在本機驗證您的程式碼
每當您在機器學習專案中變更任何程式碼時,您會想要驗證程式碼和模型品質。
在持續整合期間,您會為應用程式建立和驗證資產。 身為資料科學家,您可能會著重建立用於資料準備和模型定型的指令碼。 機器學習工程師稍後會在管線中,使用指令碼將這些程序自動化。
如要驗證您的指令碼,可執行兩個常見的工作:
- Lint 分析:檢查 Python 或 R 指令碼中的程式設計或樣式錯誤。
- 單元測試:檢查指令碼內容的效能。
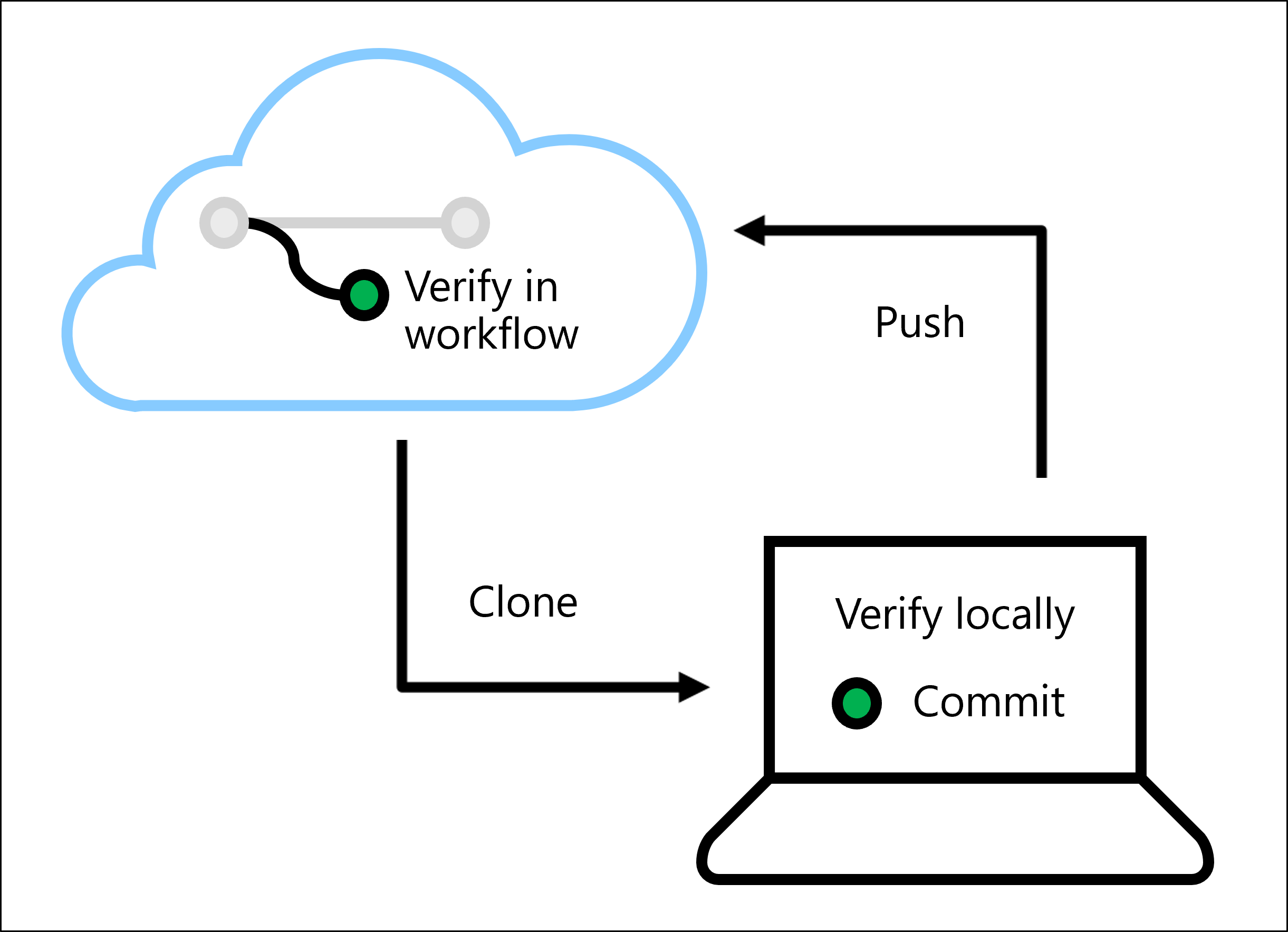
您可藉由驗證程式碼,在部署模型時防止發生錯誤或問題。 您可在本機驗證程式碼,方法是在 IDE 中執行 Linter 和單元測試,例如 Visual Studio Code。
您也可以使用 Azure Pipelines 或 GitHub Actions,在自動化工作流程中執行 Linter 和單元測試。
您將瞭解如何在 Visual Studio Code 中執行 Lint 分析和單元測試。
針對程式碼執行 Lint
程式碼品質取決於您與小組皆同意的標準。 為確保符合同意的品質,您可執行 Linter 以檢查程式碼是否符合小組的標準。
視您使用的程式碼語言而定,有數個選項可為您的程式碼執行 Lint。 例如,若您使用 Python,則可以使用 Flake8 或 Pylint。
使用 Flake8 對程式碼執行 Lint
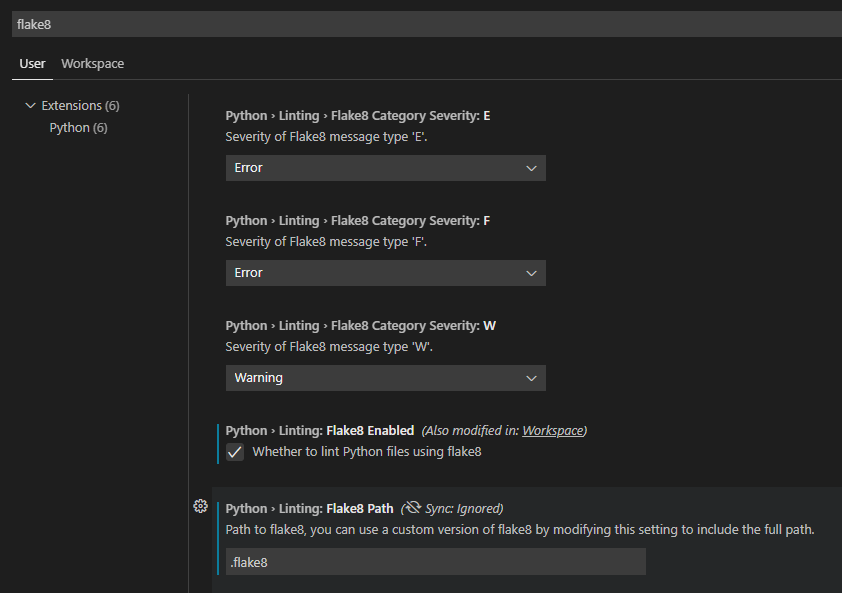
在本機搭配 Visual Studio Code 使用 Flake8:
- 使用
pip install flake8安裝 Flake8。 - 建立設定檔
.flake8,並將檔案儲存在您的存放庫中。 - 移至您的設定 (
Ctrl+,),將 Visual Studio Code 設定為使用 Flake8 做為 Linter。 - 搜尋
flake8。 - 啟用 Python > Linting>,且已啟用 Flake8。
- 將 Flake8 路徑設定為您儲存
.flake8檔案所在存放庫中的位置。
如要指定小組的程式碼品質標準,您可以設定 Flake8 Linter。 定義標準的常見方法,在於建立與程式碼一同儲存的 .flake8 檔案。
檔案 .flake8 應以 [flake8] 開頭,後面接著您想要使用的任何設定。
提示
您可以在 Flake8 文件中,找到潛在設定參數的完整清單。
例如,若您想要指定任何行的長度上限不可超過 80 個字元,則會在 .flake8 檔案中新增下列這一行:
[flake8]
max-line-length = 80
Flake8 具有可傳回的預先定義錯誤清單。 此外,您亦可使用以 PEP 8 樣式指南為基礎的錯誤碼。 例如,您可以包含參考縮排或空格正確使用方式的錯誤碼。
您可以選擇選取 (select) 一組將成為 Linter 的錯誤碼,或從預設選項清單中選取要忽略 (ignore) 的錯誤碼。
因此,您的 .flake8 設定檔看起來可能如下列範例所示:
[flake8]
ignore =
W504,
C901,
E41
max-line-length = 79
exclude =
.git,
.cache,
per-file-ignores =
code/__init__.py:D104
max-complexity = 10
import-order-style = pep8
提示
如需您可以參考的錯誤碼概觀,請檢閱 Flake8 錯誤清單
若您已設定 Visual Studio Code 對程式碼執行 Lint,則可開啟任何程式碼檔案來檢閱 Lint 結果。 任何警告或錯誤都會加上底線。 您可選取 [檢視問題] 來檢查問題,以瞭解錯誤。

具有 Azure Pipelines 或 GitHub Actions 的 Lint
您也可以使用 Azure Pipelines 或 GitHub Actions 來自動執行 Linter。 其中一個平臺提供的代理程式,會在下列情況下執行 Linter:
- 建立設定檔
.flake8,並將檔案儲存在您的存放庫中。 - 在 YAML 中定義持續整合管線或工作流程。
- 做為工作或步驟,請使用
python -m pip install flake8安裝 Flake8。 - 做為工作或步驟,執行
flake8命令以對您的程式碼執行 Lint。
單元測試
Lint 分析會驗證您撰寫程式碼的方式,單元測試會檢查程式碼的運作方式。 單元是指您所建立的程式碼。 因此,單元測試也稱為程式碼測試。
根據最佳做法,程式碼應大部分皆位於函式外部。 無論您已建立函式來準備資料,或是要定型模型。 您可套用單元測試來執行以下工作,例如:
- 檢查資料行名稱是否正確:
- 檢查新資料集上的模型預測層級。
- 檢查預測層級的分佈。
當您使用 Python 時,可以使用 Pytest 和 Numpy (採用 Pytest 架構) 來測試程式碼。 如要深入瞭解 Pytest 的使用方式,請請瞭解如何使用 Pytest 撰寫測試。
提示
檢閱關於在 Visual Studio Code 中執行 Python 測試的詳細逐步解說。
設想一下您已建立包含下列函式的定型指令碼 train.py:
# Train the model, return the model
def train_model(data, ridge_args):
reg_model = Ridge(**ridge_args)
reg_model.fit(data["train"]["X"], data["train"]["y"])
return reg_model
假設您已將定型指令碼儲存在存放庫內的目錄 src/model/train.py 中。 如要測試 train_model 函式,您必須從 src.model.train 匯入函式。
您會在 tests 資料夾中建立 test_train.py 檔案。 測試 Python 程式碼的其中一種方式是使用 numpy。 Numpy 提供數種 assert 函式來比較陣列、字串、物件或項目。
提示
深入瞭解使用 Numpy 測試時的測試指導方針,以及 Numpy 的測試支援。
例如,若要測試 train_model 函式,您可以使用小型定型資料集,並使用 assert 來驗證預測是否幾乎等於您預先定義的效能計量。
import numpy as np
from src.model.train import train_model
def test_train_model():
X_train = np.array([1, 2, 3, 4, 5, 6]).reshape(-1, 1)
y_train = np.array([10, 9, 8, 8, 6, 5])
data = {"train": {"X": X_train, "y": y_train}}
reg_model = train_model(data, {"alpha": 1.2})
preds = reg_model.predict([[1], [2]])
np.testing.assert_almost_equal(preds, [9.93939393939394, 9.03030303030303])
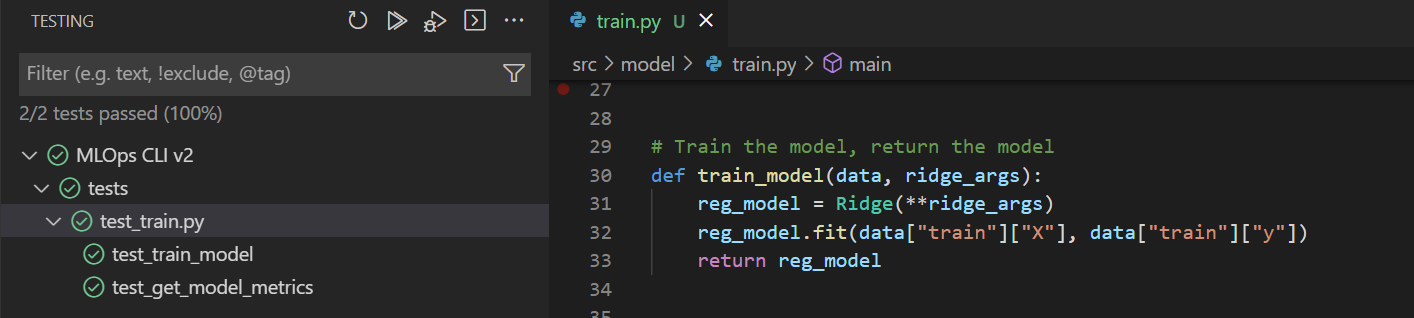
使用 UI 在 Visual Studio Code 中測試程式碼:
- 安裝所有必要的程式庫以執行定型指令碼。
- 確認
pytest已在 Visual Studio Code 內安裝並啟用。 - 安裝適用於 Visual Studio Code 的 Python 延伸模組。
- 選取您要測試的
train.py指令碼。 - 從左側功能表中,選取 [測試] 索引標籤。
- 選取 [pytest] 並將測試目錄設定為
tests/資料夾,以設定 Python 測試。 - 選取播放按鈕並檢閱結果,以執行所有測試。
在 Azure DevOps 管線或 GitHub Action 中執行測試:
- 確認已安裝所有必要的程式庫來執行定型指令碼。 在理想情況下,使用
requirements.txt列出具有pip install -r requirements.txt的全部程式庫 - 使用
pip install pytest安裝pytest - 使用
pytest tests/執行測試
測試結果會顯示在您執行的管線或工作流程輸出中。
注意
若在 Linting 或單元測試期間傳回錯誤,CI 管線可能會失敗。 因此,建議您先在本機驗證程式碼,然後再觸發 CI 管線。