正規化和標準化
功能調整是一種技術,可以變更功能的值範圍。 使用這些技術有助於模型在學習時更快速且更扎實。
正規化與標準化
正規化意指調整值的大小,讓所有的值都落在特定範圍內,通常為 0–1。 例如,如果您有民眾 0 歲、50 歲和 100 歲的年齡清單,即可將年齡除以 100,得到正規化的值 0、0.5 和 1。
標準化大同小異,差別是先減去各值的平均值,再除以標準差。 如果您不熟悉標準差,沒關係,標準差即標準化後,平均值是 0,且 95% 的值落在 -2 到 2 之間。
調整資料大小的方法還很多,但我們目前並不需要知道這些方法的細微差異。 我們來看看使用正規化或標準化的原因為何。
值為什麼需要調整?
有許多原因會讓我們需要在開始訓練之前先將資料正規化或標準化。 您可以利用範例輕鬆加以了解。 假設我們想要為模型定型,以預測犬隻是否能在雪地裡順利工作。 我們的資料在下圖中以點表示,而我們想尋找的趨勢線則以實線表示:
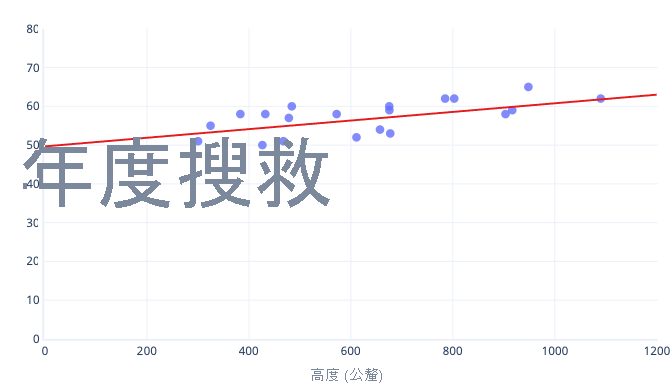
值的調整可提供更好的學習起點
上圖中的最佳趨勢線有兩個參數:截距 (值為 50,在 x=0 時的線),以及斜率 (值為 0.01);每 1000 公釐會讓搜救次數增加 10 次。 讓我們假設,我們一開始訓練時,這兩個參數的初始估計值都是 0。
如果在反覆定型時,平均每次反覆定型會讓參數改變大約 0.01,則在找到截距之前,至少會反覆定型 5000 次:50/0.01=5000 次反覆定型。 標準化可以讓這個最佳截距接近 0,亦即我們可以更快找到截距。 例如,如果我們將標籤 (年度搜救次數) 和我們的特徵 (身高) 減去平均值,則截距會是 -0.5,而不是 50,找到截距的速度會快上 100 倍。
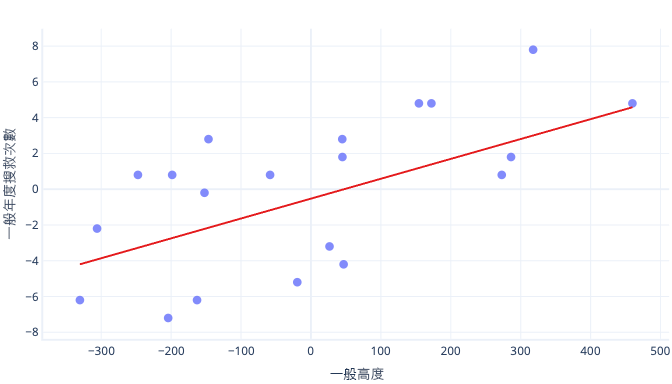
當一開始猜測的值離目標值很遠時,還有其他原因會讓複雜的模型定型速度緩慢,但其解決方法還是一樣:將特徵值偏移到比較靠近一開始猜測的值。
標準化讓參數以相同的速度定型
在新的偏移資料中,我們的理想偏移是 -0.5,理想斜率是 0.01。 雖然偏移有助於提升速度,但偏移的定型速度仍會比斜率的定型慢上許多。 這可能會拖累定型速度,讓定型變得不穩定。
例如,我們一開始猜測的偏移和斜率都是 0。 如果每次以 0.1 反覆變更參數,我們很快會找出位移,但很難找出正確的斜率,因為斜率增加太大 (0 + 0.1 > 0.01),而且會超過理想值。 我們可以將調整量縮小,但這樣會讓找出截距所花費的時間變多。
如果我們調整身高的特徵會怎麼樣呢?
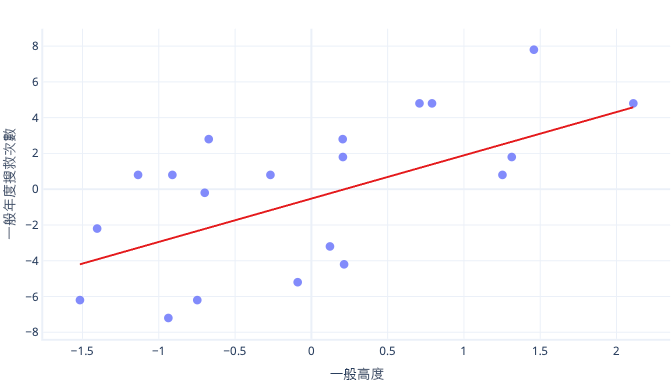
趨勢線的斜率現在是 0.5。 請注意 X 軸。 我們的最佳截距 (-0.5) 和斜率 (0.5) 處於相同級別了! 現在您可以輕鬆地挑選合理的步階大小 (也就是梯度下降時更新參數的速度)。
值的調整有助處理多重特徵
當我們使用多個特徵時,讓這些特徵處於不同級別可能會在調整時造成問題,就像於我們剛才在截距和斜率範例中所看到的情形。 例如,如果我們要定型的模型同時接受以公釐為單位的身高和以公噸為單位的重量,許多種類的模型都很難意識到重量特徵的重要性,原因就是其與身高特徵對比之下數值太小。
值一律需要調整嗎?
值不一定要調整。 某些種類的模型 (包括前述含直線的模型) 無需梯度下降之類的反覆程序即可配適,因此不會在意大小不適當的特徵。 其他模型確實需要調整,才能順利定型,但模型的程式庫通常會自動執行特徵調整。
一般來說,正規化或標準化真正的缺點是,更難解譯模型,及必須撰寫較多程式碼。 基於這個理由,特徵調整是建立機器學習模型的標準組件。