了解 Apache Spark
Apache Spark 是分散式資料處理架構,可協調叢集中多個處理節點的工作,以進行大規模的資料分析。
Spark 的運作方式
Apache Spark 應用程式會在叢集上以獨立的處理序組合來執行,並由主程式 (稱為驅動程式) 中的 SparkContext 物件來協調。 SparkCoNtext 會連線到叢集管理員,而叢集管理員會使用 Apache Hadoop YARN 實作,跨應用程式佈建資源。 連線後,Spark 會取得叢集中節點的執行程式,以執行應用程式的程式碼。
SparkCoNtext 會在叢集節點上執行主要函數和平行作業,並收集作業的結果。 節點會對檔案系統讀取和寫入資料,並將轉換的記憶體內部資料快取為彈性分散式資料集 (RDD)。
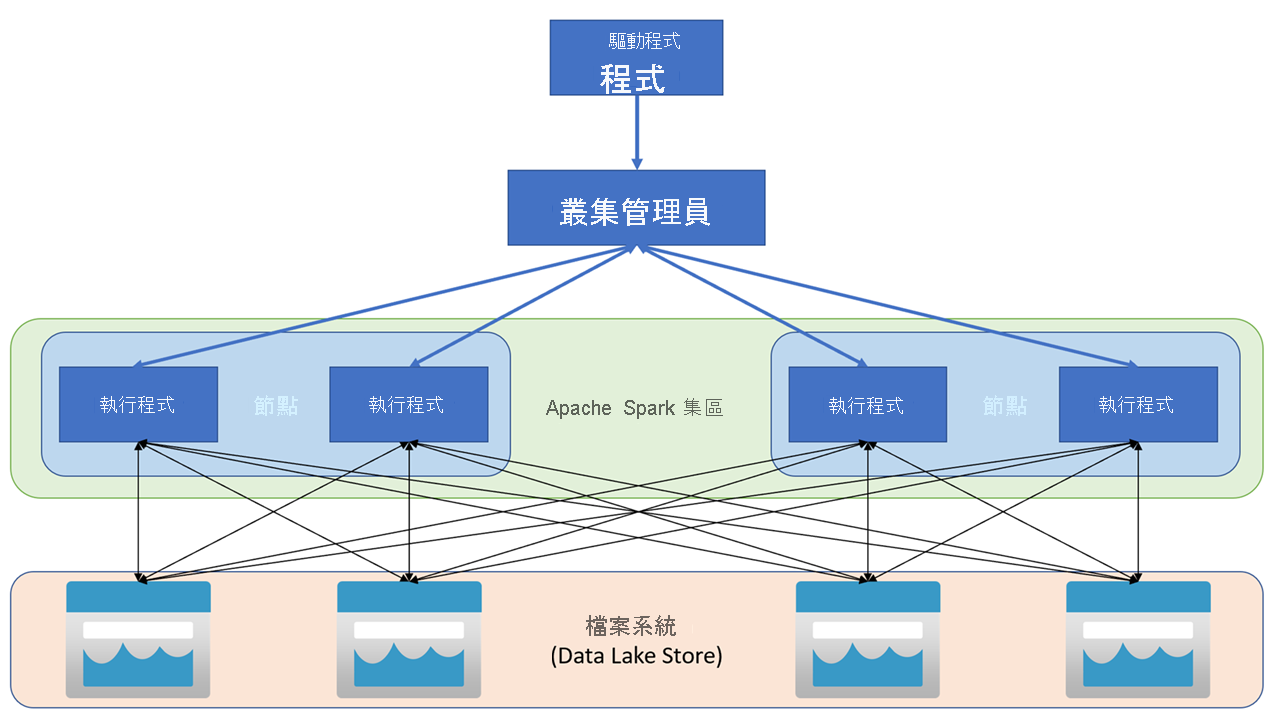
SparkCoNtext 負責將應用程式轉換為有向非循環圖 (DAG)。 此圖包含在節點上的執行程式處理序中執行的個別工作。 每個應用程式都會取得自己的執行程式處理序,而這些處理序會在整個應用程式的持續時間保持運作,並且在多個執行緒中執行工作。
Azure Synapse Analytics 中的 Spark 集區
在 Azure Synapse Analytics 中,叢集會實作為 Spark 集區,用於為 Spark 作業提供執行階段。 您可使用 Azure 入口網站或在 Azure Synapse Studio 中,於 Azure Synapse Analytics 工作區中建立一或多個 Spark 集區。 定義 Spark 集區時,您可指定集區的設定選項,包含:
- Spark 集區的名稱。
- 用於集區中節點的虛擬機器大小 (VM),包含使用硬體加速啟用 GPU 的節點的選項。
- 集區中的節點數目,無論集區大小是否固定,個別節點可動態上線以自動調整叢集規模;在此情況下,您可指定作用中節點數的上限與下限。
- 集區中要使用的 Spark 執行階段版本;必須指定個別元件的版本,例如 Python、JAVA 和要安裝的其他元件。
提示
如需 Spark 集區設定選項的詳細資訊,請參閱 Azure Synapse Analytics 說明文件內 Azure Synapse Analytics 中的 Apache Spark 集區設定。
Azure Synapse Analytics 工作區中的 Spark 集區無伺服器會隨需啟動,並於閒置時停止。