評估分類模型
機器學習有很大一部分與評估模型的運作成效有關。 此評估會在訓練期間進行以協助塑造模型,以及在訓練之後進行以協助我們判斷模型是否沒有問題而可以在真實世界中使用。 和迴歸模型一樣,分類模型也需要進行評估,不過我們用來進行評估的方式有時會稍微複雜一些。
成本複習
請記住,我們會在訓練期間計算模型的表現有多糟糕,並將其稱為成本或損失。 例如在線性迴歸中,我們往往會使用稱為平均平方誤差 (MSE) 的計量。 MSE 的計算方式是比較預測結果和實際標籤、將兩者的差額平方,再求算結果的平均值。 我們可以使用 MSE 來調整模型,以及報告其運作成效。
分類的成本函式
分類模型會根據其輸出機率 (例如 40% 的機率會雪崩) 或最終標籤 (no avalanche 或 avalanche) 來獲得評價。 使用輸出機率在定型期間可能會有好處。 模型的微小變更會反映在概率的變化中,即使它們不足以改變最終的決定。 如果我們想要估計模型在真實世界中會有怎樣的表現,那麼對成本函式使用最終標籤會更實用。 例如,在測試集上。 因為在真實世界使用時,我們會使用最終標籤而非機率。
對數損失
針對簡單分類,對數損失是最受歡迎的成本函式之一。 對數損失會套用至輸出機率。 和 MSE 類似,少量的錯誤會導致較小的成本,中等數量的錯誤則會導致較大的成本。 我們在下列圖表中繪製了對數損失,目標對象則是正確答案為 0 (false) 的標籤。
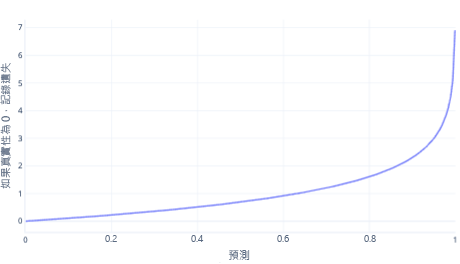
x 軸顯示可能的模型輸出 (機率從 0 到 1),y 軸顯示成本。 如果模型具有高信賴度,則正確的回應為 0 (例如預測 0.1)。 這樣,成本就會很低,因為在這個執行個體中,正確的回應是 0。 如果模型確信地預測出錯誤的結果 (例如,預測 0.9),則成本會變高。 事實上,由於 x=1 時的成本過於高昂,因此我們已將此處的 x 軸裁切至 0.999 以維持圖表的可讀性。
為何不使用 MSE?
MSE 和對數損失是類似的計量。 有一些複雜的原因導致羅吉斯迴歸偏好使用對數損失,但其中也有一些比較簡單的原因。 例如,對數損失懲罰錯誤答案的強度遠高於 MSE。 例如,在下列圖表中,如果正確答案是 0,則對數損失針對 0.8 以上的預測會有比 MSE 高的成本。
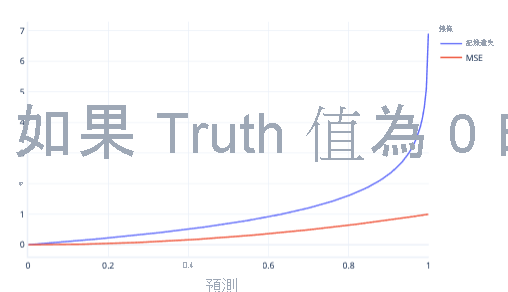
以這種方式擁有較高的成本,可協助模型因為線條的漸層較困難而更快速地學習。 同樣地,記錄遺失可協助模型更有信心地提供正確的答案。 請注意,在上一個繪圖中,小於 0.2 的值 MSE 成本很小,且漸層幾乎是平面的。 此關聯性會讓接近正確的模型訓練緩慢。 對數損失則會針對這些值提供較陡峭的梯度,而能讓模型學習得更快。
成本函式的限制
使用單一成本函式來為模型進行人工評估時,因為這個成本函式不會告訴您模型犯了哪種錯誤,所以使用時一定會受到限制。 例如,想一下我們的雪崩預測案例。 較高的對數損失值可能意味著模型在沒有雪崩的情況下反復預測雪崩。 或者,這可能表示重複無法預測發生的雪崩。
若要更加了解我們的模型,使用多個數字來評估模型是否表現良好會更容易一些。 我們在其他學習教材中涵蓋這個較大的主題,但我們會在下列練習中加以說明。