探索解決方案架構
一起來檢閱您決定的機器學習作業 (MLOps) 工作流程架構,以了解驗證程式碼的位置和時機。
注意
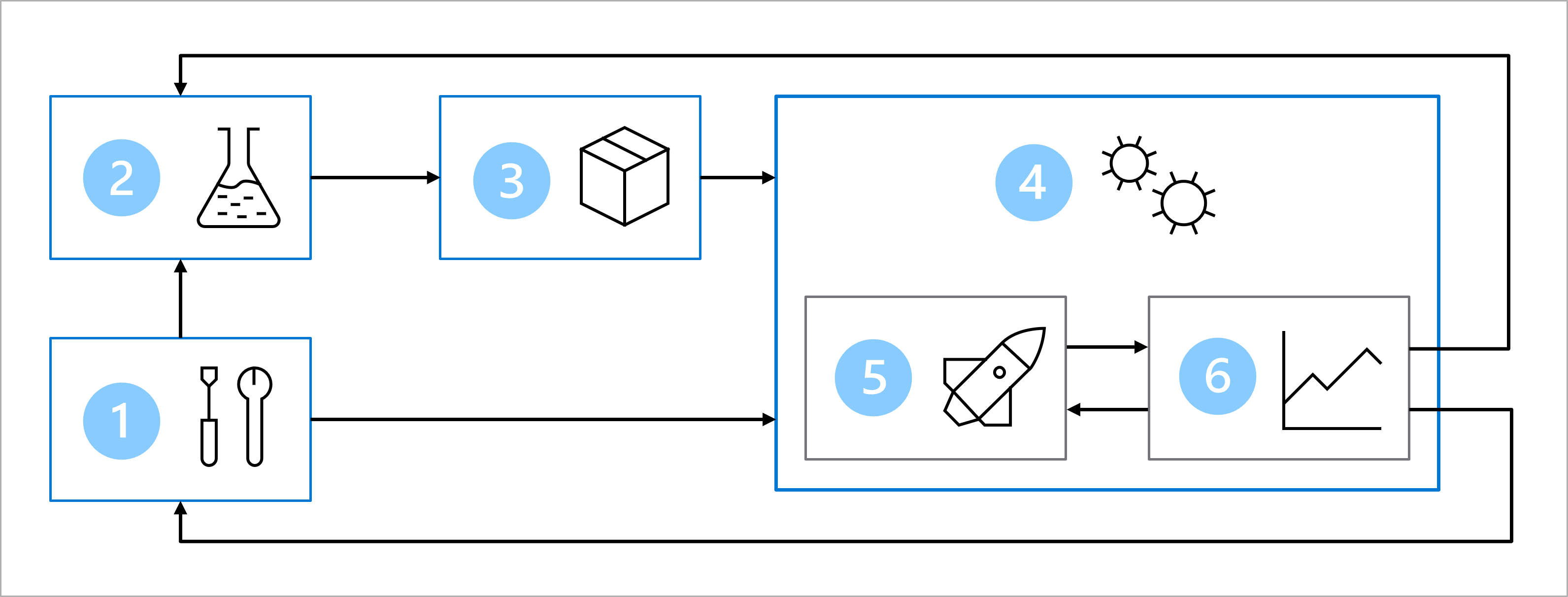
此圖表簡單呈現了 MLOps 架構。 若要檢視更詳細的架構,請於 MLOps (v2) 解決方案加速器中探索各種使用案例。
MLOps 架構的主要目標是建立穩固且可重現的解決方案。 若要達成目的,此架構包括:
- 設定:為解決方案建立所有必要的 Azure 資源。
- 模型開發 (內部迴圈):探索與處理資料來訓練與評估模型。
- 持續整合:封裝並註冊模型。
- 模型部署 (外部迴圈):部署模型。
- 持續部署:測試模型並升階至實際執行環境。
- 監視:監視模型與端點效能。
若要將模型從開發移至部署,您需要進行持續整合。 持續整合期間,您將封裝並註冊模型。 但在封裝模型前,您必須驗證用來定型模型的程式碼。
您與資料科學小組同意使用主幹型開發。 分支不僅會保護生產程式碼,也讓您可在與生產程式碼合併之前,自動驗證任何建議的變更。
讓我們來了解資料科學家的工作流程:
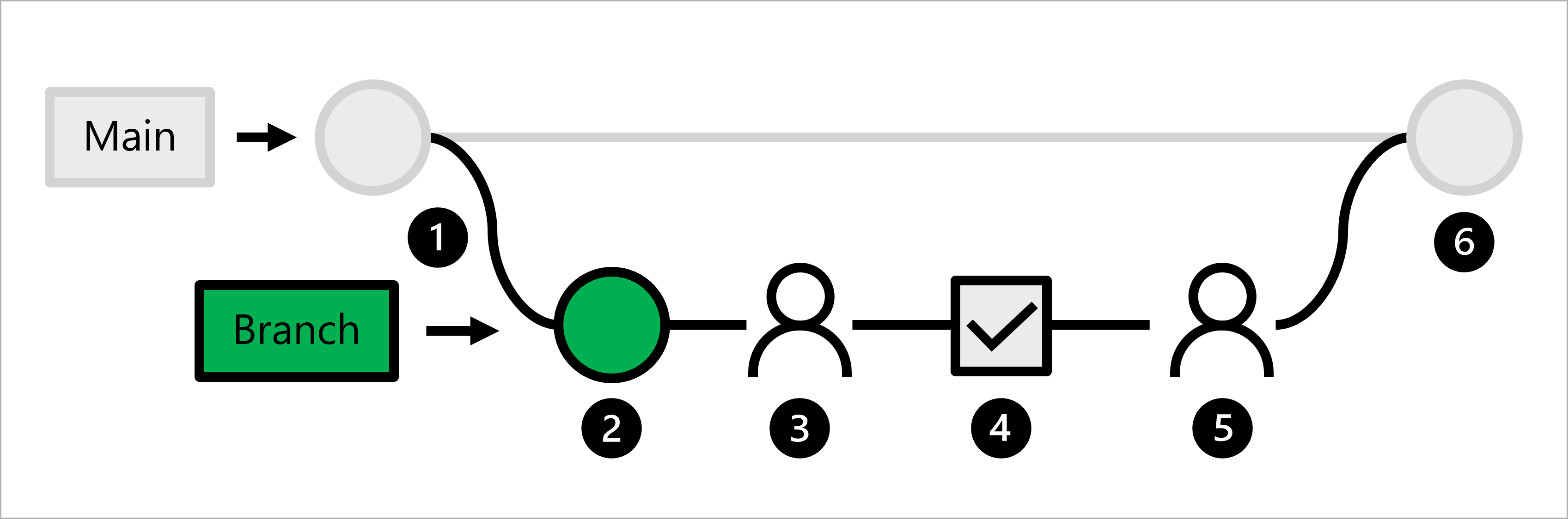
- 生產程式碼裝載於主要分支中。
- 資料科學家會建立用於模型開發的功能分支。
- 資料科學家會建立提取要求,提議將變更推送至主要分支。
- 建立提取要求時,會觸發 GitHub Actions 工作流程來驗證程式碼。
- 當程式碼通過 Linting 和單元測試時,主要資料科學家必須核准建議的變更。
- 主要資料科學家核准變更後,會合併提取要求,並根據變更更新主要分支。
身為機器學習工程師,您必須建立 GitHub Actions 工作流程,此流程會在建立提取要求時,執行 Linter 和單元測試來驗證程式碼。