選擇適當的計算目標
在 Azure Machine Learning 中,計算目標 是執行作業的實體或虛擬電腦。
瞭解可用的計算類型
Azure Machine Learning 支援多種類型的計算,以進行實驗、定型和部署。 藉由有多個類型的計算,您可以針對您的需求選取最適當的計算目標類型。
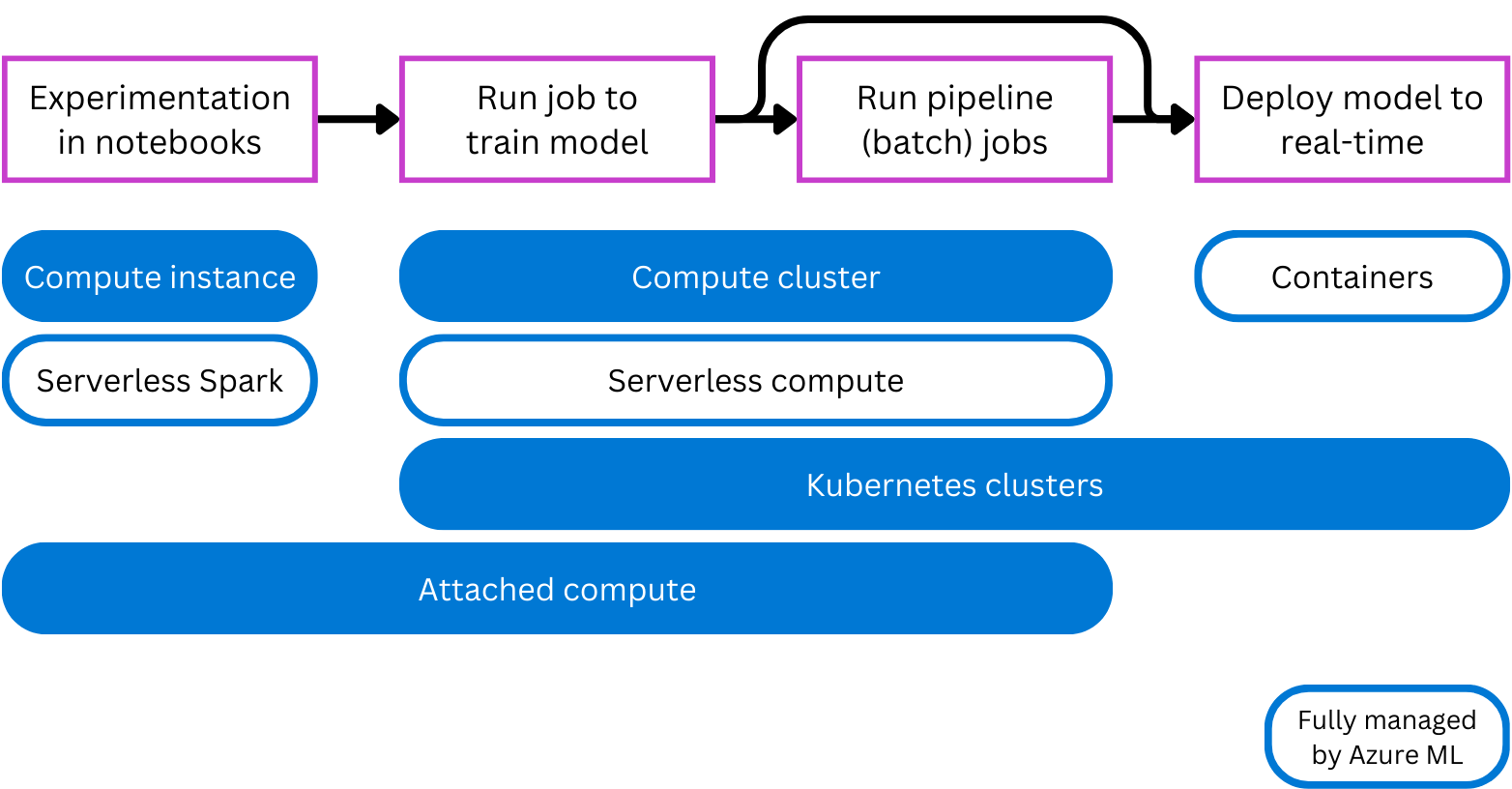
- 計算實例:行為類似於虛擬機,主要用於執行筆記本。 它非常適合 實驗。
- 計算叢集:多節點虛擬機群集,自動擴展或縮減以滿足需求。 執行需要處理大量數據之腳本的符合成本效益的方式。 叢集也可讓您使用平行處理來散發工作負載,並減少執行腳本所需的時間。
- Kubernetes 叢集:以 Kubernetes 技術為基礎的叢集,讓您更充分掌控如何設定和管理計算。 您可以連結適用於雲端計算的自我管理 Azure Kubernetes (AKS) 叢集,或內部部署工作負載的 Arc Kubernetes 叢集。
- 附加的計算:允許您將現有的計算資源,如 Azure 虛擬機器或 Azure Databricks 叢集,附加至您的工作區。
- 無伺服器運算:您可以用於訓練工作的完全受控隨需運算。
注意
Azure Machine Learning 可讓您選擇建立和管理自己的計算,或使用完全由 Azure Machine Learning 管理的計算。
何時要使用哪種類型的計算?
一般而言,使用計算目標時,您可以遵循一些最佳做法。 若要瞭解如何選擇適當的計算類型,會提供數個範例。 請記住,您使用的計算類型一律取決於您的特定情況。
選擇實驗的計算目標
假設您是數據科學家,並要求您開發新的機器學習模型。 您可能有一小部分的訓練數據可以用來進行實驗。
在實驗和開發期間,您偏好在 Jupyter Notebook 中工作。 筆記本的使用體驗最能從持續運作的運算中受益。
許多數據科學家都熟悉在其本機裝置上執行筆記本程式。 Azure Machine Learning 所管理的雲端替代專案是 計算實例。 或者,如果您想要使用 Spark 的分散式計算能力,您也可以選擇 Spark 無伺服器計算 在筆記本中執行 Spark 程式代碼。
選擇生產環境的計算目標
經過實驗後,您可以執行 Python 腳本來訓練模型,以準備進入生產環境。 當您想要在一段時間內持續重新定型模型時,腳本將更容易自動化並排程。 您可以將腳本執行為管線作業。
移至生產環境時,您希望計算目標準備好處理大量數據。 您使用的數據越多,機器學習模型可能就越好。
使用腳本定型模型時,您需要隨選計算目標。 計算叢集 在需要執行腳本時會自動擴展,當腳本執行完成時會自動縮減。 如果您想要不需要建立和管理的替代方案,您可以使用 Azure Machine Learning 的 無伺服器計算。
選擇用於部署的計算目標
使用模型產生預測時所需的計算類型取決於您想要批次或實時預測。
針對批次預測,您可以在 Azure Machine Learning 中執行管線作業。 計算目標,例如計算叢集和 Azure Machine Learning 的無伺服器計算,非常適合管線作業,因為它們是隨選且可調整的。
當您想要即時預測時,您需要持續執行的計算類型。 因此,即時部署受益於更輕量型(因此更有成本效益的)計算。 容器非常適合用於即時部署。 當您將模型部署至受控在線端點時,Azure Machine Learning 會建立及管理容器,讓您執行模型。 或者,您可以連結 Kubernetes 叢集來管理必要的計算,以產生實時預測。