針對 SQL Server 中窄和寬方案的 UPDATE 效能問題進行疑難解答
適用於:SQL Server
UPDATE在某些情況下,語句可能更快,而其他語句則較慢。 有許多因素可能導致這類差異,包括更新的數據列數目,以及系統上的資源使用量(封鎖、CPU、記憶體或 I/O)。 本文將涵蓋差異的其中一個特定原因:SQL Server 所做出的查詢計劃選擇。
什麼是狹隘和寬闊的計劃?
當您針對叢集索引數據行執行 UPDATE 語句時,SQL Server 不僅會更新叢集索引本身,也會更新所有非叢集索引,因為非叢集索引包含叢集索引鍵。
SQL Server 有兩個選項可以執行更新:
窄型計劃:執行非叢集索引更新以及叢集索引鍵更新。 這個直接的方法很容易理解;更新叢集索引,然後同時更新所有非叢集索引。 SQL Server 會更新一個數據列,並移至下一個數據列,直到全部完成為止。 這種方法稱為窄型方案更新或個別數據列更新。 不過,這項作業相對昂貴,因為將更新的非叢集索引數據順序可能不是叢集索引數據的順序。 如果更新涉及許多索引頁,當數據位於磁碟上時,可能會發生大量的隨機 I/O 要求。
寬方案:若要將效能優化並減少隨機 I/O,SQL Server 可以選擇廣泛的方案。 它不會同時更新非叢集索引,以及叢集索引更新。 相反地,它會先排序記憶體中的所有非叢集索引數據,然後依該順序更新所有索引。 這種方法稱為廣泛計劃(也稱為個別索引更新)。
以下是窄式和寬方案的螢幕快照:

SQL Server 何時選擇寬方案?
SQL Server 必須符合兩個準則,才能選擇廣泛的方案:
- 受影響的數據列數目大於 250。
- 非叢集索引的分葉層級大小(索引頁計數 * 8 KB)至少是最大伺服器記憶體設定的 1/1000。
狹隘和寬闊的計劃如何運作?
若要瞭解窄和寬計劃的運作方式,請遵循下列環境中的下列步驟:
- SQL Server 2019 CU11
- 最大伺服器記憶體 = 1,500 MB
執行下列腳本來建立一個數據表
mytable1,其中包含 41,501 個數據列、一個數據行上的c1叢集索引,以及其餘數據行的五個非叢集索引。CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)執行下列三個 T-SQL
UPDATE語句,並比較查詢計劃:UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)- 更新一個數據列UPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)- 已更新 250 個數據列。UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)- 已更新 251 個數據列。
根據第一個準則檢查結果(受影響數據列數目的閾值為250)。
下列螢幕快照顯示以第一個準則為基礎的結果:

如預期般,查詢優化器會為前兩個查詢選擇窄計劃,因為受影響的數據列數目小於 250。 因為受影響的數據列計數是 251,而大於 250,因此會針對第三個查詢使用寬計劃。
根據第二個準則檢查結果(分葉索引大小的記憶體至少是伺服器記憶體上限設定的 1/1000)。
下列螢幕快照顯示以第二個準則為基礎的結果:
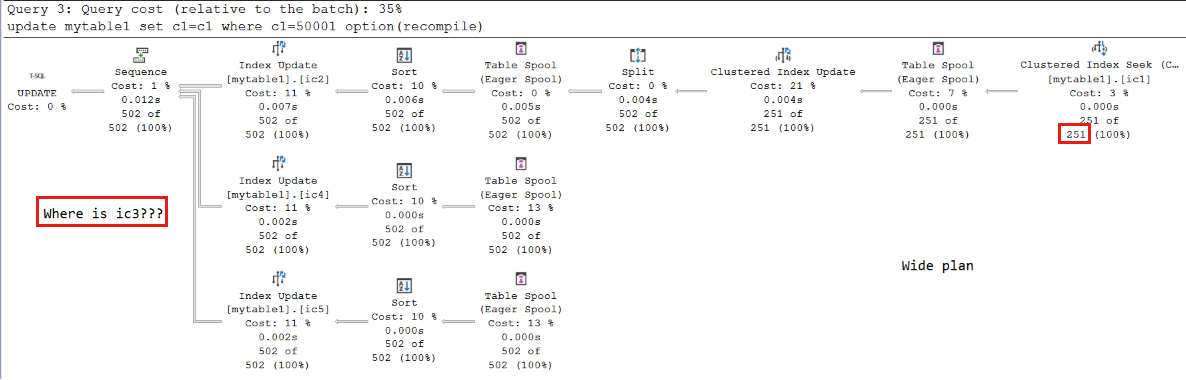
已針對第三
UPDATE個查詢選取寬計劃。 但是計劃中沒有看到索引ic3(在數據行c3上)。 發生此問題的原因是不符合第二個準則 - 與設定最大伺服器記憶體相較之下的分葉頁面索引大小。資料列
c2c4、 和c4的資料類型是char(30),而資料行c3的資料類型為char(20)。 每個索引ic3數據列的大小都小於其他數據列,因此分葉頁面數目小於其他頁面。透過動態管理功能 (DMF)
sys.dm_db_database_page_allocations的協助,您可以計算每個索引的頁數。 對於索引ic2、ic4和ic5,每個索引都有 214 個頁面,其中 209 個是分葉頁面(結果可能會稍有不同)。 分葉頁面所耗用的記憶體是 209 x 8 = 1,672 KB。 因此,比率為 1672/(1500 x 1024) = 0.00108854101,大於 1/1000。 不過,ic3只有 161 頁;其中 159 個是分葉頁面。 比率為 159 x 8/(1500 x 1024) = 0.000828125,小於 1/1000 (0.001)。如果您插入更多數據列或減少 最大伺服器記憶體 以符合準則,計劃將會變更。 若要讓索引分葉層級大小大於 1/1000,您可以執行下列命令,將最大伺服器記憶體設定降到 1,200:
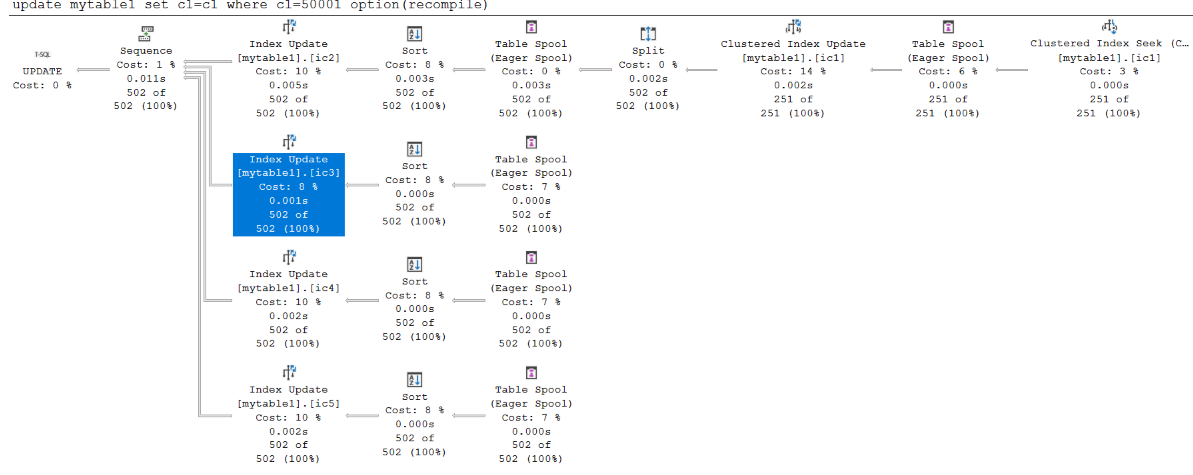
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.在此情況下,159 x 8/(1200 x 1024) = 0.00103515625 > 1/1000。 此變更之後,即
ic3會出現在方案中。如需 的詳細資訊
show advanced options,請參閱 使用 Transact-SQL。下列螢幕快照顯示,當達到記憶體閾值時,寬方案會使用所有索引:



寬計劃比窄計劃快嗎?
答案是,這取決於數據與索引頁面是否快取在緩衝池中。
數據會在緩衝池中快取
如果數據已經在緩衝池中,與窄計劃相比,具有寬方案的查詢不一定提供額外的效能優點,因為寬計劃的設計是為了改善 I/O 效能(實體讀取,而不是邏輯讀取)。
若要在數據位於緩衝池中時,測試寬計劃是否比窄計劃快,請遵循下列環境中的下列步驟:
SQL Server 2019 CU11
最大伺服器記憶體:30,000 MB
數據大小為 64 MB,而索引大小約為 127 MB。
資料庫檔案位於兩個不同的實體磁碟上:
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
執行下列命令,以建立另一個資料表
mytable2:CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCAN執行下列兩個查詢來比較查詢計劃:
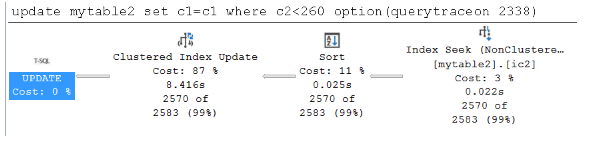
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow plan如需詳細資訊,請參閱追蹤旗標 8790 和追蹤旗標 2338。
具有寬計劃的查詢需要0.136秒,而具有窄計劃的查詢只需要0.112秒。 這兩個持續時間非常接近,而且個別索引更新(寬計劃)較不有用,因為數據已在緩衝區中,然後再
UPDATE執行 語句。下列螢幕快照顯示緩衝池中快取數據時的寬和窄計劃:


數據不會在緩衝池中快取
若要測試當數據不在緩衝池中時,寬計劃是否比窄計劃快,請執行下列查詢:
注意
當您進行測試時,請確定您的 是 SQL Server 中唯一的工作負載,而磁碟則專用於 SQL Server。
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
具有寬計劃的查詢需要 3.554 秒,而具有窄計劃的查詢需要 6.701 秒。 此時間,寬計劃查詢的執行速度會更快。
下列螢幕快照顯示緩衝池中未快取資料時的寬方案:

下列螢幕快照顯示緩衝池中未快取數據時的窄方案:
當數據不在緩衝區時,寬計劃查詢一律比狹窄的查詢計劃快嗎?
答案是“不一定”。若要在數據不在緩衝區中時,測試寬計劃查詢是否一律比縮小查詢計劃快,請遵循下列步驟:
執行下列命令,以建立另一個資料表
mytable2:SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GOmytable3與相同mytable2,但數據除外。mytable3具有所有五個具有相同值的數據行,讓非叢集索引的順序遵循叢集索引的順序。 這種數據排序會將寬方案的優點降到最低。執行下列命令來比較查詢計劃:
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow plan這兩個查詢的持續時間會大幅減少! 寬計劃需要0.304秒,這比這次窄計劃慢一點。
下列螢幕快照顯示使用寬和窄時效能的比較:


套用廣泛方案的案例
以下是也會套用寬方案的其他案例:
叢集索引數據行具有唯一或主鍵,而且會更新多個數據列
以下是重現案例的範例:
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
下列螢幕快照顯示叢集索引具有唯一索引鍵時,會使用寬計劃:

如需詳細資訊,請參閱 維護唯一索引。
叢集索引數據行是在數據分割配置中指定
以下是重現案例的範例:
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
下列螢幕快照顯示當分割區配置中有叢集數據行時,會使用寬型方案:

叢集索引數據行不是數據分割配置的一部分,且數據分割配置數據行已更新
以下是重現案例的範例:
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
下列螢幕快照顯示更新資料分割配置數據行時,會使用寬型方案:
