最佳化差異資料表
Spark 是一種平行處理架構,資料儲存在一個或多個背景工作角色節點上。 此外,Parquet 檔案是不可變的,每次更新或刪除都會寫入新檔案。 此過程可能會導致 Spark 將資料儲存在大量的小檔案中,這稱為「小檔案問題」。這意味著對大量資料的查詢可能會執行緩慢,甚至無法完成。
OptimizeWrite 函式
OptimizeWrite 是 Delta Lake 的一項功能,可減少檔案被寫入時的檔案數目。 它不會寫入許多的小檔案,而是會寫入較少的大檔案。 這有助於防止「小檔案問題」並確保效能不會下降。
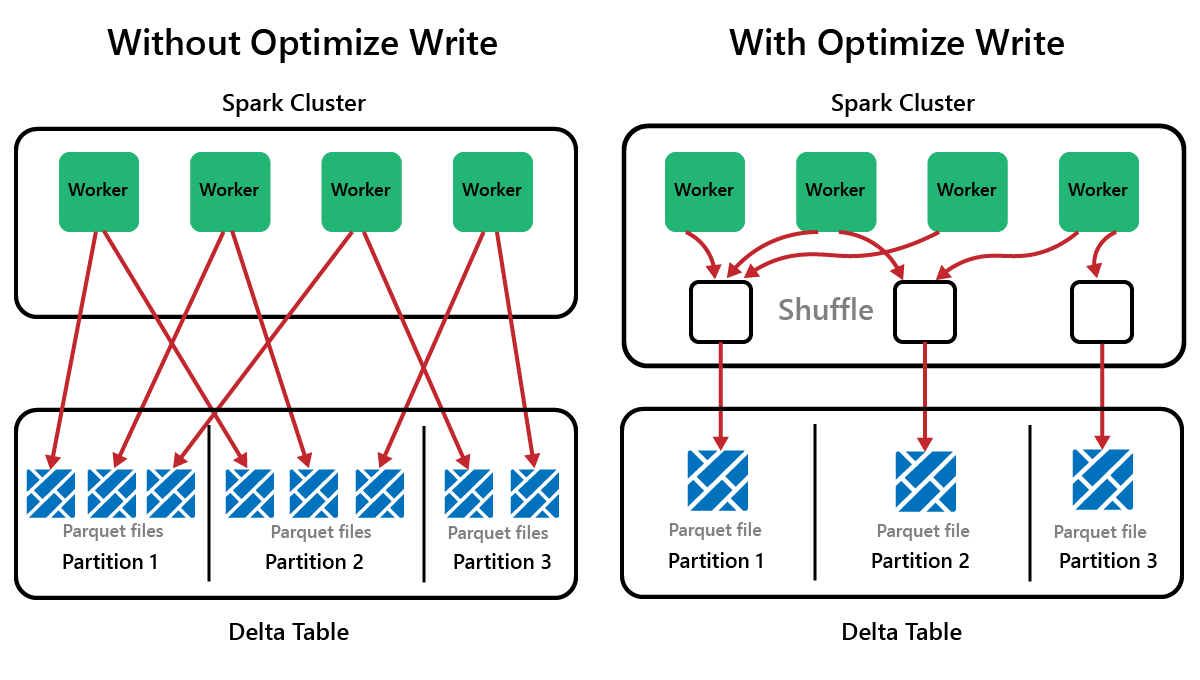
在 Microsoft Fabric 中,預設會啟用 OptimizeWrite。 您可以在 Spark 工作階段層級啟用或停用它:
# Disable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", False)
# Enable Optimize Write at the Spark session level
spark.conf.set("spark.microsoft.delta.optimizeWrite.enabled", True)
print(spark.conf.get("spark.microsoft.delta.optimizeWrite.enabled"))
注意
OptimizeWrite 也可以在資料表屬性中和針對個別寫入命令設定。
最佳化
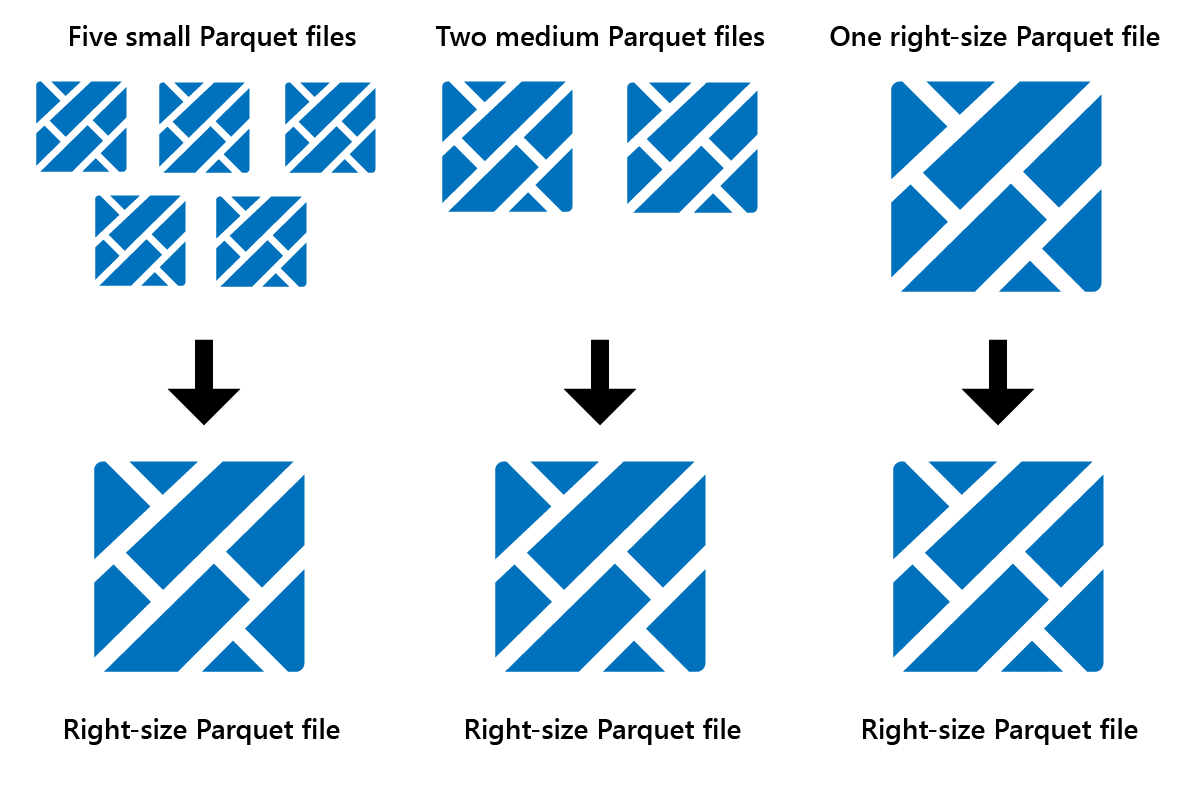
Optimize 是一項資料表維護功能,可將小 Parquet 檔案合併成較少的大檔案。 您可能會在載入大型資料表後執行 Optimize,從而導致:
- 較少的大檔案
- 更好的壓縮
- 跨節點有效率的資料分佈
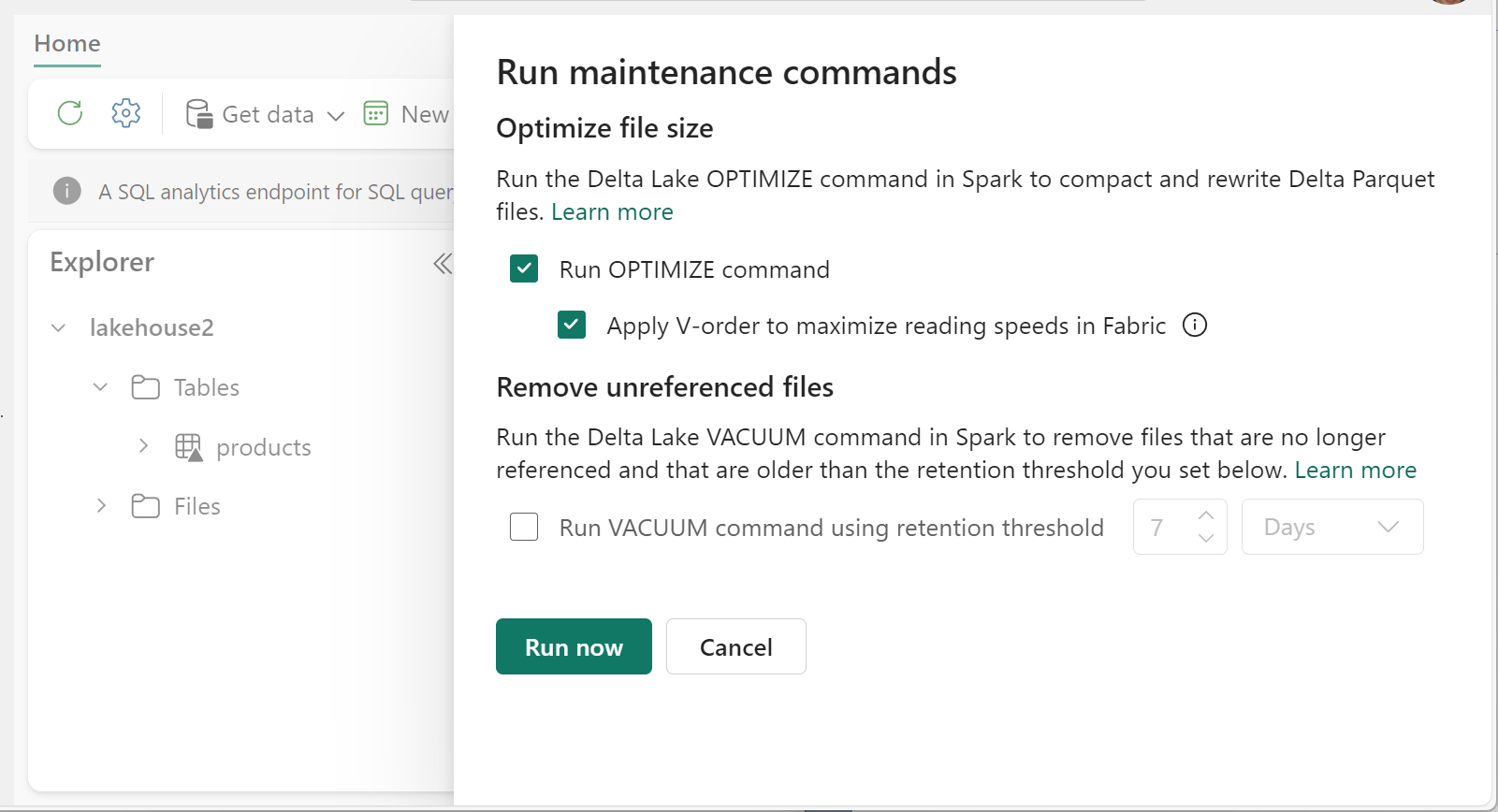
若要執行 Optimize:
- 在 Lakehouse Explorer 中,選取資料表名稱旁的 ... 功能表,然後選取 [維護]。
- 選取 [執行 OPTIMIZE 命令]。
- 選擇性地選取 [在 Fabric 中套用 V-order 以最大化讀取速度]。
- 選取 [立即執行]。
V-Order 函式
執行 Optimize 時,您可以選擇性執行 V-Order,它是針對 Fabric 中的 Parquet 檔案格式所設計的。 V-Order 可實現閃電般的快速讀取,具備類似記憶體中的資料存取時間。 它還提高了成本效率,因為它減少了讀取期間的網路、磁碟和 CPU 資源的使用。
V-Order 預設會在 Microsoft Fabric 中啟用,並在寫入資料時套用。 它會產生大約 15% 的小型額外負荷,使得寫入速度稍微慢一些。 不過,V-Order 可以更快地從 Microsoft Fabric 計算引擎 (例如 Power BI、SQL、Spark 等) 中讀取資料。
在 Microsoft Fabric 中,Power BI 和 SQL 引擎會使用 Microsoft Verti-Scan 技術,該技術會充分利用 V-Order 最佳化來加快讀取速度。 Spark 和其他引擎不會使用 VertiScan 技術,但仍受益於 V-Order 最佳化,讀取速度提高約 10%,有時高達 50%。
V-Order 的運作方式是對 Parquet 檔案套用特殊排序、資料列群組散發、字典編碼和壓縮。 它 100% 相容於開放原始碼 Parquet 格式,所有 Parquet 引擎都可以讀取它。
V-Order 可能對寫入密集型案例 (例如僅讀取一次或兩次資料的暫存資料存放區) 沒有好處。 在這些情況下,停用 V-Order 可能會減少資料擷取的整體處理時間。
透過執行 OPTIMIZE 命令,使用資料表維護功能將 V-Order 套用至個別的資料表。
真空
VACUUM 命令可讓您移除舊的資料檔。
每次完成更新或刪除時,都會建立一個新的 Parquet 檔案,並在交易記錄中建立一個項目。 舊的 Parquet 檔案會被保留以實現時光旅行,這意味著 Parquet 檔案會隨著時間逐漸累積。
VACUUM 命令會移除舊的 Parquet 資料檔,但不會移除交易記錄。 當您執行 VACUUM 時,您無法回溯到早於保留期間的時間點來進行時光旅行。
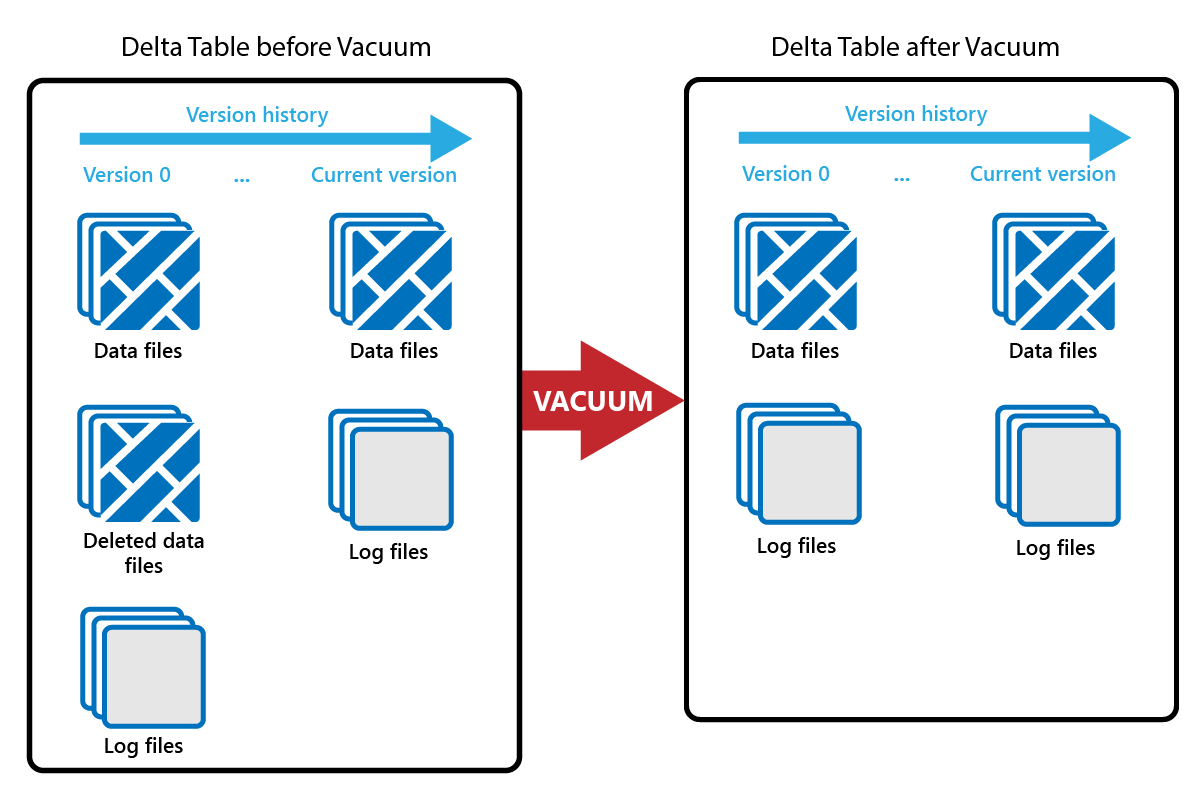
目前未在交易記錄中參考的資料檔案以及早於指定保留期間的資料檔案會透過執行 VACUUM 永久刪除。 根據如下因素來選擇您的保留期間:
- 資料保留需求
- 資料大小和儲存成本
- 資料變更頻率
- 法規需求
預設的保留期間為 7 天 (168 小時),系統會阻止您使用更短的保留期間。
您可以根據需求隨時執行 VACUUM,或者透過 Fabric 筆記本設定排程來執行 VACUUM。
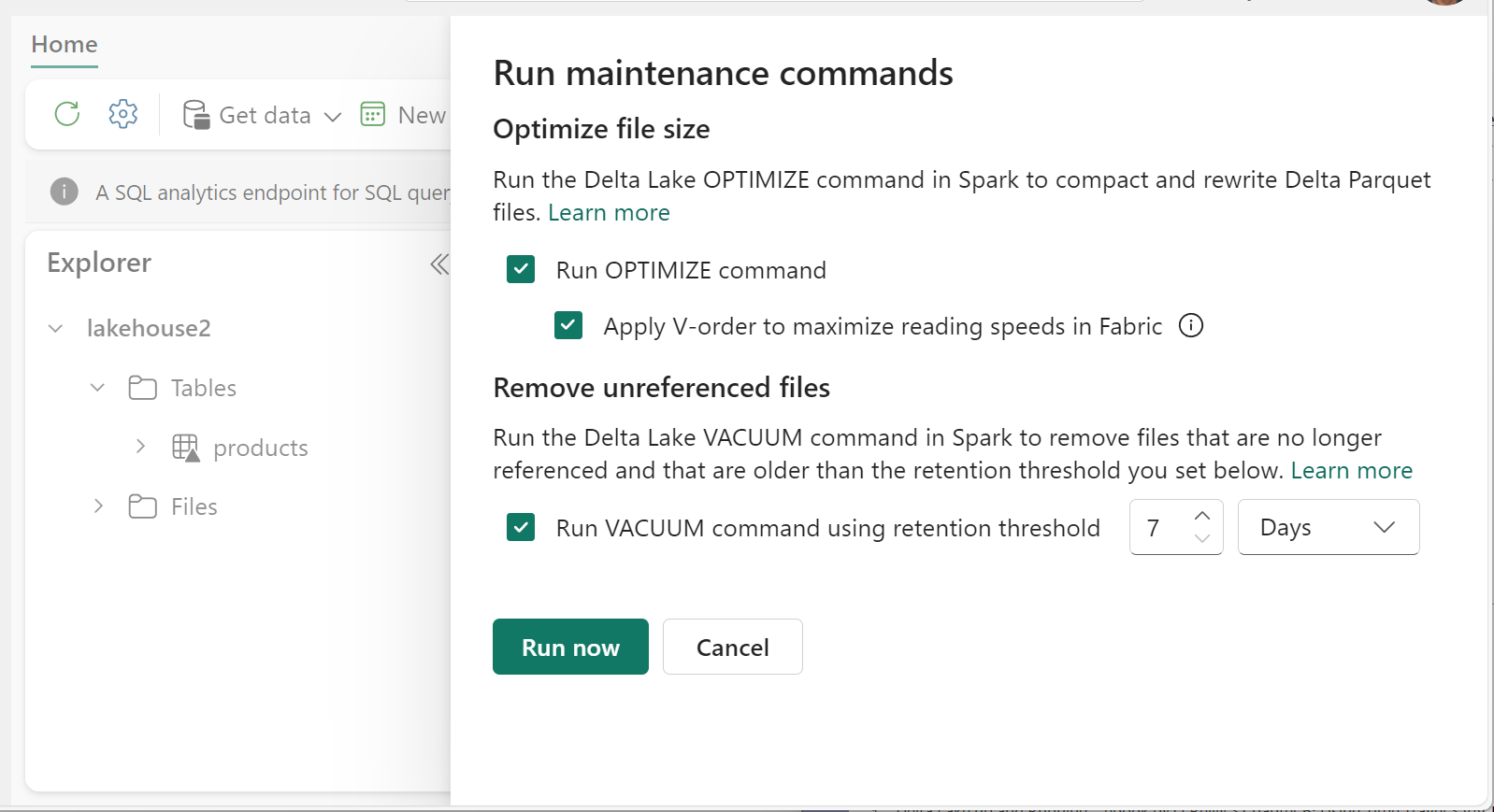
使用資料表維護功能以在個別的資料表上執行 VACUUM:
- 在 Lakehouse Explorer 中,選取資料表名稱旁的 ... 功能表,然後選取 [維護]。
- 選取 [使用保留閾值執行 VACUUM 命令] 並設定保留閾值。
- 選取 [立即執行]。
您也可以在筆記本中以 SQL 命令的形式來執行 VACUUM:
%%sql
VACUUM lakehouse2.products RETAIN 168 HOURS;
VACUUM 會認可至 Delta 交易記錄,因此您可以在 DESCRIBE HISTORY 中檢視先前的執行。
%%sql
DESCRIBE HISTORY lakehouse2.products;
對 Delta 資料表進行資料分割
Delta Lake 可讓您將資料組織成分割區。 這可能可以透過啟用「資料略過」來提高效能,資料略過會根據物件的中繼資料來略過無關的資料物件,進而提高效能。
試想一個儲存大量銷售資料的情況。 您可以按年份對銷售資料進行資料分割。 分割區儲存在名為 "year=2021"、"year=2022" 等的子資料夾中。如果您只想報告 2024 年的銷售資料,則可以略過其他年份的分割區,以提高讀取效能。
然而,對少量資料進行資料分割可能會降低效能,因為它會增加檔案數目,而且可能會加劇「小檔案問題」。
在以下情況下使用資料分割:
- 您擁有非常大量的資料。
- 資料表可以分割成幾個大的分割區。
在以下情況下不要使用資料分割:
- 資料量較小。
- 分割資料行具有高基數,因為這會建立大量的分割區。
- 分割資料行會產生多個層級。
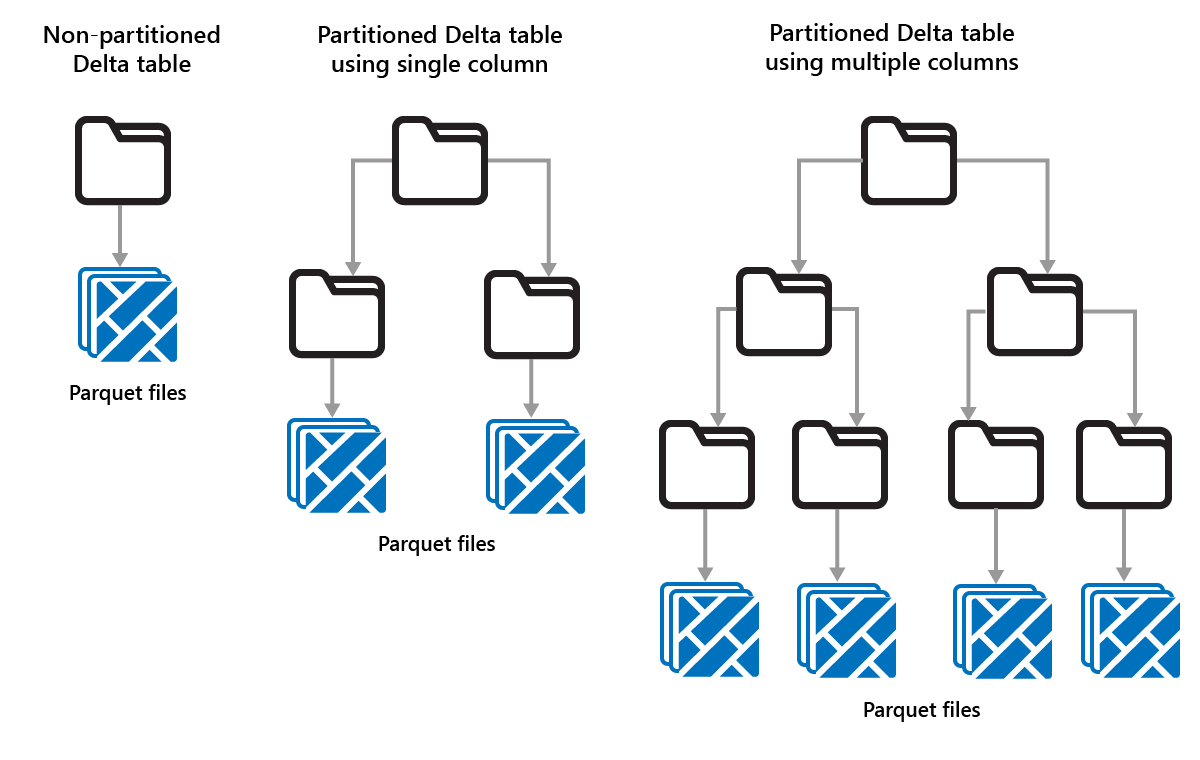
分割區是一種固定的資料佈局,並不會根據不同的查詢模式動態調整。 在考慮如何使用分割區時,請考慮資料的使用方式及其細微性。
在此範例中,包含產品資料的 DataFrame 會依「類別」進行分割:
df.write.format("delta").partitionBy("Category").saveAsTable("partitioned_products", path="abfs_path/partitioned_products")
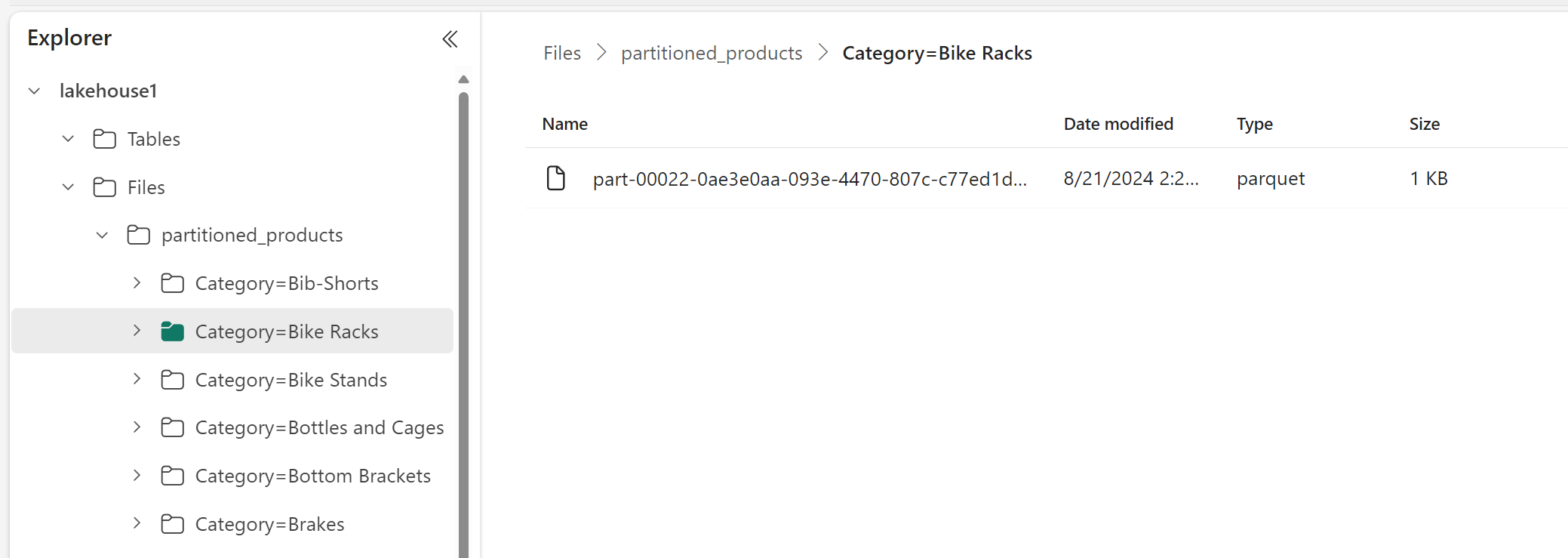
在 Lakehouse Explorer 中,您可以看到資料是一個分割的資料表。
- 該資料表有一個資料夾,名為 "partitioned_products"。
- 每個類別都有子資料夾,例如 "Category=Bike Racks" 等等。
我們可以使用 SQL 來建立類似的分割資料表:
%%sql
CREATE TABLE partitioned_products (
ProductID INTEGER,
ProductName STRING,
Category STRING,
ListPrice DOUBLE
)
PARTITIONED BY (Category);