CPU 分析
本指南提供詳細的技術,可讓您用來調查影響評估計量的中央處理單位(CPU)相關問題。
評定特定分析指南中的個別計量或問題區段會識別常見的調查問題。 本指南提供可用來調查這些問題的技術與工具。
本指南中的技術使用 Windows Performance Toolkit (WPT) 中的 Windows 效能分析器 (WPA)。 WPT 是 Windows 評定與部署套件 (Windows ADK) 的一部分,可以從 Windows 測試人員計劃下載。 如需詳細資訊,請參閱 Windows Performance Toolkit 技術參考。
本指南分為下列三個區段:
本節說明如何在 Windows 10 中管理 CPU 資源。 |
|
本節說明如何在 Windows ADK 工具組中檢視和解譯 CPU 資訊。 |
|
本節包含一組技術,可用來調查和解決與 CPU 效能相關的常見問題。 |
背景
本節包含關於 CPU 效能的簡單描述和基本討論。 如需本主題的更全面研究,建議您參閱 Windows Internals, Fifth Edition 一書。
新式計算機可以包含安裝在不同套接字中的多個CPU。 每個 CPU 可以裝載多個實體處理器核心,每個核心都能夠同時處理一或兩個不同的指令數據流。 這些個別指令數據流處理器是由 Windows 作業系統作為邏輯處理器所管理。
在本指南中,處理器和CPU都會參考邏輯處理器,也就是操作系統可用來執行程式指示的硬體裝置。
Windows 10 以兩種主要方式主動管理處理器硬體: 電源管理、平衡耗電量和效能,以及 使用方式,以平衡程式和驅動程序的處理需求。
處理器電源管理
處理器不一定會處於作業狀態。 當沒有任何指令可供執行時,Windows 會根據 Windows Power Manager 所決定,將處理器放入目標閑置狀態(或 C 狀態)。 根據 CPU 使用量模式,處理器的目標 C 狀態將會隨著時間調整。
閑置狀態是從 C0 (作用中; 非閑置) 到逐漸降低電源狀態的編號狀態。 這些狀態包括 C1(已停止,但仍啟用時鐘)、C2(已停止且時鐘已停用),依此類推。 閑置狀態的實作是處理器特定的。 不過,所有處理器中的狀態號碼較高,會反映較低的耗電量,但也需要較長的等候時間,處理器才能返回指令處理。 閑置狀態所花費的時間會嚴重影響能源使用和電池使用時間。
有些處理器可以在效能 (P-) 和節流狀態中運作,即使它們正在主動處理指令也一樣。 P 狀態會定義處理器支援的時鐘頻率和電壓等級。 T 狀態不會直接變更時鐘頻率,但可以略過某些時鐘刻度分數的處理活動來降低有效的時鐘速度。 一起,目前的 P 和 T 狀態會決定處理器的有效操作頻率。 較低的頻率對應於較低的效能和較低的耗電量。
Windows Power Manager 會根據 CPU 使用模式和系統電源原則,為每個處理器判斷適當的 P 和 T 狀態。 花費在高效能狀態與低效能狀態的時間,會嚴重影響能源使用和電池使用時間。
處理器使用管理
Windows 使用三個主要抽象概念來管理處理器使用方式。
程序
執行緒
延遲過程呼叫 (DPC) 和中斷服務例程 (ISR)
處理序和執行緒
Windows 中的所有使用者模式程式都會在進程的內容中執行。 程式包含下列屬性和元件:
虛擬位址空間
Priority 類別
載入的程式模組
環境和組態資訊
至少一個線程
雖然進程包含程式模組、內容和環境,但它們不會直接排程在處理器上執行。 相反地,進程所擁有的線程會排程在處理器上執行。
線程會維護執行內容資訊。 幾乎所有的計算都是在線程中管理的。 線程活動基本上會影響測量和系統效能。
由於系統中的處理器數目有限,因此無法同時執行所有線程。 Windows 會實作處理器時間共用,讓線程在處理器切換至另一個線程之前執行一段時間。 線程之間切換的動作稱為 內容交換器 ,並由稱為 發送器的 Windows 元件執行。 發送器會根據優先順序、理想的處理器和親和性、量子和狀態,做出線程排程決策。
優先順序
優先順序是發送器如何選取要執行的線程的關鍵因素。 線程優先順序是從 0 到 31 的整數。 如果線程是可執行的,且優先順序高於目前執行中的線程,則會立即先佔低優先順序線程,而較高優先順序的線程則會切換內容。
當線程正在執行或已準備好執行時,除非有足夠的處理器同時執行這兩個線程,或除非較高優先順序的線程僅限於在可用處理器子集上執行,否則不會執行較低優先順序的線程。 線程具有基底優先順序,在特定時間可以暫時提升為較高的優先順序:例如,當進程擁有前景視窗,或 I/O 完成時。
理想的處理器和親和性
線程 的理想處理器和親和性 會決定要執行指定線程的處理器。 每個線程都有由程式設定或由 Windows 自動設定的理想處理器。 Windows 會使用迴圈配置資源方法,讓每個處理程式中大約相等的線程數目指派給每個處理器。 可能的話,Windows 會排程線程在其理想的處理器上執行;不過,線程偶爾可以在其他處理器上執行。
線程的處理器親和性會限制線程執行所在的處理器。 這是比線程的理想處理器屬性更強的限制。 程式會使用 SetThreadAffinityMask 來設定親和性。 親和性可以防止線程在特定處理器上執行。
Quantum
內容切換是昂貴的作業。 Windows 通常允許每個線程執行一段時間,而該線程會在切換至另一個 線程之前,先呼叫量子 。 量子持續時間的設計目的是要保留明顯的系統回應性。 其可藉由將內容切換的額外負荷降至最低,以最大化輸送量。 用戶端和伺服器之間的量子持續時間可能會有所不同。 量子持續時間在伺服器上通常會較長,以犧牲明顯的回應性來最大化輸送量。 在用戶端電腦上,Windows 會整體指派較短的量子,但為與目前前景窗口相關聯的線程提供較長的量子。
州/省
每個線程在任何指定時間都處於特定執行狀態。 Windows 使用與效能相關的三種狀態;以下是: 執行、 就緒和 等候。
目前正在執行的線程處於執行中狀態。 可執行但目前未執行的線程處於 就緒 狀態。 無法執行的線程,因為它們正在等候特定事件處於 等候 狀態。
圖 1 線程狀態轉換中會顯示狀態到狀態轉換:
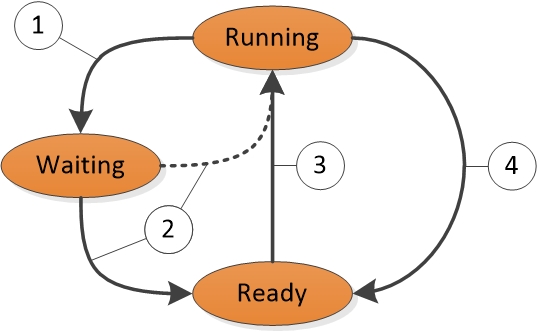
圖 1 線程狀態轉換
圖 1 線程狀態轉換說明如下:
執行中狀態中的線程會呼叫 WaitForSingleObject 或 Sleep(> 0) 等等候函式,起始轉換至等候狀態。
執行中的線程或核心作業會讀取處於等候狀態的線程(例如 SetEvent 或定時器到期)。 如果處理器處於閑置狀態,或整備線程的優先順序高於目前執行中的線程,則整備線程可以直接切換至 [執行中] 狀態。 否則,它會進入就緒狀態。
當執行中的線程等候、產生 (Sleep(0)或到達其量子結尾時,排程處於就緒狀態的線程以供發送器處理。
執行中狀態的線程會在被較高優先順序線程搶佔、產生 (Sleep(0)或其量子結束時,由發送器切換出並放入就緒狀態。
存在於等候狀態的線程不一定表示效能問題。 大部分線程都會花費大量時間進入等候狀態,讓處理器進入閑置狀態並節省能源。 只有在使用者等候線程完成作業時,線程狀態才會成為效能的重要因素。
DPC 和ISR
除了處理線程之外,處理器也會回應來自硬體裝置的通知,例如網路卡或定時器。 當硬體裝置需要處理器注意時,會產生 中斷。 Windows 會暫停目前執行中的線程並執行與中斷相關聯的 ISR,以回應硬體中斷。
在執行ISR期間,可以防止處理器處理任何其他活動,包括其他中斷。 因此,ISR 必須快速完成,否則系統效能可能會降低。 為了減少運行時間,ISR 通常會排程 DPC 以執行必須完成以回應中斷的工作。 針對每個邏輯處理器,Windows 會維護排程的 DPC 佇列。 DPC 會優先於任何優先順序的線程。 處理器回到處理線程之前,它會在其佇列中執行所有 DPC。
在處理器執行 DPC 和 ISR 期間,該處理器上無法執行任何線程。 這個屬性可能會導致線程必須在特定輸送量上執行工作或精確計時的問題,例如播放音訊或視訊的線程。 如果用來執行 DPC 和 ISR 的處理器時間會防止這些線程接收足夠的處理時間,線程可能無法達到所需的輸送量或按時完成其工作專案。
Windows ADK 工具
Windows ADK 會將硬體資訊和評量 寫入評定結果檔案。 WPA 提供各種圖表中 CPU 使用量的詳細資訊。 本節說明如何使用 Windows ADK 和 WPA 來收集、檢視和分析 CPU 效能數據。
Windows ADK 評定結果檔案
因為 Windows 僅支援對稱多重處理系統,本節中的所有信息都會套用至所有已安裝的 CPU 和核心。
節點下<Processor><Instance id=”0”>評量結果檔的 區段中提供EcoSysInfo詳細的 CPU 硬體資訊。
例如:
<Processor>
<Instance id="0">
<ProcessorName>The name of the first CPU</ProcessorName>
<TSCFrequency>The maximum frequency of the first CPU</TSCFrequency>
<NumProcs>The total number of processors</NumProcs>
<NumCores>The total number of cores</NumCores>
<NumCPUs>The total number of logical processors</NumCPUs>
...and so on...
WPA 圖形
將追蹤載入 WPA 之後,您可以在 WPA UI 的 Trace/System Configuration/General 和 Trace/System Configuration/PnP 區段下找到處理器硬體資訊。
注意 本指南中的所有程式都發生在 WPA 中。
CPU 閑置狀態圖表
如果在追蹤中收集閑置狀態資訊, Power/CPU 閑置狀態 圖表會顯示在 WPA UI 中。 此圖表一律包含每個處理器的目標閑置狀態數據。 如果處理器支援此狀態,圖表也會包含每個處理器 的實際 閑置狀態資訊。
下表中的每個數據列描述處理器的目標或實際狀態的閑置狀態變更。 下列資料列適用於圖表中的每個資料列:
| 資料行 | 詳細資料 |
|---|---|
CPU |
受到狀態變更影響的處理器。 |
輸入時間 |
處理器進入閑置狀態的時間。 |
結束時間 |
處理器結束閑置狀態的時間。 |
Max:Duration(ms) |
花費在閑置狀態的時間(預設匯總:最大值)。 |
Min:Duration(ms) |
花費在閑置狀態的時間(預設匯總:最小值)。 |
下一個狀態 |
處理器在目前狀態之後轉換到的狀態。 |
上一個狀態 |
處理器在目前狀態之前轉換的狀態。 |
州/省 |
目前的閑置狀態。 |
狀態 (數值) |
目前閑置狀態為數位(例如 C0 為 0)。 |
Sum:Duration(ms) |
閑置狀態所花費的時間(預設匯總:sum)。 |
Table |
未使用 |
類型 |
目標 (針對 Power Manager 針對處理器選取的目標狀態)或 [實際] (針對處理器的實際閑置狀態)。 |
預設的 WPA 設定檔提供此圖表的兩個預設值: 依類型、CPU 和依類型、CPU 的狀態圖表。
依類型、CPU 的狀態
每個 CPU 的目標和實際狀態會與依類型、CPU 圖形的 Y 軸上的狀態號碼一起繪製。 圖 2 CPU 閑置狀態依類型顯示 CPU 的實際狀態,因為它在作用中和目標閑置狀態之間波動。
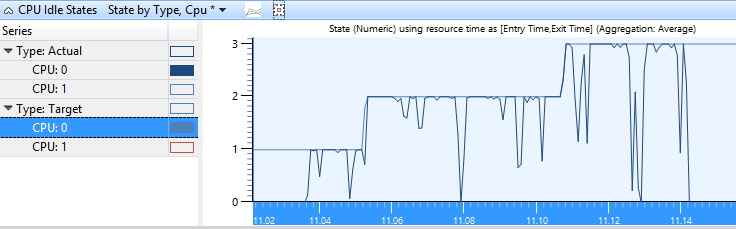
圖 2 依類型、CPU 的 CPU 閑置狀態
依類型、CPU 的狀態圖表
在此圖表中,每個CPU的目標和實際狀態都會以時間軸格式呈現。 每個狀態在時間軸中都有個別的數據列。 圖 3 依類型顯示 CPU 閑置狀態狀態圖表,CPU 在時程表檢視中顯示與圖 2 CPU 閑置狀態狀態依類型、CPU 相同的數據。
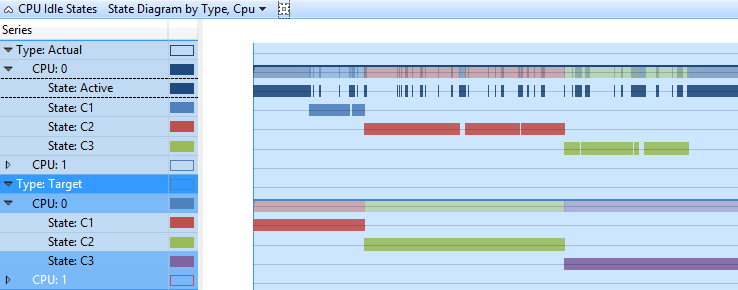
圖 3 依類型、CPU 的 CPU 閑置狀態狀態圖表
CPU 頻率圖表
如果在支援多個 P 或 T 狀態的系統上收集 CPU 頻率數據, 則會在 WPA UI 中使用 CPU 頻率 圖表。 下表中的每個數據列都代表處理器特定頻率層級的時間。 Frequency (MHz) 數據行包含有限的頻率,這些頻率會對應到處理器支援的 P 狀態和 T 狀態。 下列資料列適用於圖表中的每個資料列:
| 資料行 | 詳細資料 |
|---|---|
% 工期 |
持續時間會以目前可見時段的總CPU時間百分比表示。 |
計數 |
頻率變更的數目(個別數據列一律為1個)。 |
CPU |
受頻率變更影響的CPU。 |
輸入時間 |
CPU 進入 P 狀態的時間。 |
結束時間 |
CPU 結束 P 狀態的時間。 |
頻率 (MHz) |
CPU 處於 P 狀態期間的頻率。 |
Max:Duration(ms) |
花費在 P 狀態的時間(預設匯總:最大值)。 |
Min:Duration(ms) |
花費在 P 狀態的時間(預設匯總:minimum)。 |
Sum:Duration(ms) |
花費在 P 狀態的時間(預設匯總:sum)。 |
Table |
未使用 |
類型 |
P 狀態的其他資訊。 |
預設配置檔會 定義此圖表的CPU 默認頻率。 圖 4 依 CPU 的 CPU 頻率會顯示 CPU,因為它在三個 P 狀態之間轉換:

圖 4 依 CPU 的 CPU 頻率
CPU 使用量 (取樣) 圖表
CPU 使用量 (取樣) 圖表中顯示的數據代表以定期取樣間隔進行的 CPU 活動樣本。 在大部分的追蹤中,這是一毫秒(1 毫秒)。 數據表中的每個數據列都代表單一範例。
樣本的權數代表該樣本相對於其他樣本的意義。 權數等於目前範例的時間戳減去上一個範例的時間戳。 由於系統狀態和活動中的波動,加權不一定與取樣間隔完全相等。
圖 5 CPU 取樣代表數據的收集方式:
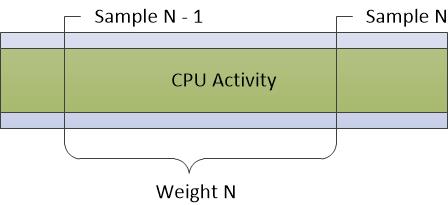
圖 5 CPU 取樣
這個取樣方法不會記錄樣本之間發生的任何 CPU 活動。 因此,CPU 取樣圖表中沒有充分表示非常短持續時間的活動,例如 DPC 和 ISR。
下列資料列適用於圖表中的每個資料列:
| 資料行 | 詳細資料 |
|---|---|
% Weight |
權數會以目前可見時間範圍所花費的總 CPU 時間百分比表示。 |
位址 |
位於堆疊頂端之函式的記憶體位址。 |
所有計數 |
數據列所代表的樣本數目。 此數位包含處理器閑置時所取得的範例。 針對個別的數據列,此數據行一律為 1。 |
計數 |
數據列所代表的樣本數目,不包括處理器閑置時所取得的樣本。 針對個別數據列,此數據行一律為 1 (或 0,適用於 CPU 處於低功率狀態的情況)。 |
CPU |
此範例採用此範例之 CPU 的 0 型索引。 |
顯示名稱 |
使用中進程的顯示名稱。 |
DPC/ISR |
範例會測量一般CPU使用量、DPC/ISR或低功率狀態。 |
函式 |
堆疊頂端的函式。 |
模組 |
包含堆疊頂端函式的模組。 |
優先順序 |
執行中線程的優先順序。 |
處理 |
擁有執行中程式代碼之進程的映像名稱。 |
程序名稱 |
擁有執行程式代碼之進程的完整名稱(包括進程標識符)。 |
Stack |
執行中線程的堆疊。 |
執行緒 ID |
執行中線程的標識碼。 |
線程啟動函式 |
執行中線程啟動的函式。 |
線程啟動模組 |
包含線程啟動函式的模組。 |
TimeStamp |
擷取範例的時間。 |
權數 |
樣本所代表的時間(以毫秒為單位)(也就是自上次樣本以來的時間)。 |
預設設定檔提供此圖表的下列預設值:
依 CPU 的使用率
依優先順序的使用率
依進程使用
依進程和線程的使用率
依 CPU 的使用率
CPU 使用量依 CPU 圖表顯示工作在處理器之間分佈的方式。 圖 6 依 CPU 的 CPU 使用量使用量顯示兩個 CPU 的此分佈:
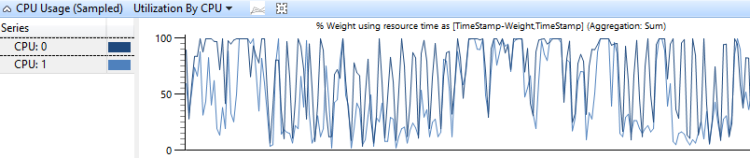
圖 6 依 CPU 的 CPU 使用量使用率
依優先順序的使用率
依線程優先順序分組的CPU使用量 會顯示高優先順序線程如何影響低優先順序線程。 圖 7 依優先順序計算的 CPU 使用量 (取樣) 會顯示此圖表:
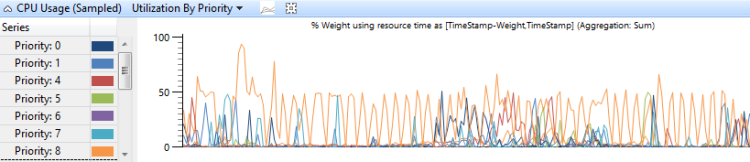
圖 7 依優先順序的 CPU 使用量 (取樣) 使用率
依進程使用
依進程分組的CPU使用量 會顯示進程的相對使用量。 圖 8 依行程取樣的 CPU 使用量顯示此預設值。 在此範例圖表中,會顯示一個進程比其他進程耗用更多的 CPU 時間。
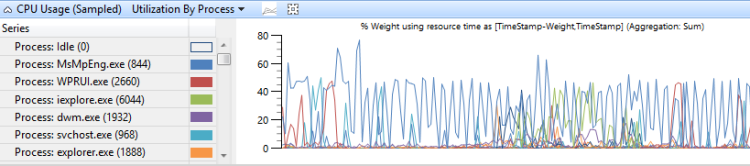
圖 8 依行程計算的 CPU 使用量(取樣) 使用率
依進程和線程的使用率
依進程分組的CPU使用量 ,然後依線程分組,會顯示每個進程中進程和線程的相對使用量。 圖 9 依進程和線程取樣的 CPU 使用量會顯示此預設值。 在此圖表中會選取單一進程的線程。
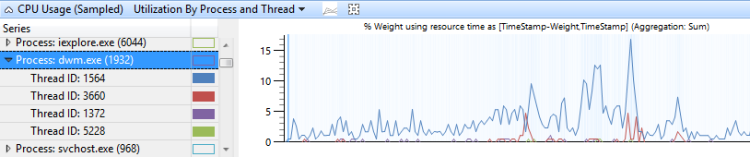
圖 9 依進程和線程取樣的 CPU 使用量
CPU 使用量 (精確) 圖表
CPU 使用量 (精確) 圖表會記錄與內容切換事件相關聯的資訊。 每個數據列都代表一組與單一內容切換相關聯的數據集;也就是線程開始執行時。 會針對下列事件順序收集數據:
新的線程已切換出。
新的線程已準備好由就緒線程執行。
新的線程會切換至 中,藉此切換出舊的線程。
新的線程會再次切換出去。
在圖 10 CPU 使用量精確圖表中,時間從左至右流動。 圖表標籤會對應至 CPU 使用量 (精確) 圖表中的數據行名稱。 [時間戳] 資料行的標籤會顯示在圖表頂端,[間隔持續時間] 資料行的標籤會顯示在圖表底部。
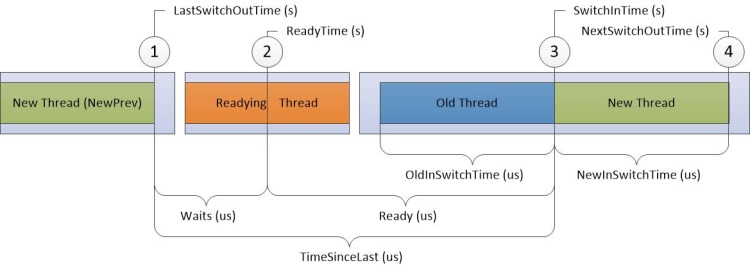
圖 10 CPU 使用量精確圖表
圖 10 CPU 使用量精確圖表中的時間軸中斷,將時間軸分割成可在不同 CPU 上同時發生的區域。 只要編號事件的順序未修改,這些時間軸就可以重疊。 例如,就緒線程可以在 Processor-2 上執行,同時切換出新的線程,然後在 Processor-1 上返回 。
在時程表上記錄下列四個目標的資訊:
新線程,這是已切換的線程。 這是圖表中這個數據列的主要焦點。
NewPrev 線程,這個線程指的是前一次新線程已切換。
準備線程,這是準備處理新線程的線程。
舊線程,這是新線程切換時切換出來的線程。
下表中的數據與每個目標線程有關:
| 資料行 | 詳細資料 |
|---|---|
% CPU 使用量 |
切換新線程之後的CPU使用量。 此值會以目前可見時段的總CPU時間百分比表示。 |
計數 |
數據列所表示的內容切換數目。 對於個別的數據列,這一律為 1。 |
Count:Waits |
數據列所表示的等候次數。 這一定是個別數據列的 1,但當線程切換到閑置狀態時除外;在此情況下,它會設定為 0。 |
CPU |
發生內容切換的CPU。 |
CPU 使用量 (毫秒) |
內容切換之後新線程的CPU使用量。 這等於 NewInSwitchTime,但以毫秒為單位顯示。 |
IdealCpu |
排程器為新線程選取的理想CPU。 |
LastSwitchOutTime (s) |
上次切換出新線程的時間。 |
NewInPri |
已切換之新線程的優先順序。 |
NewInSwitchTime(s) |
NextSwitchOutTime(s) 減去 SwitchInTime(s) |
NewOutPri |
當新線程切換出去時,其優先順序。 |
NewPrevOutPri |
當新線程先前切換出去時,其優先順序。 |
NewPrevState |
新線程在先前切換出之後的狀態。 |
NewPrevWaitMode |
先前已切換出新線程的等候模式。 |
NewPrevWaitReason |
已切換出新線程的原因。 |
NewPriDecr |
影響線程的優先順序提升。 |
NewProcess |
新線程的程式。 |
NewProcess 名稱 |
新線程的進程名稱,包括 PID。 |
NewQnt |
未使用的。 |
NewState |
新線程在切換后的狀態。 |
NewThreadId |
新線程的線程標識碼。 |
NewThreadStack |
當新線程切換時,新線程的堆疊。 |
NewThreadStartFunction |
新線程的 start 函式。 |
NewThreadStartModule |
新線程的開始模組。 |
NewWaitMode |
新線程的等候模式。 |
NewWaitReason |
已切換出新線程的原因。 |
NextSwitchOutTime(s) |
下一次切換出新線程的時間。 |
OldInSwitchTime(s) |
舊線程在切換出之前的時間。 |
OldOutPri |
切換出舊線程時的優先順序。 |
OldProcess |
擁有舊線程的進程。 |
OldProcess 名稱 |
擁有舊線程的進程名稱,包括 PID。 |
OldQnt |
未使用的。 |
OldState |
切換出舊線程之後的狀態。 |
OldThreadId |
舊線程的線程標識碼。 |
OldThreadStartFunction |
舊線程的 start 函式。 |
OldThreadStartModule |
舊線程的開始模組。 |
OldWaitMode |
舊線程的等候模式。 |
OldWaitReason |
舊線程已切換出去的原因。 |
PrevCState |
處理器的上一個 CState。 如果這不是 0 (作用中),處理器處於閑置狀態,然後才將新線程切換為內容。 |
就緒(秒) |
SwitchInTime(s) minusReadyTime (s) |
Readying ThreadId |
就緒線程的線程標識碼。 |
Readying ThreadStartFunction |
就緒線程的 start 函式。 |
Readying ThreadStartModule |
就緒線程的開始模組。 |
ReadyingProcess |
擁有就緒線程的進程。 |
ReadyingProcess 名稱 |
擁有就緒線程的進程名稱,包括 PID。 |
ReadyThreadStack |
就緒線程的堆疊。 |
ReadyTime (s) |
新線程準備就緒的時間。 |
SwitchInTime(s) |
切換新線程的時間。 |
TimeSinceLast (s) |
SwitchInTime(s) 減去 LastSwitchOutTime (s) |
等候 (秒) |
ReadyTime (s) 減去 LastSwitchOutTime (s) |
預設設定檔會針對此圖表使用下列預設值:
依 CPU 的時程表
依進程、線程的時程表
內容切換開始時的優先順序使用方式
依 CPU 的使用率
依進程、線程的使用率
依 CPU 的時程表
每個CPU時間軸上的CPU使用量 會顯示如何在處理器之間散發工作。 圖 11 CPU 使用量(精確)依 CPU 顯示八個處理器系統上的時間軸:
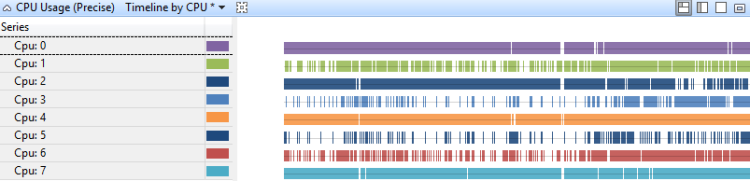
圖 11 CPU 使用量(精確) 依 CPU 的時間軸
依進程、線程的時程表
每個進程、每個線程時間軸上的CPU使用量 會顯示哪些進程在特定時間執行線程。 圖 12 依行程使用方式 (精確) 時間軸,線程會跨數個進程顯示此時程表:
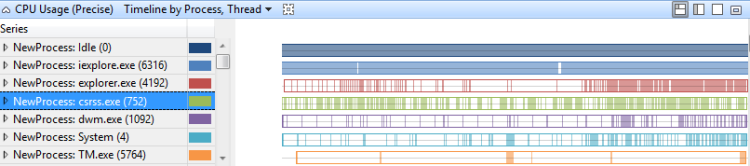
圖 12 依進程、線程的使用量 (精確) 時程表
內容切換開始時的優先順序使用方式
此圖表會識別每個優先順序級層級的高優先順序線程活動高載。 圖 13 CPU 使用量(精確) 依內容切換開始優先順序的使用量會顯示優先順序的分佈:
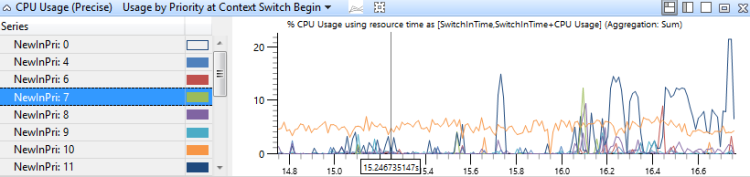
圖 13 內容切換開始時依優先順序的 CPU 使用量 (精確) 使用量
依 CPU 的使用率
在此圖表中,CPU 使用量會分組並依 CPU 繪製圖形,以顯示工作在處理器之間分佈的方式。 圖 14 CPU 使用量(精確) CPU 使用率針對具有八個處理器的系統顯示此圖表。
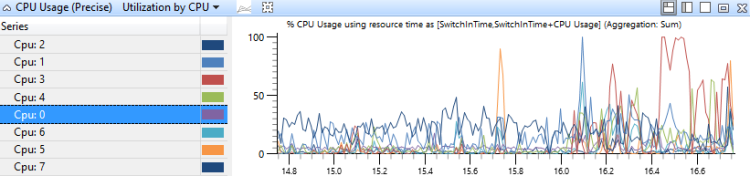
圖 14 CPU 使用量(精確) 依 CPU 的使用率
依進程、線程的使用率
在此圖表中,CPU 使用量會先依進程分組,再依線程分組。 它會顯示行程和每個行程中線程的相對使用量圖 15 CPU 使用量(精確)依進程使用,線程會顯示跨多個進程的此分佈:
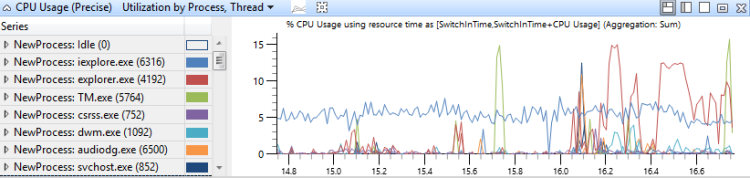
圖 15 CPU 使用量(精確) 依進程、線程的使用率
DPC/ISR 圖形
DPC/ISR 圖表是 WPA 中 DPC/ISR 資訊的主要來源。 圖表中的每個數據列都代表片段,這是 DPC 或 ISR 未中斷的一段時間。 數據會在片段的開頭和結尾收集。 當 DPC/ISR 完成時,會收集其他數據。 圖 16 DPC/ISR 圖表顯示其運作方式:
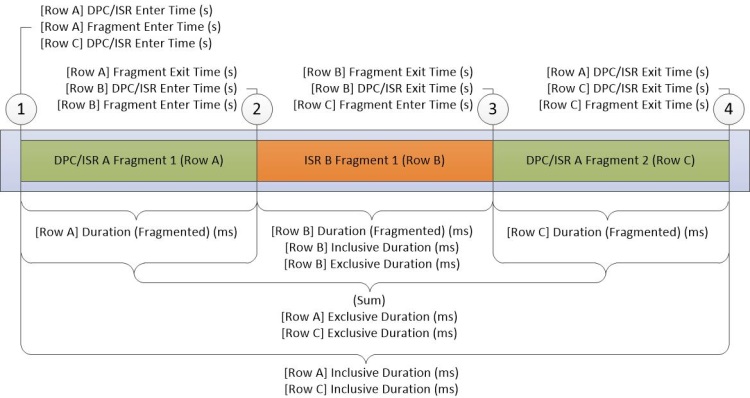
圖 16 DPC/ISR 圖表
圖 16 DPC/ISR 圖表描述在下列活動期間收集的數據:
DPC/ISR-A 會開始執行。
中斷層級高於 DPC/ISR-A 的裝置中斷,會導致 ISR-B 中斷 DPC/ISR A,從而結束 DPC/ISR-A 的第一個片段。
ISR-B 會完成,因而結束ISR-B的片段。 DPC/ISR-A 會繼續在第二個片段中執行。
DPC/ISR-A 會完成,從而結束 DPC/ISR-A 的第二個片段。
每個片段的數據列都會顯示在數據表中。 DPC/ISR-A 的片段會與非片段數據行共用相同的資訊。
DPC/ISR 圖表的數據行描述片段層級資訊,或 DPC/ISR 層級數據行。 片段層級數據行中的每個片段都不同,以及 DPC/ISR 數據行中的相同數據。
| 資料行 | 詳細資料 |
|---|---|
% 工期 (分散) |
持續時間(片段化),以目前可見時段的總 CPU 時間百分比表示。 |
% 獨佔持續時間 |
以目前可見時段的總 CPU 時間百分比表示的獨佔持續時間。 |
% 內含持續時間 |
以目前可見時段的總 CPU 時間百分比表示的內含持續時間。 |
位址 |
DPC 或 ISR 函式的記憶體位址。 |
計數 (DPC/ISR) |
此數據列所代表的 DPC/ISR 計數。 這一定是代表 DPC/ISR 最終片段的數據列 1;否則,此計數為 0。 |
計數 (片段) |
數據列所代表的片段數目。 對於個別的數據列,這一律為 1。 |
CPU |
執行 DPC 或 ISR 之邏輯處理器的索引。 |
DPC 類型 |
若為 DPC,則為 DPC 的類型,可以是一般或定時器。 ISR 的這個值是空白的。 |
DPC/ISR 輸入時間 (s) |
追蹤中啟動 DPC/ISR 的時間。 |
DPC/ISR 結束時間 (s) |
從追蹤開始到 DPC/ISR 完成的時間。 |
工期(片段) (毫秒) |
片段結束時間 (s) 減去片段輸入時間 (s) 以毫秒為單位。 |
獨佔持續時間(毫秒) |
這個 DPC/ISR 之所有片段的分散持續時間總和。 |
Fragment |
如果此數據列的 DPC/ISR 有多個片段,則此值為 True;否則為 False。 |
Fragment |
如果這不是這個 DPC/ISR 的唯一片段,則此值為 True;否則為 False。 |
片段輸入時間(秒) |
片段開始執行的時間。 |
片段結束時間(秒) |
片段停止執行的時間。 |
函式 |
執行的 DPC 或 ISR 函式。 |
內含持續時間 (毫秒) |
DPC/ISR 結束時間 (s) 減去 DPC/ISR 以毫秒為單位輸入時間(秒)。 |
MessageIndex |
訊息訊號中斷的中斷索引。 |
模組 |
包含 DPC 或 ISR 函式的模組。 |
傳回值 |
DPC/ISR 的傳回值 |
類型 |
事件的類型;這是 - DPC 或中斷 (ISR)。 |
向量 |
裝置上的插斷向量值。 |
預設設定檔會針對此圖表使用下列預設值:
[DPC,ISR,DPC/ISR]依 CPU 的持續時間
[DPC,ISR,DPC/ISR]依模組、函式的持續時間
[DPC,ISR,DPC/ISR]依模組、函式的時程表
[DPC,ISR,DPC/ISR]依 CPU 的持續時間
DPC/ISR 事件是由其執行所在的 CPU 匯總,並依持續時間排序。 此圖表顯示 DPC 活動跨 CPU 的配置。 圖 17 依 CPU 的 DPC/ISR 持續時間顯示具有八個處理器的系統此圖表。
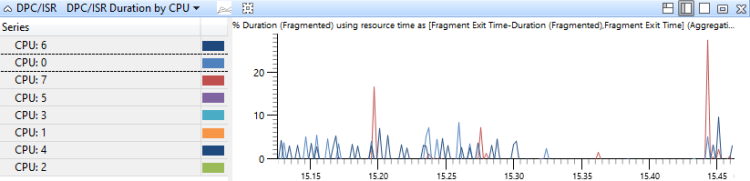
圖 17 依 CPU 的 DPC/ISR 持續時間
[DPC,ISR,DPC/ISR]依模組、函式的持續時間
DPC/ISR 事件會依 DPC/ISR 例程的模組和函式在此圖表中匯總,並依持續時間排序。 這會顯示哪些 DPC/ISR 例程耗用最多時間圖 18 DPC/ISR 依模組持續時間,函式會顯示兩個模組中產生 DPC/ISR 活動的期間:
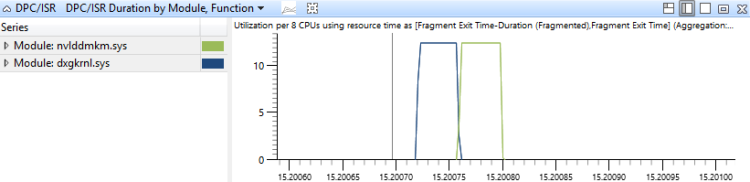
圖 18 依模組、函式的 DPC/ISR 持續時間
[DPC,ISR,DPC/ISR]依模組、函式的時程表
DPC/ISR 事件是由 DPC/ISR 例程的模組和函式在此圖表中匯總。 它們會以時間軸顯示。 此圖表提供 DPC/ISR 執行期間的詳細檢視。 此圖表也可以顯示單一 DPC/ISR 如何分散。 圖 19 DPC/ISR 時間軸依模組,函式顯示三個模組中的啟用時程表:

圖 19 依模組、函式的 DPC/ISR 時間軸
堆疊樹狀結構
堆疊樹狀結構會顯示在WPA中的 CPU使用量(取樣)、 CPU使用量(精確) 和 DPC/ISR 資料表中,以及評估報告中回報的問題。 堆疊樹狀結構會描繪在一段時間內與多個事件相關聯的呼叫堆疊。 樹狀結構中的每個節點都代表由事件子集共用的堆疊區段。 樹狀結構是從個別堆疊建構的,如圖 20 從三個事件堆疊顯示:

圖 20 來自三個事件的堆疊
圖 21 已識別的一般區段顯示如何識別此圖表的常見序列:

圖 21 識別的常見區段
圖 22 從堆疊建置的樹狀結構顯示如何結合通用區段以形成樹狀結構的節點:
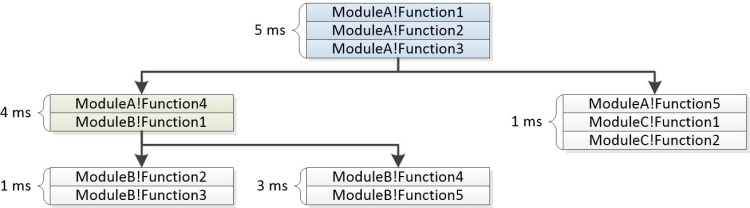
圖 22 從堆疊建置的樹狀結構
WPA UI 中的 [堆疊] 資料行包含每個非分葉節點的展開器。 在評量回報的問題中,樹狀結構會與匯總權數一起顯示。 如果部分分支的權數不符合指定的臨界值,則可以從圖形中移除。 下列範例堆疊顯示上述事件如何顯示為評定回報問題的一部分。
5ms ModuleA!Function1
5ms ModuleA!Function2
5ms ModuleA!Function3
|
4ms |-ModuleA!Function4
4ms | ModuleB!Function1
| |
1ms | |-ModuleB-Function2
1ms | | ModuleB-Function3
| |
3ms | |-ModuleB!Function3
3ms | ModuleB!Function4
|
1ms |-ModuleA!Function5
1ms ModuleC!Function1
1ms ModuleC!Function2
<itself>堆疊中的節點代表函式本身位於堆疊頂端的時間。 節點 <itself> 不包含父函式所呼叫之函式所花費的時間。 該持續時間稱為 函式中花費的專屬 時間。
例如, Function1 會呼叫 Function2。 Function2 花費了 2 毫秒在 CPU 密集型循環中,並呼叫另一個執行 4 毫秒的函式。 這可以由下列堆疊表示:
6ms ModuleA!Function1
|
2ms |-<itself>
4ms |-ModuleA!Function2
4ms ModuleB!Function3
4ms ModuleB-Function4
技術
本節說明效能分析的標準方法。 它提供可用來調查常見 CPU 相關效能問題的技術。
效能分析是四個步驟的程式:
定義案例和問題。
識別相關的元件和相關時間範圍。
建立應該發生之專案的模型。
使用模型來識別問題並調查根本原因。
定義案例和問題
效能分析的第一個步驟是清楚定義案例和問題。 許多效能問題會影響評估計量所測量的案例。 例如:
案例 1:實體資源未完全使用。 例如,伺服器無法充分利用網路連線,因為它無法快速地加密封包。
案例 2:實際資源使用量大於應使用的資源。 例如,系統會在閑置期間使用大量 CPU 資源,以使用電池電力。
案例 3:活動未以所需的速率完成。 例如,視訊播放期間會捨棄畫面,因為畫面不夠快就譯碼。
案例 4:活動已延遲。 例如,用戶啟動 Internet Explorer,但開啟索引標籤所花費的時間比預期還長。
本指南涵蓋與 CPU 資源相關的案例 3 和 4。 案例 1 和 2 不在範圍中,但未涵蓋。 若要分析這些問題,您可以從模棱兩可的觀察開始,例如「速度太慢」,並詢問其他問題來識別案例和確切問題。
識別元件和時間週期
在識別案例和問題之後,您可以識別所涉及的元件和感興趣的時間週期。 這些元件包括硬體資源、進程和線程。
在分析指南中識別相關聯的活動,您通常可以找到感興趣的時間範圍。 活動是開始事件與停止事件之間的間隔,您可以在 WPA 中選取和放大。 如果未定義活動,您可以尋找與案例相關聯的特定泛型事件,或尋找可能標示案例開頭和結尾的資源使用率變更,以尋找時間範圍。 例如,如果 CPU 閑置了兩秒,然後完全利用四秒,然後再閒置兩秒,則完整使用率的四秒可能是擷取視訊播放的追蹤感興趣的區域。
建立模型
若要了解問題的根本原因,您必須擁有應該發生之狀況的模型。 模型會從計量的問題或任何相關聯的目標開始;例如,「此作業應該在5秒內完成」。
更完整的模型包含元件應該如何執行的相關信息。 例如,元件之間的通訊預期為何? 什麼是典型的資源使用率? 作業通常需要多久時間?
模型的資訊通常可在評估分析指南中找到。 如果無法使用該資源,您可以從未顯示效能問題的類似硬體和軟體產生追蹤,以建立模型。
使用模型來識別問題,然後調查根本原因
擁有模型之後,您可以比較追蹤與模型來識別問題。 例如,稱為 「暫停裝置 」的特定活動模型可能會建議整個活動應該在三秒內完成,而稱為 「暫停 <裝置名稱> 」的子活動實例應該不超過 100 毫秒。 如果子活動<暫停裝置名稱>的兩個實例各需要 800 毫秒,您應該調查這些實例。
您可以分析模型的每個偏差,以找出根本原因。 您應該檢查相關線程的狀態,並尋找常見的根本原因。 針對未以必要速率完成或延遲的活動,有一些與 CPU 相關的主要根本原因如下所述:
直接 CPU 使用量:適當的線程收到完整的 CPU 資源,但所需的程式執行速度不夠快。 這可能是程式故障或硬體變慢所造成。
線程干擾:線程沒有獲得足夠的運行時間,因為其他線程正在執行。 在此情況下,線程會被視為饑餓或先佔。
DPC/ISR 干擾:線程沒有足夠的運行時間,因為 CPU 正忙於處理 DPC 或 ISR。
在許多情況下,這些根本原因之一不會明顯影響線程,而線程大部分時間都會處於等候狀態。 在此情況下,您必須識別並調查線程正在等候的事件。 這種遞歸式調查類型稱為 等候分析,並從識別關鍵路徑開始。
進階技術:等候分析和關鍵路徑
活動是作業網路,有些循序且有些平行,會從開始事件流向結束事件。 追蹤中的任何開始/結束事件配對都可以視為活動。 透過此作業網路最長的路徑稱為關鍵路徑。 減少關鍵路徑上任何作業的持續時間會直接減少整體活動的持續時間,不過也可以變更關鍵路徑。
圖 23 活動作業顯示三個線程的活動。 Thread-1 會傳送活動啟動事件,然後等候 Thread-2 和 Thread-3 完成其工作。 Thread-2 會先完成其工作,後面接著 Thread-3。 當兩個線程都已完成其工作時,Thread-1 會整備並完成活動事件。
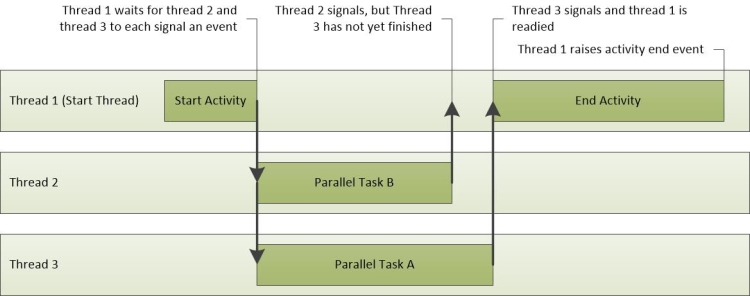
圖 23 活動作業
在此案例中,重要路徑包含 Thread-3 和 Thread-1 的部分。 這些追蹤於圖 24 重大路徑中。 因為 Thread-2 不在關鍵路徑上,因此完成其工作所需的時間不會影響整體啟用時間。
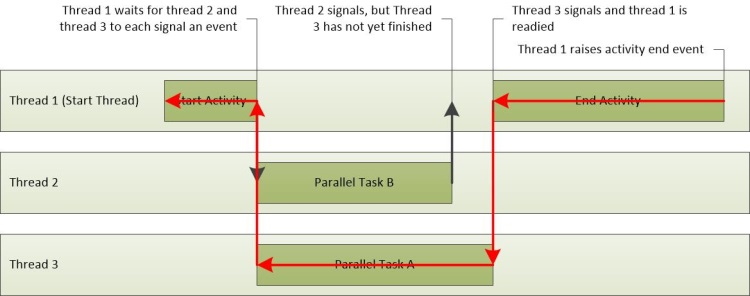
圖 24 重大路徑
關鍵路徑是低階常值解答,說明活動為何花費的時間與活動一樣多。 已知重要路徑的關鍵區段之後,可以分析它們來找出造成整體延遲的問題。
尋找關鍵路徑的一般方法
尋找關鍵路徑的第一個步驟是檢閱案例模型,以了解活動的用途和實作。
瞭解活動有助於識別可能位於重要路徑上的特定作業、進程和線程。 例如,快速啟動繼續總管 Init 活動的延遲可能是 RunOnce 應用程式和 Explorer 初始化程式所造成,這兩者都需要大量的 I/O。
檢閱案例模型之後,請檢查評量是否回報受影響活動的任何問題。 許多時候,重大路徑的近似值會包含在評估回報的延遲問題中。 關鍵路徑會顯示為一連串的等候和就緒動作。 它可以從頭到尾讀取為事件序列,其中主要延遲的區段位於清單中間的重要路徑。 清單中的最後一個專案是整備已完成活動的線程的動作。
如果您必須手動尋找關鍵路徑,建議您識別完成活動的進程和線程,並從活動完成的瞬間回溯工作。 您可以透過 WPA 中的活動圖表,識別啟動活動的進程和線程,以及完成活動的進程和線程。
當追蹤透過評估結果 XML 檔案載入時,活動圖表會顯示。 若要識別與特定活動相關聯的進程和線程,請將圖形展開至感興趣的活動,然後將檢視切換至 Graph+Table。 將圖表模式設定為 Table。 數據表 中每個活動的 [開始進程]、 [開始線程標識符]、 [結束進程] 和 [結束線程標識符 ] 資料行。
在您知道開始和結束進程、線程和活動的實作之後,就可以向後追蹤關鍵路徑。 首先,分析已完成活動的線程,以判斷該線程花費大部分時間的方式:執行、就緒或等候。
顯著的運行時間表示直接 CPU 使用量可能會導致關鍵路徑的持續時間。 在就緒模式中花費的時間表示其他線程會藉由防止重要路徑上的線程執行,來參與關鍵路徑的持續時間。 等候時間指向 I/O、定時器或其他線程,以及目前線程正在等候的重要路徑上進程。
準備目前線程的每個線程可能是關鍵路徑中的另一個連結,也可以分析,直到重要路徑的持續時間考慮為止。
程式:在 WPA 中尋找重要路徑
下列程式假設您已在 [活動] 圖表中識別出您想要尋找重要路徑的活動。
您可以藉由將滑鼠停留在活動圖表中的活動上,來識別完成活動的程式。
新增 CPU 使用量 (精確) 圖表。 縮放至受影響的活動,並套用依進程、線程預設的使用率。
以滑鼠右鍵按兩下資料行標頭,並讓 ReadyThreadStack 和 CPU 使用量 (ms) 資料行可見。 拿掉 Ready (us) [Max] 和 Waits (us) [Max] 資料行。
展開目標進程,並依 CPU 使用量 (ms)、 Ready (us) [Sum] 和 Waits (us) [Sum] 分別排序。
在進程中搜尋 NewThreadId, 其花費在 [執行]、[就緒] 或 [等候] 狀態中花費的時間最多。
花費大量時間執行或就緒狀態的線程,可能代表關鍵路徑上的直接 CPU 使用量。 請注意,其線程標識碼。線程花費大量時間處於等候狀態,可能會等候 I/O、定時器,或關鍵路徑中的另一個線程。
若要探索線程正在等候的內容,請展開 NewThreadId 群組以顯示 ReadyThreadStack。
展開 [Root]。
以 KiDispatchInterrupt 開頭的堆疊與另一個線程無關。 若要判斷線程在這些堆疊中等候的內容,請展開 KiDispatchInterrupt 並檢視子堆疊上的函式。 IopfCompleteRequest 表示整備的線程正在等候 I/O。 KiTimerExpiration 表示整備的線程正在等候定時器。
展開未以 KiDispatchInterrupt 開頭的堆疊,直到您看到 ReadyingProcess 和 ReadyingThread 為止。 如果程式已經展開,請展開對應至 ReadyingThread 的 NewThreadId。 重複此步驟,直到您找到線程正在執行、就緒、等待其他原因,或等候不同的進程為止。 如果線程正在等候不同的進程,請使用該程式重複此程式。
範例
此範例會在快速啟動繼續總管 Init 活動中顯示延遲。 [問題] 窗格中的搜尋會顯示此活動的七個延遲類型問題。 這些問題都可以檢閱為重要路徑的區段。 識別出下列主要區段:
進程TestBootStrapper.exe (3024) 的線程 3872 會先佔 2.1 秒。
進程線程 3872 TestBootStrapper.exe (3024) 使用 1 秒的 CPU 時間。
進程線程 3872 TestBootStrapper.exe (3024) 會排清登錄區 544 毫秒。
進程線程 3872 TestBootStrapper.exe (3024) 睡眠 513 毫秒。
從磁碟讀取Explorer.exe線程 4052 和 4036,造成 461 毫秒的延遲。
進程線程 3872 TestBootStrapper.exe (3024) 會耗盡 187 毫秒。
進程線程 3872 TestBootStrapper.exe將 3.5MB 寫入磁碟,造成 178 毫秒的延遲。
問題顯示此活動延遲 5.2 秒。 這些延遲占整個 6.3 秒期間的活動比例很大。 TestBootStrapper.exe應用程式主要負責延遲,主要是因為它先佔其他處理工作。
調查重大路徑中的問題
縮放至受影響的區域,並新增 ReadyThreadStack 和 CPU 使用量 (ms) 數據行。
在此情況下,Explorer.exe是完成活動的程式。 展開explorer.exe程式,並依 CPU 使用量 (ms)、 Ready (us) [Sum] 和 Waits (us) [Sum] 分別排序,如下圖所示:

圖 25 依 CPU 使用量的活動 (毫秒)

圖 26 依就緒的活動(我們)

圖 27 依等候的活動(我們)
依 CPU 使用量 (ms) 資料行排序會顯示 299 毫秒的最上層子數據列。 依 Ready (us) [Sum] 資料行排序會顯示 46 毫秒的最上層子數據列。 依 Waits (us) [Sum] 資料行排序會顯示 5749 毫秒的最上層子數據列,第二個數據列為 4902 毫秒。 由於這些數據列對延遲的貢獻很大,因此您應該進一步調查它們。
展開堆疊以顯示就緒線程,如下圖所示:
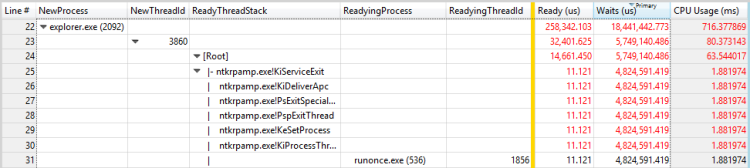
圖 28 準備進程和線程的就緒線程
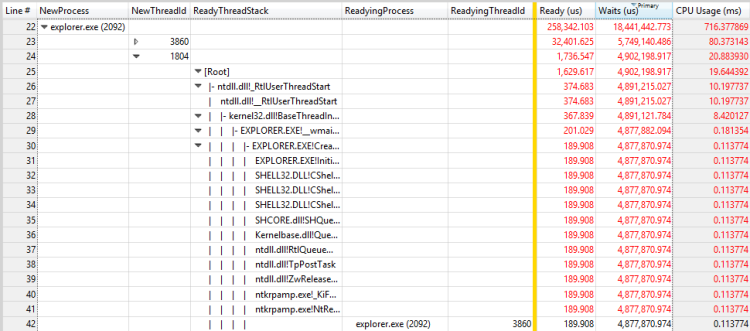
圖 29 另一個線程的就緒進程和就緒線程
在此範例中,第一個線程會花費大部分時間等待RunOnce.exe進程結束。 您應該調查為何RunOnce.exe程式需要這麼多時間才能完成。 第二個線程正在等候第一個線程,而且可能是相同等候鏈結中微不足道的連結。
針對RunOnce.exe重複此程式中的步驟。 主要參與數據行是 Waits (us),它有四個可能的參與者。
展開每個參與者,以查看前三個參與者各等候第四個參與者。 這種情況使得前三個參與者對等候鏈結無關緊要。 第四個參與者正在等候另一個進程,TestBootStrapper.exe。
此案例顯示在圖 30 準備進程和RunOnce.exe線程的就緒線程:
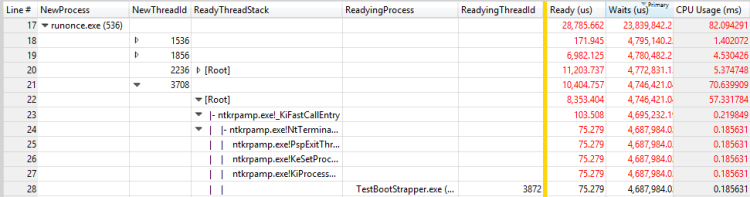
圖 30 RunOnce.exe中線程的準備進程和就緒線程
針對TestBootStrapper.exe重複此程式中的步驟。 結果會顯示在下列三個圖表中:

圖 31 依 CPU 使用量的線程 (ms)

圖 32 依就緒的線程 (我們)

圖 33 依等候的線程 (我們)
線程 3872 花了大約 1 秒執行、2 秒就緒,以及等候 1.3 秒。 由於此線程也是線程 3872 的就緒線程,因此執行和就緒時間可能會造成延遲。 評量會報告下列問題,其時間符合延遲:
進程TestBootStrapper.exe (3024) 的線程 3872 先佔 2.1 秒。
進程線程 3872 TestBootStrapper.exe (3024) 會耗盡 187 毫秒。
進程線程 3872 TestBootStrapper.exe (3024) 使用 1 秒的 CPU 時間。
若要尋找其他參與問題,請檢視線程 3872 正在等候的事件。 展開 ReadyThreadStack 以檢視等候時間 1.3 秒的參與者,如圖 34 參與者等候時間所示:

圖 34 等候時間的參與者
KiRetireDpcList 通常是 I/O 相關, 而 KiTimerExpiration 是定時器。 您可以移除 ReadyThreadStack,然後檢視 NewThreadStack,以檢視 I/O 和定時器起始的方式。 此檢視會顯示三個相關的函式,如圖 35 I/O 和 NewThreadStack 上的定時器所示:

圖 35 NewThreadStack 上的 I/O 和定時器
此檢視會揭露下列詳細資料:
進程線程 3872 TestBootStrapper.exe (3024) 會排清登錄區 544 毫秒。
進程線程 3872 TestBootStrapper.exe (3024) 睡眠 513 毫秒。
進程線程 3872 TestBootStrapper.exe將 3.5MB 寫入磁碟,因而造成 178 毫秒的延遲。
當您開始調查關鍵路徑時,您已分析Explorer.exe中最重要的等候原因,並忽略該等候原因之後所發生之關鍵路徑的任何部分。 若要擷取先前忽略的重要路徑區段,您必須查看時程表。 新增 CPU 使用量 (精確) 並依進程、線程預設套用時程表。
篩選以只包含識別為重要路徑一部分的進程。 結果圖表顯示在圖 36 重大路徑時程表中:

圖 36 重要路徑時程表
圖 36 重要路徑時程表顯示,Explorer.exe停止等候RunOnce.exe之後執行更多工作。 縮放至先前分析的等候鏈結之後的時間週期,然後執行另一個分析。 在此情況下,分析會顯示大量的線程,這些線程是內部Explorer.exe,而且沒有透過關鍵路徑的清楚追蹤。 在此情況下,進一步分析不太可能產生可採取動作的深入解析。
直接 CPU 使用量
活動通常會延遲,因為重要路徑上的線程會使用大量的CPU時間。 藉由使用線程狀態模型,您可以看到此問題的特點是關鍵路徑上的線程,其花費了異常時間在執行中狀態。 在某些硬體上,此大量CPU使用量可能會導致延遲。
問題識別
許多評量會使用啟發學習法來識別直接的CPU使用量相關問題。 重要路徑上的大量 CPU 使用量會回報為下列格式的問題:
進程 P 使用的 CPU 會延遲受影響的活動 A x 秒
其中 P 是正在執行的進程, A 是活動,而 x 是以秒為單位的時間。
如果針對產生延遲的活動回報這些問題,則直接 CPU 使用量可能是原因。
調查直接 CPU 使用量
您可以尋找在 CPU 使用量 (取樣) 圖表中產生 100% CPU 使用量的個別 CPU,以手動識別問題。
縮放至圖形中感興趣的區域,然後選取 [依進程和線程 的使用率] 預設。
根據預設,數據表會在具有最高匯總 CPU 使用量的頂端顯示數據列。 這些線程也會顯示在CPU使用量 (取樣) 圖表頂端。
注意 在具有多個處理器的系統上,使用單一處理器 100% 的線程似乎耗用 100/(邏輯處理器數目)。 在這類系統上,只有虛擬閑置線程 (PID 0, TID 0) 可以顯示大於 100/(邏輯處理器數目)的處理器使用率。 如果取用最多 CPU 的進程和線程會對應至關鍵路徑中的任何線程,則直接 CPU 使用量可能是一個因素。
評定回報的直接CPU使用量問題範例
TestUM.exe行程使用的 CPU 會延遲受影響的活動,快速啟動關機程式TestIM.exe 2.1 秒。 此範例顯示在圖 37 Thread 3208 中:
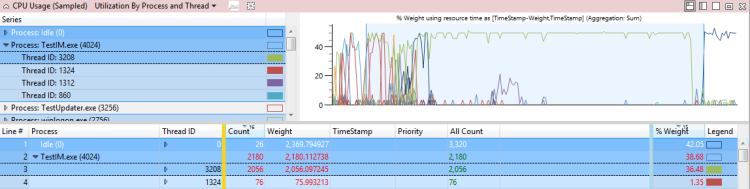
圖 37 線程 3208
調查
發現直接 CPU 使用量會導致關鍵路徑的延遲之後,您必須識別造成延遲的特定模組和函式。
技術:檢閱評定回報的直接CPU使用量問題
您可以展開評估回報的直接CPU使用量問題,以顯示直接CPU使用量所影響的重要路徑。 如果您展開與 CPU 使用量相關聯的節點,則會顯示與 CPU 使用量和相關聯模組相關聯的堆疊。 此檢視顯示於圖 38 展開的 CPU 使用量區段:
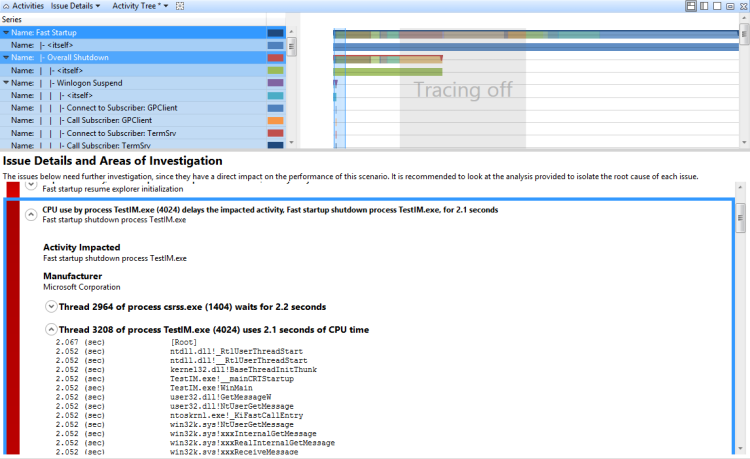
圖 38 展開的 CPU 使用量區段
技術:手動探索直接CPU使用量問題的堆疊
如果評量未回報問題,或如果您需要其他驗證,您可以使用 CPU使用量 (Sampled) 圖表,手動收集CPU使用量問題所涉及的模組和函式資訊。 若要這樣做,您必須縮放至感興趣的區域,並檢視依CPU使用量排序的堆疊。
手動探索直接 CPU 使用量問題的堆疊
在 [追蹤] 功能表上,按兩下 [載入符號]。
縮放時間軸,只顯示受CPU問題影響的重要路徑部分。
依進程和線程預設套用使用率。
將 [堆棧] 資料行新增至顯示,然後將此數據行拖曳到 [線程標識符] 右邊(列左方)。
展開進程和線程以顯示堆疊樹狀結構。
堆疊中的數據列會依CPU使用量的百分比加權以遞減順序排序。 這會將最有趣的堆疊放在最上層。 當您展開堆疊時,請監看 百分比權 數數據行,以確定您的焦點會保留在具有最高使用量的數據列上。
若要擷取堆疊的複本,請選取所有數據列,按兩下滑鼠右鍵,然後按兩下 [ 複製選取範圍]。
解決方法
您可以在設定和元件層級套用補救措施,以解決高 CPU 使用量。
直接CPU使用量對具有較低端處理器的電腦有較高的影響。 在這些情況下,您可以將更多處理能力新增至計算機。 或者,您可能可以從重要路徑或系統中移除問題模組。 如果您可以變更元件,請考慮重新設計工作,以達成下列其中一項結果:
從重要路徑移除需要大量 CPU 的程式碼
使用更具 CPU 效率的演算法
延遲或快取工作
線程干擾
不在重要路徑上的線程的CPU使用量(且可能與活動無關),可能會導致重要路徑上的線程延遲。 線程狀態模型顯示此問題的特點是,在重要路徑上花費異常時間處於就緒狀態的線程。
問題識別
許多評量會使用啟發學習法來識別干擾相關問題。 下列兩種形式中有一種報告:
進程 P 已耗盡。 饑餓會導致受影響的活動 A 的 x 毫秒延遲。
進程 P 已先佔。 先佔會導致受影響的活動 A 延遲 x 毫秒。
其中 P 是進程, A 是活動,而 x 是毫秒的時間。
第一個窗體會反映與重要路徑上線程位於相同優先順序層級的線程干擾。 第二個窗體會反映與重要路徑上線程位於較高優先順序層級之線程的干擾。
如果延遲活動報告了這類問題,線程干擾可能是原因。 您可以使用 CPU 使用量 (精確) 圖表來手動識別問題。
識別線程干擾問題
縮放至間隔,並依CPU默認套用使用率。 所有 CPU 的使用率 100% 表示干擾問題。
套用 [依進程使用]、[線程預設] 和 [第一個就緒] 數據行排序。 (這是包含的數據 行總和 匯總。)
展開受影響的活動程式,並查看重要路徑上線程的就緒時間。 這個值是解決任何線程干擾問題可減少延遲的時間上限。 與所調查延遲相關的值,表示存在線程干擾問題。
圖 39 CPU 使用率接近 100%,圖 40 線程干擾問題代表此案例:

圖 39 CPU 使用率接近 100%
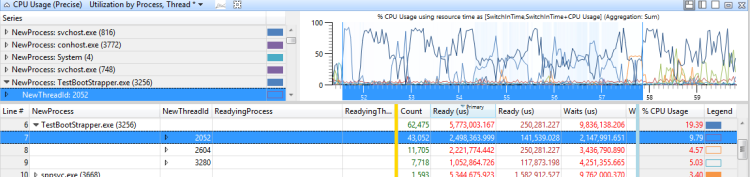
圖 40 線程干擾問題
調查
識別問題之後,您必須判斷受影響的線程為何花費這麼多時間處於就緒狀態。
技術:判斷線程花費時間處於就緒狀態的原因
您可以使用 CPU 使用量 (精確) 圖表來判斷線程花費時間處於就緒狀態的原因。 您必須先判斷線程是否受限於特定處理器。 雖然您無法直接取得這項資訊,但您可以在高 CPU 使用率期間檢查線程的 CPU 使用量歷程記錄。 這是線程往往經常在處理器之間切換的期間。
判斷線程的處理器限制
縮放至受影響的區域。
新增 CPU 使用量 (精確) 圖表,並套用依進程、線程預設的使用率。
使用 [進階] 對話框,在 NewThreadId 右側新增具有唯一計數匯總模式的 Cpu 數據行。
篩選圖形,只顯示您感興趣的線程。
Cpu 資料行中的值會反映線程在目前時間間隔期間執行的處理器數目。 在 100% CPU 使用率的期間,此數目大約是允許執行此線程的處理器數目。 如果值小於可用的處理器數目,線程可能會限制為特定的CPU。
圖 41 受限制的線程提供此圖表的範例:
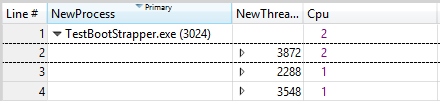
圖 41 受限制的線程
在您知道線程的處理器限制之後,您可以判斷哪些先佔或耗盡線程。 若要這樣做,您必須識別線程在就緒狀態所花費的間隔,然後檢查在這些間隔期間執行的其他線程或進程。
判斷哪些先佔或餓死線程
建構圖形,顯示線程何時處於就緒狀態,並套用依進程、線程預設的使用率。
開啟 [檢視編輯器],按兩下 [進階],然後選取 [圖形組態] 索引標籤。
將 [開始時間] 設定為 [就緒時間],並將 [持續時間] 設定為 [就緒時間],如圖 42 [就緒時間數據行] 所示。 按一下 [確定]。

圖 42 就緒時間數據行
在 [檢視編輯器] 中,以 Ready (us) [Sum] 資料行取代 [CPU 使用量 ] 資料行。
選取感興趣的線程以產生類似圖 43 就緒時程圖表的圖形:

圖 43 就緒時程圖表
在此情況下,線程花費大量時間處於就緒狀態。 若要判斷其一般優先順序,請將 Average 匯總新增至 NewInPri 數據行。
在此情況下,線程的平均優先順序正好是8。 這個數位表示它可能是永遠不會收到優先順序提升許可權的背景線程。
已知平均優先順序之後,請查看允許線程執行之 CPU 的 CPU 活動。
在此情況下,線程判斷只有CPU 1的親和性。
新增另一個 CPU 使用量 (精確) 圖表,並依 CPU 預設套用使用率。 選取相關的 CPU。
開啟 [ 進階 ] 檢視,並針對您稍早找到的優先順序新增篩選,以篩選出該線程。 此案例顯示於圖 44 線程篩選:
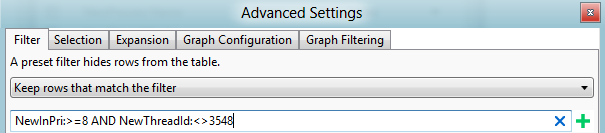
圖 44 線程篩選
在圖 45 CPU 使用量、就緒時間和其他線程活動中,頂端圖表顯示線程 3548 的 CPU 使用量。 中間圖顯示線程就緒的時間,而底部圖表會顯示允許線程執行 CPU 的活動(在此案例中為 Cpu1)。
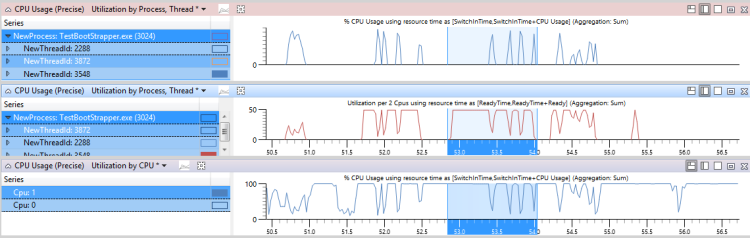
圖 45 CPU 使用量、就緒時間和其他線程活動
放大線程就緒但未執行的區域,在間隔的大部分時間。
在 [CPU 使用量] 圖表中,將 NewInPri 新增至列左側,並檢查結果。
優先順序等於目標線程優先順序的線程或進程會顯示線程已耗盡的時間。 優先順序高於目標線程優先順序的線程或進程會顯示線程優先佔用的時間。 您可以藉由新增所有先佔式線程和動作的時間,來計算線程佔用的總時間。
圖 46 依優先順序使用當目標線程就緒時,顯示已搶佔線程時間的 730 毫秒,而線程時間的 300 毫秒已耗盡。 (此圖縮放為 1192 毫秒間隔。
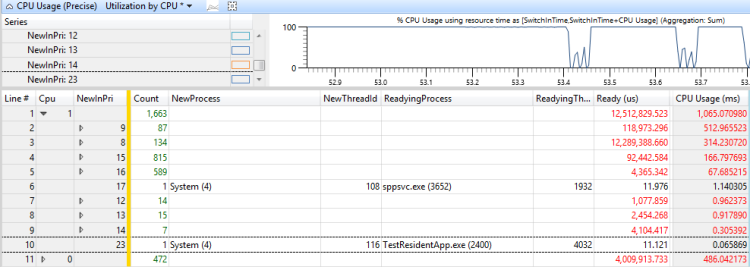
圖 46 依優先順序設定目標線程就緒時的使用量
若要判斷哪些線程負責先佔和饑餓此線程,請將 NewProcess 數據行新增至 NewInPri 數據行右邊,並檢閱進程執行所在的優先順序層級。 在此情況下,先佔和饑餓主要是由相同進程中的另一個線程和TestResidentApp.exe所造成。 您可以假設這些進程會收到高於其基底優先順序的定期優先順序提升。
解決方法
您可以藉由變更組態或元件來解決先佔或饑餓問題。 請參考下列補救措施:
從系統移除有問題的處理程式。
調整有問題進程的基底優先順序...
變更有問題進程執行的時間;例如,在電腦重新啟動時延遲其開始時間。
如果問題元件可以變更,請重新設計它們,使其耗用較少的CPU,或以較低的優先順序執行。
DPC/ISR 干擾
當執行 DPC 和 ISR 耗用過多的處理器時間時,可能沒有足夠的可用 CPU 時間來執行線程。 這種情況可能會導致線程干擾的類似延遲。 當線程必須以一般高頻率速率完成作業時,例如在視訊播放或動畫中,DPC 和 ISR 的干擾可能會導致操作問題。
問題識別
許多評量會使用啟發學習法來識別 DPC/ISR 相關問題。 當 DPC/ISR 活動回報為下列格式的問題時,會將其識別為可疑:
DPC D 超過 P 期間 m 毫秒的臨界值 x 次。這個 DPC 的 n 實例會執行總計 t 毫秒。
其中 D 是 DPC,m 是設定閾值的毫秒數,x 是 DPC 超過閾值的次數,P 是目前的進程,n 是 DPC 執行的實例數目,而 t 是 DPC 超過閾值的總時間。
例如,評估會回報下列問題:
DPC sdbus.sys!SdbusWorkerDpc 超過媒體引擎存留期間 3.0 毫秒 153 次的目標。 此 DPC 的 153 個實例總共執行 864 毫秒
如果針對顯示問題事件或延遲的活動回報此問題,DPC/ISR 活動可能是原因。
手動識別 DPC/ISR 干擾
若要手動識別 DPC/ISR 干擾,請在 WPA 中開啟追蹤,並識別感興趣的問題事件。 這些是評定特定的泛型事件,例如 Microsoft-Windows-Dwm-Core:SCHEDULE_GLITCH 或 Microsoft-Windows-MediaEngine:DropdFrame。
在事件圖形旁,新增 DPC/ISR 依 CPU 圖表的持續時間。 如果依 CPU 的 DPC/ISR 持續時間尖峰與問題事件對齊,DPC/ISR 可能是造成問題的因素。
如需其他數據,請放大數個問題事件顯示前 100 毫秒發生的時間週期。 如果在發生問題事件之前,100 毫秒區域中的一或多個處理器上顯示重要的 DPC/ISR 活動,您可以得出結論,問題事件是由 DPC/IRS 活動所造成。
若要判斷 DPC/ISR 干擾是否造成延遲,請將縮放至顯示執行中線程的區域。 記下此線程執行所在的CPU或CPU。
在 DPC/ISR 圖表中,依 CPU 預設套用 DPC/ISR 持續時間,並在該時間範圍內的相關 CPU 上檢視 DPC/ISR 活動。
圖 47 問題事件和 DPC/ISR 活動顯示iexplore.exe線程 864 與受影響的活動有關。 線程 864 處於 CPU2 上執行中狀態,占檢視時間範圍的 10.65%。 不過,DPC/ISR 圖表顯示 CPU2 在 10% 的時間內正忙於執行 DPC/ISR。
注意 大部分 DPC/ISR 沒有如此範例所示的高影響。
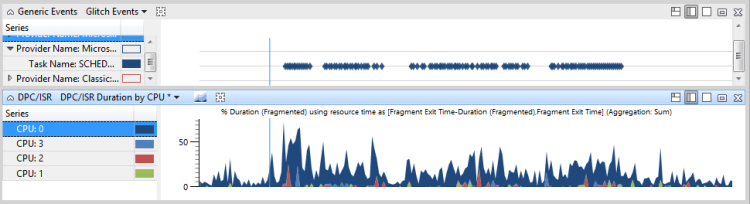
圖 47 問題事件和 DPC/ISR 活動
圖 48 DPC/ISR 與問題事件無關,顯示 DPC/ISR 與效能問題無關:
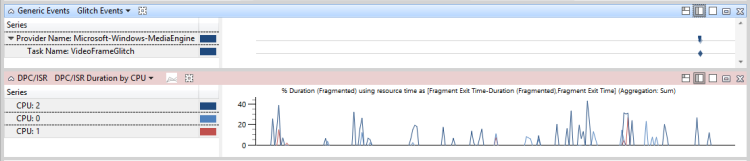
圖 48 DPC/ISR 與問題事件無關
在圖 49 DPC/ISR 干擾所造成的延遲中,顯示 DPC/ISR 會導致效能問題:
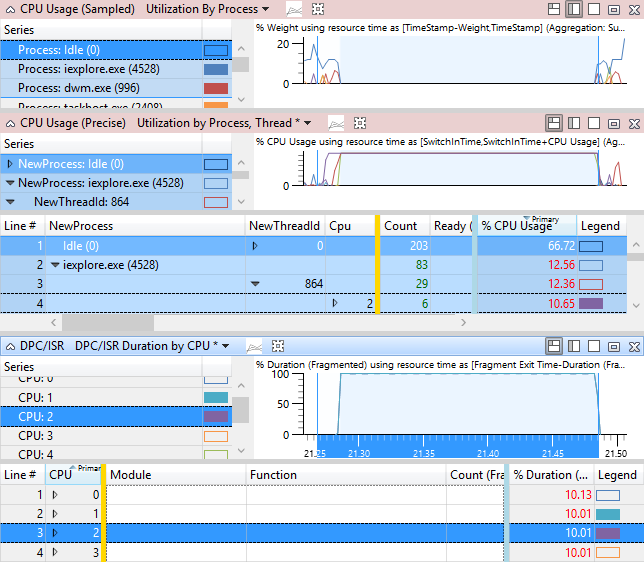
圖 49 DPC/ISR 干擾所造成的延遲
調查
判斷 DPC/ISR 與問題或延遲有關之後,您必須判斷涉及哪些特定 DPC/ISR,以及為何經常或長時間執行。
技術:檢閱評定回報的 DPC/ISR 問題
在評估回報的 DPC/ISR 問題中,您可以展開問題,以顯示 DPC 或 ISR 先佔的主要程式。 展開堆疊以檢視與受影響活動最相關的程式 DPC 活動,如中所示,展開堆疊以瞭解 DPC 的作用。 圖 50 展開的 DPC 堆疊會顯示展開的堆疊:
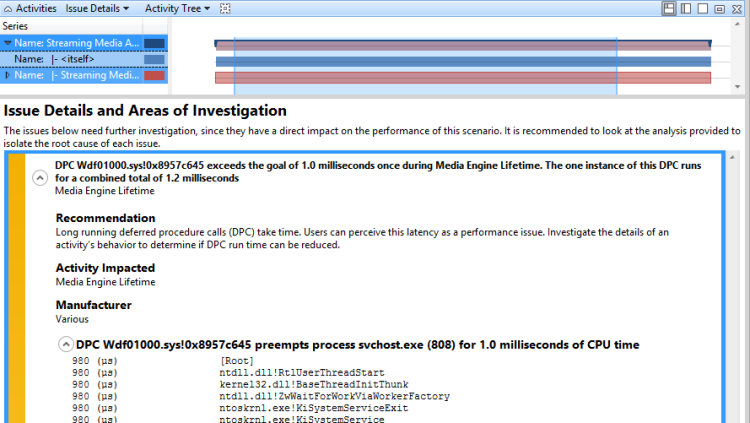
圖 50 展開的 DPC 堆疊
技術:尋找最高持續時間的 DPC/ISR 並檢閱堆棧
如果評量未回報 DPC/ISR 為問題,您可以使用 DPC/ISR 和 CPU 使用量 (取樣) 圖表來取得最相關的 DPC 的堆疊資訊。 建議您尋找感興趣的 DPC/ISR、注意其模組和函式,然後在 CPU 使用量 (Sampled) 圖表中尋找範例,以取得完整的堆棧資訊。
尋找最高持續時間 DPC/ISR 並檢閱堆疊
縮放至感興趣的間隔。
在 DPC/ISR 圖表中,依模組、函式選取預設的 DPC/ISR 持續時間。
如果載入符號,DPC/ISR 事件會依總持續時間排序,然後依Module和 Function 細分。 清單中的頂端數據列包含可能導致事件問題的 DPC/ISR 事件。 記下模組和函式名稱。
在 [ CPU 使用量][取樣] 圖表中,選取 [依進程 使用量] 預設值。 根據預設,此預設會隱藏 DPC/ISR 活動。
開啟 [ 檢視編輯器],然後按兩下 [ 進階]。
在 [篩選] 索引標籤上,將 [隱藏符合篩選條件的數據列] 設定變更為 [保留符合篩選的數據列]。 這可讓 DPC/ISR 活動顯示。
移除 [處理] 數據行,並新增 [堆棧] 數據行,以檢視依堆棧排序的 DPC/ISR。
清除目前的數據列選取範圍。
以滑鼠右鍵按下 Stack 資料列中的儲存格,然後按下此資料列中的 [尋找]。
輸入您在此程式的步驟 2 中所指出的模組和函式。
核 取 [新增至目前的選取範圍],然後按兩下 [ 全部 尋找] 以選取函式的所有實例。
選取所有數據列之後,以滑鼠右鍵按兩下並按兩下 [蝴蝶/檢視呼叫者]。
此檢視會顯示此特定函式的活動,依總持續時間排序。 檢視類似於在評估回報問題的詳細檢視中顯示的堆疊。 Weight 數據行大約是每個函式在堆疊上花費的內含時間,以毫秒為單位。
此檢視顯示在 DPC 的圖 51 呼叫者中,依近似持續時間排序:

圖 51 DPC 的被呼叫者依近似持續時間排序
技術:檢閱長時間執行的 DPC/ISR
DPC/ISR 的總持續時間很重要,但長時間執行的個別 DPC/ISR 更有可能造成延遲。 在 DPC/ISR 圖表中, 以遞減順序排序的內含持續時間 (ms) 資料行會顯示個別 DPC/ISR 的最大持續時間。 某些評估配置檔中可用的預設 Long DPC/ISR 可讓您篩選此檢視,只顯示內含持續時間大於 1 毫秒的 DPC/ISR。
注意 如果無法使用此預設,您可以開啟 [ 檢視編輯器]、 [進階 ] 區段,以新增篩選。
解決方法
DPC/ISR 活動通常反映必須在硬體或元件層級更正的硬體或軟體問題。 在組態層級,您可以取代硬體,或將相關的驅動程序升級為固定版本。 在元件層級,硬體和驅動程式應遵循 MSDN 中 DPC/ISR 的最佳做法,並盡可能使用線程的 DPC。 線程的 DPC 不會在用戶端版本的 Windows 分派層級執行。 如需 DPC/ISR 最佳做法的詳細資訊,請參閱 ISR 和 DPC 行為的指導方針和線程 DPC 簡介。