- 不過,可用記憶體仍然不夠大,無法容納常數緩衝區。
畫面 3 轉譯記憶體仍然不足
圖 3:鑒於情況,CPU 會封鎖本身(透過柵欄等候),直到轉譯畫面 4 為止,這會釋放為畫面 4 配置的記憶體子。
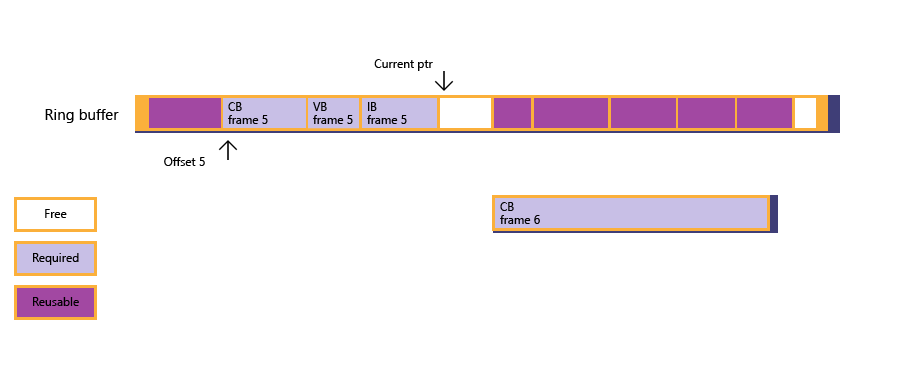
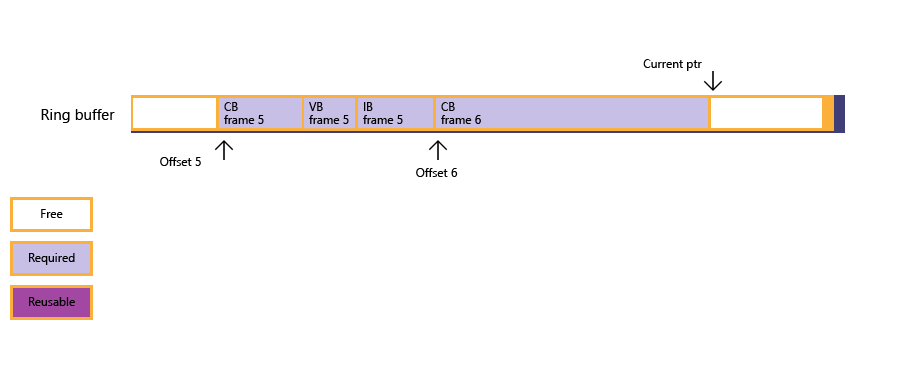
圖 4:現在可用記憶體足以容納常數緩衝區,而子配置成功;應用程式會將大型常數緩衝區數據複製到資源數據先前用於畫面 3 和 4 的記憶體。 目前的輸入指標最後會更新。
如果應用程式實作環形緩衝區,通道緩衝區必須夠大,才能應付資源數據大小更糟的情況。
信號緩衝區範例
下列範例程式代碼示範如何管理環形緩衝區,並注意處理圍欄輪詢和等候的子配置例程。 為了簡單起見,此範例會使用 NOT_SUFFICIENT_MEMORY 來隱藏「堆積中找到的可用記憶體不足」的詳細數據,因為該邏輯(根據 m_pDataCur 和 FrameOffsetQueue內的位移)與堆積或柵欄無關。 此範例已簡化,以犧牲幀速率,而不是記憶體使用率。
請注意,通道緩衝區支持應該是熱門案例;不過,堆積設計不會排除其他使用方式,例如命令列表參數化和重複使用。
struct FrameResourceOffset
{
UINT frameIndex;
UINT8* pResourceOffset;
};
std::queue<FrameResourceOffset> frameOffsetQueue;
void DrawFrame()
{
float vertices[] = ...;
UINT verticesOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
vertices, sizeof(float), sizeof(vertices) / sizeof(float),
4, // Max alignment requirement for vertex data is 4 bytes.
verticesOffset
));
float constants[] = ...;
UINT constantsOffset = 0;
ThrowIfFailed(
SetDataToUploadHeap(
constants, sizeof(float), sizeof(constants) / sizeof(float),
D3D12_CONSTANT_BUFFER_DATA_PLACEMENT_ALIGNMENT,
constantsOffset
));
// Create vertex buffer views for the new binding model.
// Create constant buffer views for the new binding model.
// ...
commandQueue->Execute(commandList);
commandQueue->AdvanceFence();
}
HRESULT SuballocateFromHeap(SIZE_T uSize, UINT uAlign)
{
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Free up resources for frames processed by GPU; see Figure 2.
UINT lastCompletedFrame = commandQueue->GetLastCompletedFence();
FreeUpMemoryUntilFrame( lastCompletedFrame );
while ( NOT_SUFFICIENT_MEMORY(uSize, uAlign)
&& !frameOffsetQueue.empty() )
{
// Block until a new frame is processed by GPU, then free up more memory; see Figure 3.
UINT nextGPUFrame = frameOffsetQueue.front().frameIndex;
commandQueue->SetEventOnFenceCompletion(nextGPUFrame, hEvent);
WaitForSingleObject(hEvent, INFINITE);
FreeUpMemoryUntilFrame( nextGPUFrame );
}
}
if (NOT_SUFFICIENT_MEMORY(uSize, uAlign))
{
// Apps need to create a new Heap that is large enough for this resource.
return E_HEAPNOTLARGEENOUGH;
}
else
{
// Update current data pointer for the new resource.
m_pDataCur = reinterpret_cast<UINT8*>(
Align(reinterpret_cast<SIZE_T>(m_pHDataCur), uAlign)
);
// Update frame offset queue if this is the first resource for a new frame; see Figure 4.
UINT currentFrame = commandQueue->GetCurrentFence();
if ( frameOffsetQueue.empty()
|| frameOffsetQueue.back().frameIndex < currentFrame )
{
FrameResourceOffset offset = {currentFrame, m_pDataCur};
frameOffsetQueue.push(offset);
}
return S_OK;
}
}
void FreeUpMemoryUntilFrame(UINT lastCompletedFrame)
{
while ( !frameOffsetQueue.empty()
&& frameOffsetQueue.first().frameIndex <= lastCompletedFrame )
{
frameOffsetQueue.pop();
}
}
相關主題
-
緩衝區內的 子配置