存放庫和主幹型開發
許多資料科學家偏好使用 Python 或 R 來定義機器學習工作負載。 您可使用 Jupyter Notebook 或指令碼來準備資料或定型模型。
當您使用原始程式碼控制時,可更加輕易地處理任何程式碼資產。 原始程式碼控制是管理程式碼和追蹤小組對程式碼所做任何變更時,所採取的實務做法。
若您使用諸如 Azure DevOps 或 GitHub 等 DevOps 工具,則會將程式碼儲存在所謂的存放庫 (Repo) 中。
存放庫
設定 MLOps 架構時,機器學習工程師可能會建立存放庫。 無論您選擇在 Azure DevOps 或 GitHub 存放庫中使用 Azure Repos,皆會使用 Git 存放庫來儲存程式碼。
界定存放庫範圍的方式通常有兩種:
- 單個存放庫:將所有機器學習工作負載保留在相同的存放庫中。
- 多個存放庫:為每個新的機器學習專案建立個別存放庫。
小組偏好的方法,會取決於誰應取得哪些資產的存取權。 若您想要確保快速存取所有程式碼資產,單個存放庫可能會更符合小組的需求。 若您只想在人員主動處理專案時授與專案存取權,小組可能會偏好使用多個存放庫。 請謹記,管理存取控制可能會產生更多額外負荷。
建構您的存放庫
無論您採取何種方法,最佳做法是同意您專案的標準最上層資料夾結構。 例如,您可能在所有存放庫中皆具有下列資料夾:
.cloud:包含諸如範本等雲端特定程式碼,可建立 Azure Machine Learning 工作區。.ad/.github:包含 Azure DevOps 或 GitHub 成品 (例如 YAML 管線),可將工作流程自動化。src:包含任何程式碼 (Python 或 R 程式碼) 用於諸如前置處理資料或模型定型的機器學習工作負載。docs:包含用來描述專案的任何 Markdown 檔案或其他文件。pipelines:包含 Azure Machine Learning 管線定義。tests:包含單元與整合測試,用於偵測程式碼中的錯誤和問題。notebooks:包含 Jupyter Notebook,主要用於實驗。
注意
定型資料不應包含在您的存放庫中。 資料應儲存在資料庫或資料湖中。 Azure Machine Learning 可將連線資訊儲存為資料存放區,以直接存取資料庫或資料湖。
藉由具備每個專案採用的標準結構,可協助資料科學家和其他共同作業者更輕易地找到需要處理的程式碼。
提示
尋找更多關於建構資料科學家專案的最佳做法的詳細資訊.
為了瞭解如何以資料科學家身分使用存放庫,您將瞭解關於主幹型開發的資訊。
主幹型開發
大部分的軟體開發專案皆會使用 Git 做為原始程式碼控制系統,Azure DevOps 和 GitHub 皆採用此系統。
使用 Git 的主要優點,在於可輕鬆針對程式碼展開共同作業,同時追蹤所做的任何變更。 此外,您可新增核准閘道,以確保僅針對生產程式碼採取已檢閱且已接受的變更。
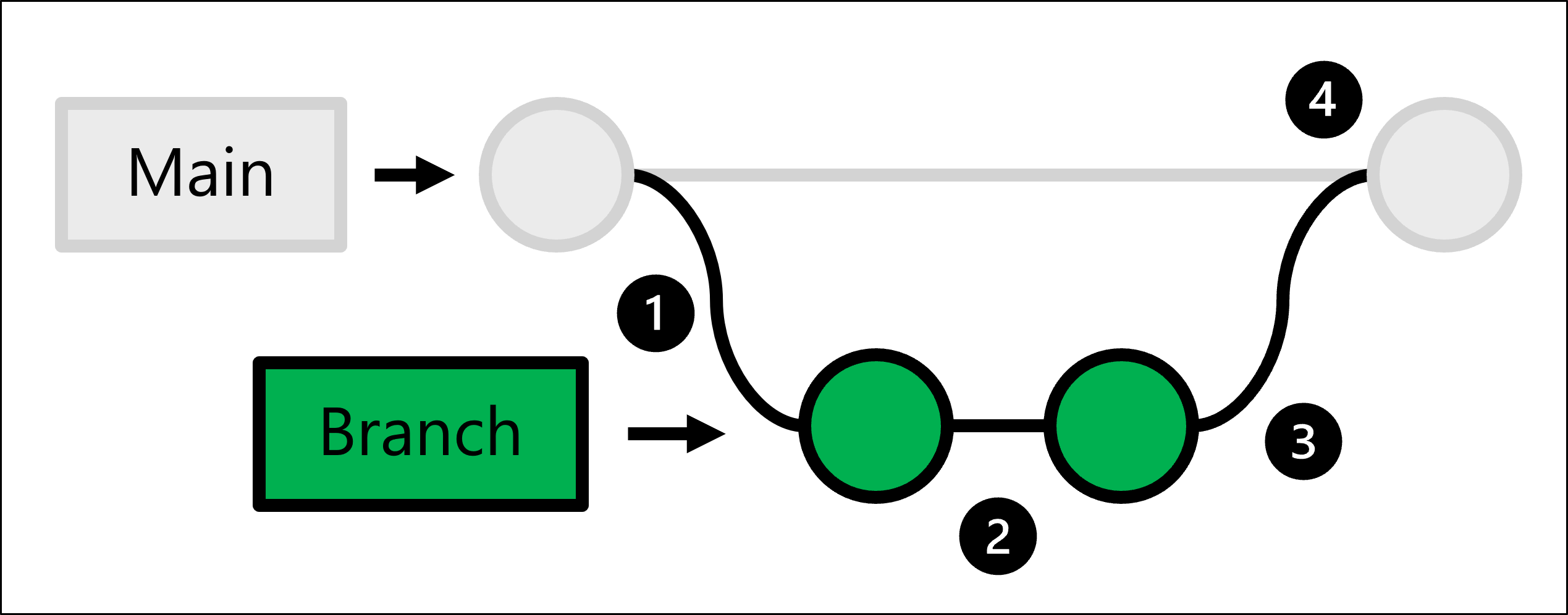
為了完成上述作業,Git 使用主幹型開發以讓您建立分支。
生產程式碼裝載於主要分支中。 每當有人想要進行變更時:
- 您可建立分支,以建立生產程式碼的完整複本。
- 在您建立的分支中,您會進行任何變更並加以測試。
- 一旦分支中的變更準備就緒,您即可要求某人檢閱變更。
- 若已核准變更,您可合併所建立的分支與主要存放庫,並更新生產程式碼以反映您的變更。