套用核心變更之後,Azure Linux 虛擬機無法開機
適用於:✔️ Linux VM
注意
本文所參考的 CentOS 是一種 Linux 發行版,且將到達生命周期結束(EOL)。 請據以考慮您的使用和規劃。 如需詳細資訊,請參閱 CentOS 生命週期結束指引。
本文提供Linux虛擬機 (VM) 在套用核心變更之後無法開機的問題解決方案。
必要條件
請確定 已在Linux VM中啟用序列主控台 並正常運作。
如何識別核心相關的開機問題
若要識別核心相關的開機問題,請檢查特定的核心異常字串。 若要這樣做,請使用 Azure CLI 或 Azure 入口網站,在開機診斷窗格或序列控制檯窗格中檢視 VM 的序列控制台記錄輸出。
核心異常看起來會像下列輸出,而且會顯示在序列控制台記錄檔的結尾:
Probing EDD (edd=off to disable)... ok
Memory KASLR using RDRAND RDTSC...
[ 300.206297] Kernel panic - xxxxxxxx
[ 300.207216] CPU: 1 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.xxx.x86_64 #1
在線疑難解答
提示
如果您有最近的 VM 備份, 請從備份 還原 VM 以修正開機問題。
序列主控台是解決開機問題最快的方法。 它可讓您直接修正問題,而不需要將系統磁碟呈現至復原 VM。 請確定您符合散發套件的必要條件。 如需詳細資訊,請參閱 適用於Linux的虛擬機序列主控台。
使用 Azure 序列主控台在 GRUB 功能表中中斷 VM,然後選取任何先前的核心將其開機。 如需詳細資訊,請參閱 舊版核心版本的開機系統。
移至對應的區段,以解決特定核心相關的開機問題:
解決核心相關的開機問題之後,請重新啟動 VM,使其可以透過最新的核心版本開機。
離線疑難解答
提示
如果您有最近的 VM 備份, 請從備份 還原 VM 以修正開機問題。
如果 Azure 序列控制台無法在特定 VM 中運作,或不是訂用帳戶中的選項,請使用救援/修復 VM 針對開機問題進行疑難解答。 若要這樣做,請遵循下列步驟:
使用 VM 修復命令 來建立修復 VM,該 VM 具有鏈接受影響 VM 的 OS 磁碟復本。 使用 chroot 掛接修復 VM 中的 OS 檔案系統複本。
注意
或者,您可以使用 Azure 入口網站手動建立救援 VM。 如需詳細資訊,請參閱使用 Azure 入口網站將 OS 磁碟連結至復原 VM,以針對 Linux VM 進行疑難排解。
移至對應的區段,以解決特定核心相關的開機問題:
解決核心相關的開機問題之後,請執行下列動作:
- 結束 chroot。
- 從救援/修復 VM 卸除文件系統的複本。
az vm repair restore執行 命令,將修復的OS磁碟與VM的原始OS磁碟交換。 如需詳細資訊,請參閱使用 Azure 虛擬機修復命令修復 Linux VM 中的步驟 5。- 查看 Azure 序列主控台或嘗試連線到 VM,驗證 VM 是否能夠開機。
如果有重要的核心相關內容、整個
/boot分割區或其他重要內容遺失,且無法復原,建議您從備份還原 VM。 如需詳細資訊,請參閱如何在 Azure 入口網站 中還原 Azure VM 數據。
舊版核心版本的開機系統
使用 Azure 序列主控台
使用 Azure 序列主控台重新啟動 VM。
- 選取序列 主控台視窗頂端的 [關機 ] 按鈕。
- 選取 [ 重新啟動 VM (硬式)] 選項。
序列主控台連線繼續後,您會看到序列主控台視窗左上角的倒數計數器。 按ESCAPE鍵,以在 GRUB 功能表中中斷您的 VM。
按下向下鍵以選取任何先前的核心版本。
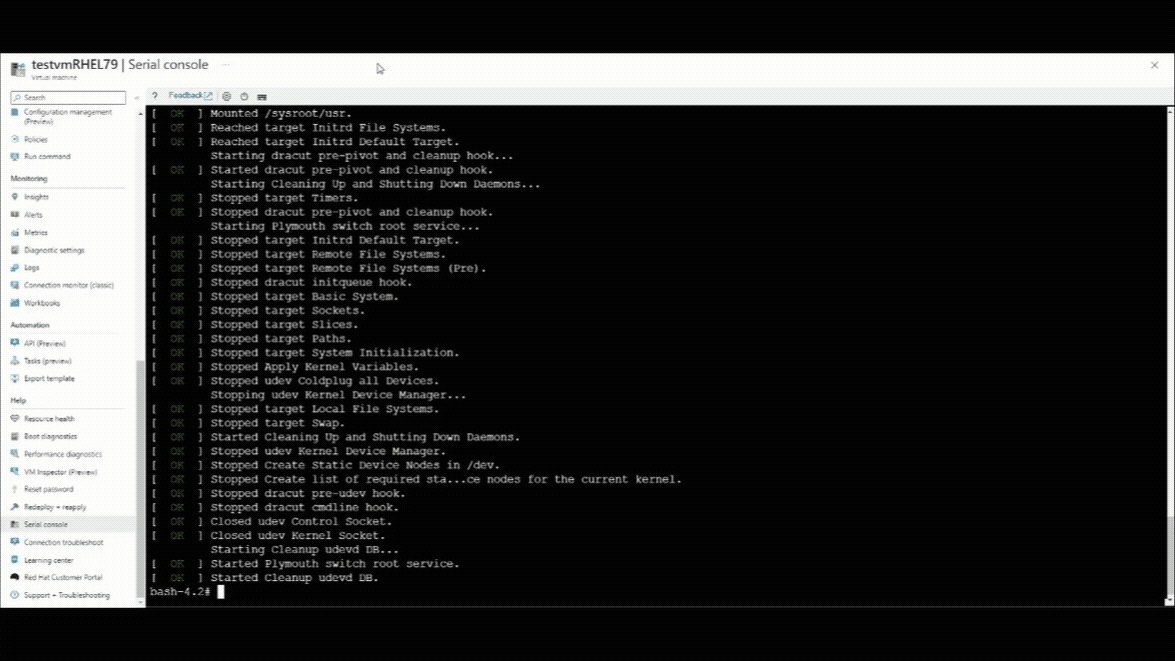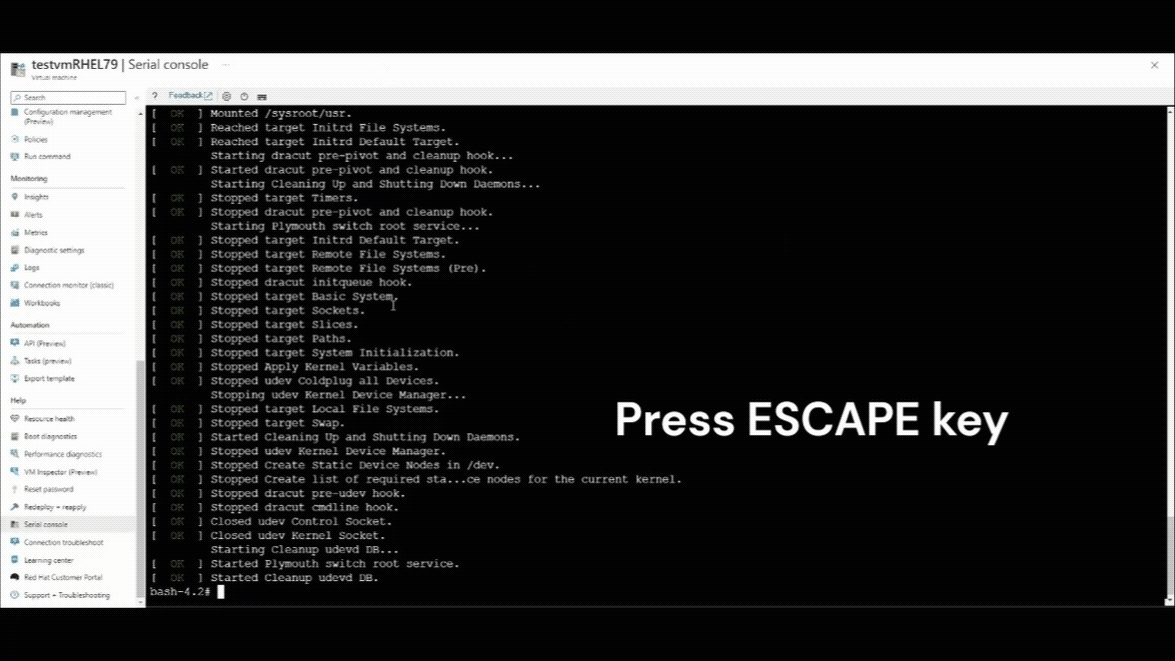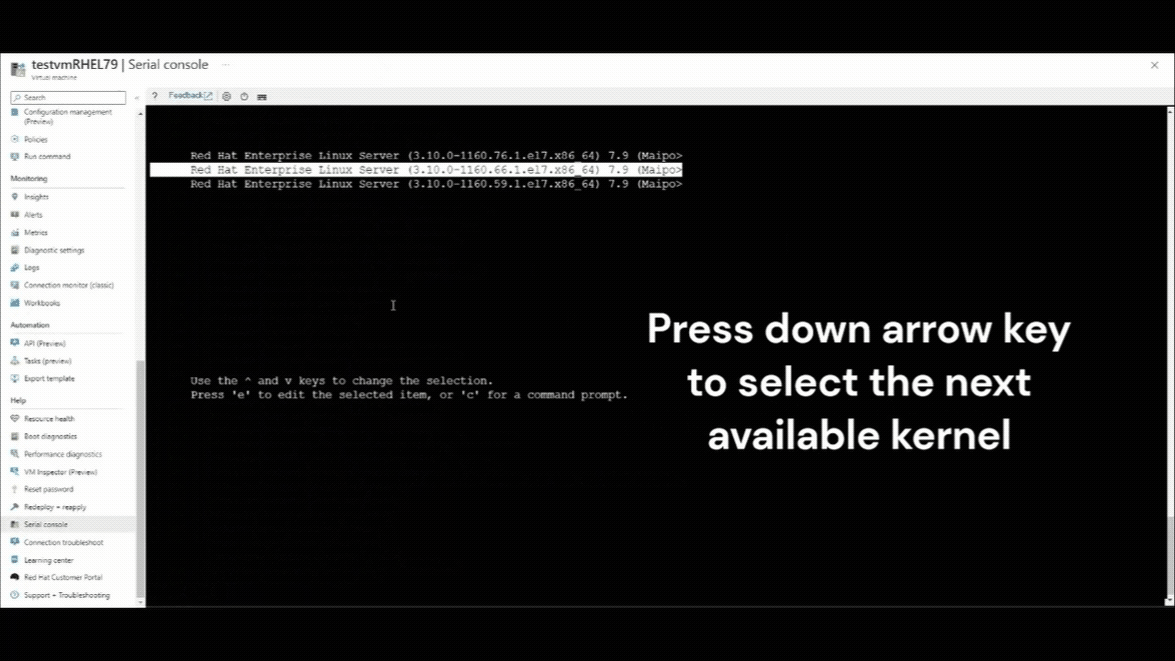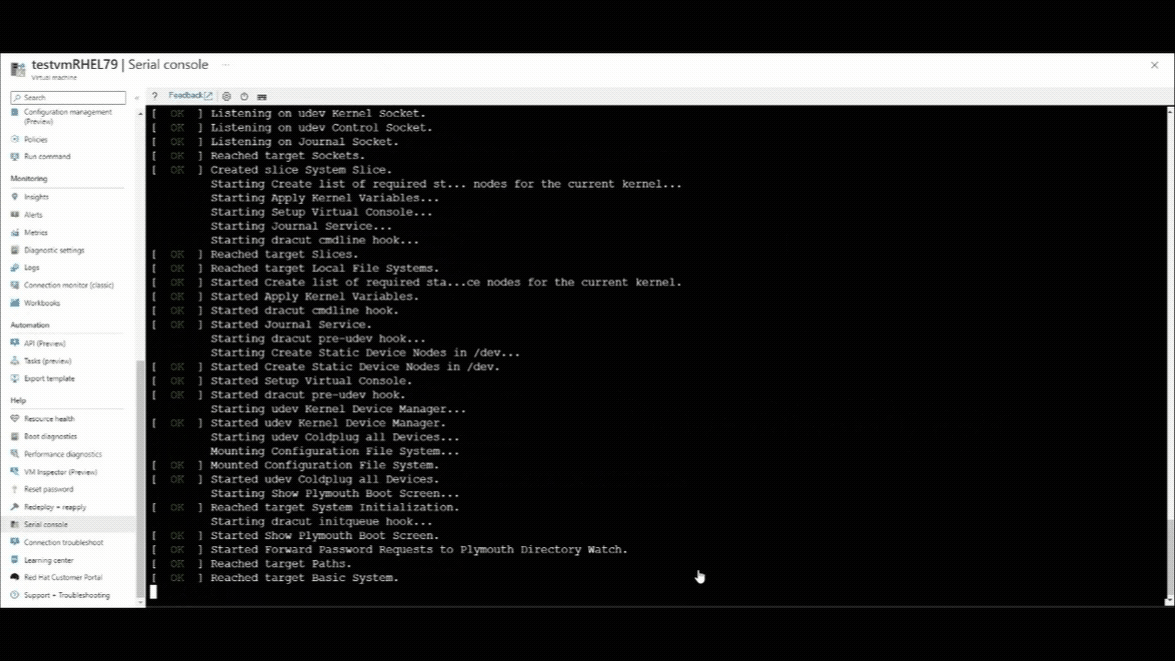
GRUB_DEFAULT如手動變更預設核心版本中所述,變更 /etc/default/grub 檔案中的變數。 這是持續變更。

注意
如果 GRUB 功能表中只列出一個核心版本,請遵循 離線疑難解答方法,從修復 VM 針對此問題進行疑難解答 。
使用修復 VM (ALAR 文稿)
在 Azure Cloud Shell 中執行下列 bash 命令,以建立修復 VM。 如需詳細資訊,請參閱 使用 Azure Linux 自動修復 (ALAR) 來修正 Linux VM - 核心選項。
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopy執行下列命令,將中斷的核心取代為先前安裝的版本:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters kernel --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME
注意
如果系統中只安裝一個核心版本,請遵循 脫機疑難解答方法,從修復 VM 針對此問題進行疑難解答 。
手動變更預設核心版本
若要從修復 VM(在 chroot 內部)或在執行中的 VM 上修改預設核心版本,請遵循下列步驟:
注意
如果核心降級復原完成,請選取最新的核心版本,而不是較舊的版本。
RHEL 7、Oracle Linux 7 和 CentOS 7
執行下列其中一個命令,以驗證 GRUB 設定檔中可用的核心清單:
Gen1 VM:
cat /boot/grub2/grub.cfg | grep menuentryGen2 VM:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
執行下列命令來設定新的預設核心,並指定對應的核心標題:
# grub2-set-default 'Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64'注意
將取代
Red Hat Enterprise Linux Server, with Linux 3.10.0-123.el7.x86_64為對應的功能表項標題。執行下列命令,驗證新的預設核心是否為所需的核心:
grub2-editenv list請確定 /etc/default/grub 檔案中的變數值
GRUB_DEFAULT設定為saved。 若要修改它,請確定您 重新產生 GRUB 組態檔 以套用變更。
RHEL 8/9 和 CentOS 8
執行下列命令來列出可用的核心:
ls -l /boot/vmlinuz-*執行下列命令來設定新的預設核心:
grubby --set-default /boot/vmlinuz-4.18.0-372.19.1.el8_6.x86_64注意
將取代
4.18.0-372.19.1.el8_6.x86_64為對應的核心版本。執行下列命令,驗證新的預設核心是否為所需的核心:
grubby --default-kernel
SLES 12/15、Ubuntu 18.04/20.04
執行下列命令,以列出 GRUB 組態檔中可用的核心:
Gen1 VM:
SLES 12/15:
cat /boot/grub2/grub.cfg | grep menuentryUbuntu 18.04/20.04:
cat /boot/grub/grub.cfg | grep menuentry
Gen2 VM:
cat /boot/efi/EFI/*/grub.cfg | grep menuentry
修改 /etc/default/grub 檔案中的變數值
GRUB_DEFAULT,以設定新的預設核心。 針對系統中安裝的最新核心版本,預設值為 0。 下一個可用的核心會設定為 「1>2」。vi /etc/default/grub GRUB_DEFAULT="1>2"注意
如需如何設定
GRUB_DEFAULT變數的詳細資訊,請參閱 SUSE 開機載入器 GRUB2 和 Ubuntu Grub2/Setup。 參考:最上層功能表項值為0,第一個最上層子功能表值為1,而每個巢狀功能表值會以0開頭。 例如,“1>2” 是第一個子功能表的第三個功能表項。重新產生 GRUB 組態檔以套用變更。 請遵循重新安裝 GRUB 中的指示 ,並重新產生對應的 Linux 散發套件和 VM 的 GRUB 配置檔 。
核心異常 - 未同步處理:VFS:無法在未知區塊上掛接根 fs(0,0)
此錯誤是因為最近的系統更新 (kernel) 所發生。 在以 RHEL 為基礎的散發套件中最常看到。 您可以從 Azure 序列主控台識別此問題。 您會看到下列任何錯誤訊息:
「核心恐慌 - 未同步處理:VFS:無法在未知區塊上掛接根 fs(0,0)」
[ 301.026129] Kernel panic - not syncing: VFS: Unable to mount root fs on unknown-block(0,0) [ 301.027122] CPU: 0 PID: 1 Comm: swapper/0 Tainted: G ------------ T 3.10.0-1160.36.2.el7.x86_64 #1 [ 301.027122] Hardware name: Microsoft Corporation Virtual Machine/Virtual Machine, BIOS 090008 12/07/2018 [ 301.027122] Call Trace: [ 301.027122] [<ffffffff82383559>] dump_stack+0x19/0x1b [ 301.027122] [<ffffffff8237d261>] panic+0xe8/0x21f [ 301.027122] [<ffffffff8298b794>] mount_block_root+0x291/0x2a0 [ 301.027122] [<ffffffff8298b7f6>] mount_root+0x53/0x56 [ 301.027122] [<ffffffff8298b935>] prepare_namespace+0x13c/0x174 [ 301.027122] [<ffffffff8298b412>] kernel_init_freeable+0x222/0x249 [ 301.027122] [<ffffffff8298ab28>] ? initcall_blcklist+0xb0/0xb0 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] [<ffffffff8237235e>] kernel_init+0xe/0x100 [ 301.027122] [<ffffffff82395df7>] ret_from_fork_nospec_begin+0x21/0x21 [ 301.027122] [<ffffffff82372350>] ? rest_init+0x80/0x80 [ 301.027122] Kernel Offset: 0xc00000 from 0xffffffff81000000 (relocation range: 0xffffffff80000000-0xffffffffbfffffff)“error: file '/initramfs-*.img' 找不到”
error:找不到檔案 '/initramfs-3.10.0-1160.36.2.el7.x86_64.img'。
這類錯誤表示未產生 initramfs 檔案、GRUB 組態檔在修補程式之後遺漏 initrd 專案,或 GRUB 手動設定錯誤。
重新啟動伺服器之前,建議您執行下列其中一個命令,以驗證 GRUB 組態和 /boot 內容。 請務必確保更新已完成,而且沒有遺漏 initramfs 檔案。
BIOS 型 - Gen1 系統
# ls -l /boot # cat /boot/grub2/grub.cfg以 UEFI 為基礎的 - Gen2 系統
# ls -l /boot # cat /boot/efi/EFI/*/grub.cfg
使用 Azure 修復 VM ALAR 腳本重新產生遺漏的 initramfs
使用 Azure Cloud Shell 執行下列 Bash 命令行來建立修復 VM。 如需詳細資訊,請參閱 使用 Azure Linux 自動修復 (ALAR) 來修正 Linux VM - initrd 選項。
az vm repair create --verbose -g $RGNAME -n $VMNAME --repair-username rescue --repair-password 'password!234' --copy-disk-name repairdiskcopy重新產生 initrd/initramfs 映射,並在遺漏 initrd 專案時重新產生 GRUB 組態檔。 若要這樣做,請執行下列命令:
az vm repair run --verbose -g $RGNAME -n $VMNAME --run-id linux-alar2 --parameters initrd --run-on-repair az vm repair restore --verbose -g $RGNAME -n $VMNAME執行還原命令之後,請重新啟動原始 VM,並驗證它是否能夠開機。
手動重新產生遺漏 initramfs
重要
識別開機問題的特定核心版本。 您可以從對應的核心異常錯誤擷取版本資訊。
請參閱下列螢幕快照作為範例。 核心異常錯誤顯示核心版本為 「3.10.0-1160.59.1.el7.x86_64」:
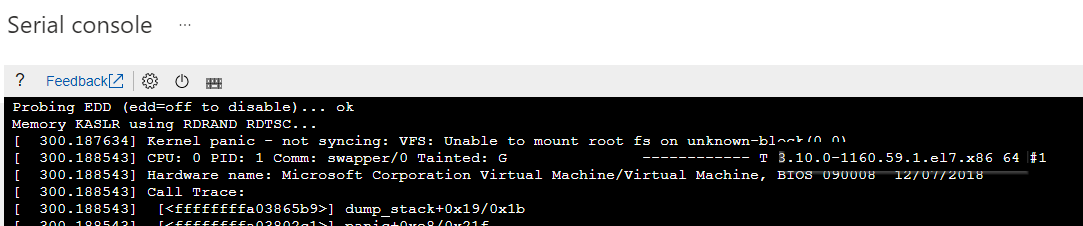
執行下列其中一個命令,以重新產生遺漏的 initramfs 檔案:
RHEL/CentOS/Oracle Linux 7/8
sudo depmod -a 3.10.0-1160.59.1.el7.x86_64 sudo dracut -f /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img 3.10.0-1160.59.1.el7.x86_64重要
將取代
3.10.0-1160.59.1.el7.x86_64為對應的核心版本。SLES 12/15
sudo depmod -a 5.3.18-150300.38.53-azure sudo dracut -f /boot/initrd-5.3.18-150300.38.53-azure 5.3.18-150300.38.53-azure重要
將取代
5.3.18-150300.38.53-azure為對應的核心版本。Ubuntu 18.04
sudo depmod -a 5.4.0-1077-azure sudo mkinitramfs -k -o /boot/initrd.img-5.4.0-1077-azure重要
將取代
5.4.0-1077-azure為對應的核心版本。
重新產生 GRUB 組態檔。 請遵循重新安裝 GRUB 中的指示,並重新產生對應的 Linux 散發套件和 VM 的 GRUB 配置檔
如果上述步驟是從修復 VM 執行,請遵循離線疑難解答中的步驟 3。 如果上述步驟是從 Azure 序列控制台執行,請遵循 在線疑難解答 方法。
透過最新的核心版本重新啟動您的 VM。
核心恐慌 - 未同步處理:嘗試終止 init
從 Azure 序列主控台找出此問題。 您會看到如下所示的輸出:
dracut Warning: Boot has failed. To debug this issue add "rdshell" to the kernel command line.
Kernel panic - not syncing: Attempted to kill init!
Pid: 1, comm: init Not tainted 2.6.32-754.17.1.el6.x86_64 #1
Call Trace:
[<ffffffff81558bfa>] ? panic+0xa7/0x18b
[<ffffffff81130370>] ? perf_event_exit_task+0xc0/0x340
[<ffffffff81086433>] ? do_exit+0x853/0x860
[<ffffffff811a33b5>] ? fput+0x25/0x30
[<ffffffff81564272>] ? system_call_after_swapgs+0xa2/0x152
[<ffffffff81086498>] ? do_group_exit+0x58/0xd0
[<ffffffff81086527>] ? sys_exit_group+0x17/0x20
[<ffffffff81564357>] ? system_call_fastpath+0x35/0x3a
[<ffffffff8156427e>] ? system_call_after_swapgs+0xae/0x152
這種核心異常是因為下列可能的原因而發生:
如需原因詳細數據和解決方案,請參閱下列各節。 請確定命令是從 chroot 環境內的修復/救援 VM 執行,如離線疑難解答中的指示。
遺漏重要的檔案和目錄
重要 Linux 檔案和目錄因人為錯誤而遺失。 例如,不小心刪除檔案或文件系統損毀。
將OS磁碟復本連結至修復 VM,並使用 chroot 掛接對應的文件系統之後,驗證 OS 磁碟內容。 您可以將輸出與執行相同 OS 版本之工作 VM 中的輸出進行比較。
ls -l / ls -l /usr/lib ls -l /usr/lib64 ls -lR / | more從備份還原遺失的檔案。 如需詳細資訊,請參閱 從 Azure 虛擬機備份復原檔案。 視遺失的檔案數目而定,執行完整 VM 還原可能比較好。 如需詳細資訊,請參閱如何在 Azure 入口網站 中還原 Azure VM 數據。
遺漏重要的系統核心連結庫和套件
重要系統核心連結庫、檔案或套件會從系統中刪除或損毀。 若要解決此問題,請重新安裝受影響的連結庫、檔案或套件。 此解決方案適用於以 RPM 為基礎的散發套件,例如 Red Hat/CentOS/SUSE VM。 針對其他Linux散發套件,建議您 從備份還原VM。
若要執行重新安裝,請遵循下列步驟:
使用與受影響 VM 相同的作業系統版本和世代的原始映像,建立救援 VM。
存取救援 VM 中的 chroot 環境,以針對問題進行疑難解答。
sudo chroot /rescue命令輸出會指出哪個連結庫遺失或損毀,如下所示:
/bin/bash: error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory確認救援 VM 中的所有系統套件及其對應的狀態。 比較輸出與執行相同 OS 版本的狀況良好 VM。
sudo rpm --verify --all --root=/rescue以下是命令輸出範例:
error: Failed to dlopen /usr/lib64/rpm-plugins/systemd_inhibit.so /lib64/librt.so.1: undefined symbol: __pthread_attr_copy, version GLIBC_PRIVATE S.5....T. c /etc/dnf/dnf.conf S.5....T. c /etc/ssh/sshd_config .M....... /boot/efi/EFI/BOOT/BOOTX64.EFI .M....... /boot/efi/EFI/BOOT/fbx64.efi .M....... /boot/efi/EFI/redhat/BOOTX64.CSV .M....... /boot/efi/EFI/redhat/mmx64.efi .M....... /boot/efi/EFI/redhat/shimx64-redhat.efi .M....... /boot/efi/EFI/redhat/shimx64.efi missing /run/motd.d .M....... g /var/spool/anacron/cron.daily .M....... g /var/spool/anacron/cron.monthly .M....... g /var/spool/anacron/cron.weekly missing /lib64/libc-2.28.so <------- .M....... /boot/efi/EFI/redhat S.5....T. c /etc/security/pwquality.conf輸出行
missing /lib64/libc-2.28.so與步驟 2 中的上一個錯誤有關,指出 遺漏 libc-2.28.so 套件。 不過, 可以修改 libc-2.28.so 套件。 在這裡情況下,輸出會顯示.M.....,missing而不是 。 libc-2.28.so 套件會參考為下列步驟中的範例。在救援 VM 中,確認哪個套件包含連結庫 /lib64/libc-2.28.so。
sudo rpm -qf /lib64/libc-2.28.soglibc-2.28-127.0.1.el8.x86_64注意
輸出會顯示需要重新安裝的套件,包括套件名稱和版本。 套件版本可能與受影響的 VM 上安裝的版本不同。
在受影響的 VM 中,確認已安裝哪個版本的 glibc 套件。
sudo rpm -qa --all --root=/rescue | grep -i glibcglibc-common-2.28-211.0.1.el8.x86_64 glibc-gconv-extra-2.28-211.0.1.el8.x86_64 glibc-2.28-211.0.1.el8.x86_64 <---- glibc-langpack-en-2.28-211.0.1.el8.x86_64下載套件 glibc-2.28-211.0.1.el8.x86_64。 您可以使用套件管理工具,或
yumdownloader視您執行的操作系統而定,從OS廠商的官方網站或zypper install --download-only <packagename>從救援 VM 下載。以下是使用
yumdownloader工具的範例:cd /tmp sudo yumdownloader glibc-2.28-211.0.1.el8.x86_64Last metadata expiration check: 0:03:24 ago on Thu 25 May 2023 02:36:25 PM UTC. glibc-2.28-211.0.1.el8.x86_64.rpm 8.7 MB/s | 2.2 MB 00:00在救援 VM 中重新安裝受影響的套件。
sudo rpm -ivh --root=/rescue /tmp/glibc-*.rpm --replacepkgs --replacefileswarning: /tmp/glibc-2.28-211.0.1.el8.x86_64.rpm: Header V3 RSA/SHA256 Signature, key ID ad986da3: NOKEY Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing... 1:glibc-2.28-211.0.1.el8 ################################# [100%]存取救援 VM 中的 chroot 環境,以驗證重新安裝。
sudo chroot /rescue關閉救援 VM,並將 OS 磁碟交換至受影響的 VM。
檔案許可權錯誤
因為發生人為錯誤而修改了整個系統的許可權(例如,有人在或其他重要的OS檔案系統上/執行chmod 777)。 若要解決此問題,請還原檔案許可權。 此解決方案適用於以 RPM 為基礎的散發套件,例如 Red Hat/CentOS/SUSE VM。 針對其他Linux散發套件,建議您 從備份還原VM。
若要還原檔案許可權,請在將OS磁碟的復本連結至修復VM並使用chroot掛接對應的檔案系統之後,執行下列命令:
rpm -a --setperms
rpm --setugids --all
chmod u+s /bin/sudo
chmod 660 /etc/sudoers.d/*
chmod 644 /etc/ssh/*.pub
chmod 640 /etc/ssh/*.key
注意
請勿在執行生產系統上執行此命令。
如果在手動復原對應的檔案許可權之後仍存在此問題,請從備份執行還原。
遺漏數據分割
在 /usr、/opt、、/var/home、 /tmp和 / 檔案系統分散到不同分割區的情況下,數據可能會因為分割區層級的問題而無法存取,這可能是因為分割區重設大小作業或其他作業期間發生錯誤所造成。
在此案例中,如果您記錄原始數據分割數據表配置,且每個原始分割區都有確切的開始和結束扇區,而且系統不會進一步修改,例如建立新的文件系統,使用與 fdisk(針對 MBR 分割區數據表)或 gdisk(適用於 GPT 數據分割數據表)等工具相同的原始版面配置來重新建立分割區,以存取遺漏的文件系統。
如果此方法無法運作,請 從備份執行還原。
SELinux 問題
錯誤的 SELinux 許可權可能會防止系統存取重要檔案。 若要解決此問題,請依照下列步驟執行︰
若要確認系統是否因為 SELinux 許可權錯誤而發生問題,請將 selinux=0 核心選項新增至 GRUB linux16 行以停用 SELinux 來啟動系統。
如果系統能夠開機,請執行下列命令以在開機時觸發 SELinux 重新標籤,並重新啟動系統:
touch /.autorelabel如果 VM 仍然無法開機,請從備份執行完整 VM 還原。 如需詳細資訊,請參閱如何在 Azure 入口網站 中還原 Azure VM 數據。
其他核心相關的開機問題
本文涵蓋 Azure 中識別的最常見 Linux 核心異常狀況。 如需常見核心異常案例的詳細資訊,請參閱 Azure Linux VM 中的核心異常 - 常見核心異常事件。
有一些其他重要的可能核心異常,可能會導致無開機或沒有安全殼層 (SSH) 案例。
請確定您從 chroot 環境內的修復 VM 執行任何命令,如離線疑難解答中所述。 如果系統已透過舊版核心版本開機,您也可以使用根許可權或 sudo從原始 VM 執行這些命令,如在線疑難解答中所述。
最近的核心升級
如果核心在最近的核心升級之後發生異常,請透過先前的核心版本開機 VM。 如需詳細資訊,請參閱 舊版核心版本的開機系統。
您也可以檢查 Linux 發行版廠商是否已發行較新的核心版本,並加以安裝。 如需如何安裝最新核心版本的詳細資訊,請參閱 核心更新程式。
最近的核心降級
如果核心在最近的核心降級之後啟動,請返回最新安裝的核心。 您也可以檢查 Linux 發行版廠商是否已發行較新的核心版本,並加以安裝。 如需如何安裝最新核心版本的詳細資訊,請參閱 核心更新程式。
若要透過最新的核心版本開機系統,請遵循手動變更預設核心版本中的指示,但選取 GRUB 功能表中所列的第一個核心。 在手動修改中 GRUB_DEFAULT ,您可以將值設定為 0,並重新產生對應的 GRUB 組態檔。
核心模組變更
您可能會遇到與新核心模組或遺漏核心模組相關的核心異常狀況。 若要取得造成問題的特定核心模組詳細數據(如果有的話),請檢查對應的核心異常追蹤。
若要驗證載入的核心模組和 /etc/modprobe.d/*.conf 檔案中已停用的核心模組,請執行下列其中一個命令:
RHEL/CentOS/Oracle Linux 7/8
lsinitrd /boot/initramfs-3.10.0-1160.59.1.el7.x86_64.img lsmod cat /etc/modprobe.d/*.conf重要
將取代
3.10.0-1160.59.1.el7.x86_64為對應的核心版本。SLES 12/15
lsinitrd /boot/initrd-5.3.18-150300.38.53-azure lsmod cat /etc/modprobe.d/*.conf重要
將取代
5.3.18-150300.38.53-azure為對應的核心版本。Ubuntu 18.04
lsinitramfs /boot/initrd.img-5.4.0-1077-azure lsmod cat /etc/modprobe.d/*.conf重要
將取代
5.4.0-1077-azure為對應的核心版本。
若要移除任何特定的核心模組,請執行下列命令,並 視需要重新產生 initramfs 。
rmmod <kernel_module_name>
如果系統服務使用特定的核心模組,請執行 或 systemctl stop <serviceName> 命令來systemctl disable <serviceName>停用它。
操作系統最近的設定變更
識別任何可能導致問題的最新核心組態變更。 若要解決問題,請調整這些設定或回復組態變更。
執行下列命令以尋找在下列任何檔案中設定的持續性核心參數:
cat /etc/systctl.conf
cat /etc/sysctl.d/*
執行下列命令來分析目前的核心參數及其目前值:
sysctl -a
注意
在執行中的系統上執行此命令,而不是從 chroot 環境執行此命令。
可能遺失的檔案
如需這類問題的詳細資訊,請參閱 遺漏重要的檔案和目錄。
檔案的許可權錯誤
如需這類問題的詳細資訊,請參閱 錯誤的檔案許可權。
遺漏數據分割
如需這類問題的詳細資訊,請參閱 遺漏分割區。
核心錯誤
從 Azure 序列主控台找出此問題。 這類問題看起來會像下列輸出:
[5275698.017004] kernel BUG at XXX/YYY.c:72!
[5275698.017004] invalid opcode: 0000 [#1] SMP
這種核心異常與核心 Bug 或第三方核心 Bug 相關聯。
若要修正核心錯誤,請使用核心 BUG 字串來搜尋廠商知識庫,並在系統執行的對應核心版本中尋找已知問題。 以下是一些重要的廠商資源:
-
此工具旨在於協助您診斷核心損毀。 當您輸入文字、 vmcore-dmesg.txt或包含一或多個核心 oop 訊息的檔案時,它會逐步引導您診斷核心當機問題。
-
若要取得 Red Hat 資源的存取權,請連結您的 Microsoft Azure 和 Red Hat 帳戶。 如需詳細資訊,請參閱 Azure 客戶如何存取 Red Hat 客戶入口網站Microsoft。
建議您將所有系統保持在最新狀態,以排除最新核心版本中已修正的任何潛在 BUG。 如需詳細資訊,請參閱核心更新程序。
如果供應商需要進一步分析,請設定並啟用 kdump 以產生核心傾印:
核心更新程式
若要安裝最新的可用核心版本,請執行下列其中一個命令:
RHEL / CentOS / Oracle Linux
yum update kernelSLES 12/15
zypper refresh zypper update kernel*Ubuntu 18.04/20.04
apt update apt install linux-azure
若要重新安裝特定的核心版本,請執行下列其中一個命令。 請確定您未透過您嘗試重新安裝的相同核心版本開機。 如需詳細資訊,請參閱 舊版核心版本的開機系統。
RHEL / CentOS / Oracle Linux
yum reinstall kernel-3.10.0-1160.59.1.el7.x86_64重要
將取代
3.10.0-1160.59.1.el7.x86_64為對應的核心版本。SLES 12/15
zypper refresh zypper install -f kernel-azure-5.3.18-150300.38.75.1.x86_64重要
將取代
kernel-azure-5.3.18-150300.38.75.1.x86_64為對應的核心版本。Ubuntu 18.04/20.04
apt update apt install --reinstall linux-azure=5.4.0.1091.68重要
將取代
5.4.0.1091.68為對應的核心版本。
若要更新系統並套用最新的可用變更,請執行下列其中一個命令:
RHEL / CentOS / Oracle Linux
yum updateSLES 12/15
zypper refresh zypper updateUbuntu 18.04/20.04
apt update apt upgrade
核心異常狀況可能與下列任何項目有關。 如需詳細資訊,請參閱 運行時間的核心異常狀況。
- 應用程式工作負載變更。
- 應用程式開發或應用程式錯誤。
- 效能相關問題等等。
下一步
如果特定開機錯誤不是核心相關的開機問題,請參閱針對 Azure Linux 虛擬機器 開機錯誤進行疑難解答,以取得進一步的疑難解答選項。
與我們連絡,以取得說明
如果您有問題或需要相關協助,請建立支援要求,或詢問 Azure community 支援。 您也可以向 Azure 意見反應社群提交產品意見反應。