練習 - 清理和準備資料
您必須先了解資料集的內容和結構,才能準備資料集。 在上一個實驗室中,您匯入了包含美國主要航空公司之準時到達資訊的資料集。 該資料包含 26 個資料行和數千個資料列,每個資料列代表一個航班,包含航班出發地、目的地,以及表定起飛時間等資訊。 您也將資料載入 Jupyter 筆記本中,並使用簡單的 Python 指令碼從中建立 Pandas DataFrame。
DataFrame 是二維標記資料結構。 DataFrame 中的資料行可以是不同類型,就像試算表或資料庫資料表中的資料行一樣。 其為 Pandas 中最常使用的物件。 在此練習中,您會更仔細檢查 DataFrame 及其內部的資料。
切換回您在上一節中建立的 Azure 筆記本。 如果您已關閉筆記本,您可以重新登入 Microsoft Azure Notebooks 入口網站,開啟筆記本並使用 [資料格] ->[全部執行],並於開啟筆記本後在其中重新執行所有資料格。
FlightData 筆記本
您在上一個實驗中新增至筆記本的程式碼,會從 flightdata.csv 建立 DataFrame,並在其上呼叫 DataFrame.head 以顯示前五個資料列。 關於資料集,您通常想要了解的第一件事,是其所包含的資料列數目。 若要取得計數,請在筆記本結尾的空白資料格中輸入下列陳述式並執行:
df.shape確認 DataFrame 包含 11,231 個資料列和 26 個資料行:

取得資料列和資料行計數
現在請花點時間檢查資料集內的 26 個資料行。 它們包含重要資訊,例如航班的日期 (YEAR、MONTH 和 DAY_OF_MONTH)、起點和終點 (ORIGIN 和 DEST)、表定起飛和到達時間 (CRS_DEP_TIME 和 CRS_ARR_TIME)、表定到達時間和實際到達時間之間的分鐘差異 (ARR_DELAY),以及航班是否誤點 15 分鐘以上 (ARR_DEL15)。
下列是資料集中資料行的完整清單。 時間以 24 小時制軍事時間表示。 例如,1130 等於上午 11:30,而 1500 等於下午 3:00。
資料行 描述 YEAR 航班的年份 QUARTER 航班的季度 (1-4) MONTH 航班的月份 (1-12) DAY_OF_MONTH 航班月份中的日期 (1-31) DAY_OF_WEEK 航班是星期幾 (1=星期一、2=星期二,依此類推) UNIQUE_CARRIER 航空公司代碼 (例如 DL) TAIL_NUM 飛機尾端號碼 FL_NUM 航班編號 ORIGIN_AIRPORT_ID 出發地機場的識別碼 ORIGIN 出發地機場代碼 (ATL、DFW、SEA 等等) DEST_AIRPORT_ID 目的地機場的識別碼 DEST 目的地機場代碼 (ATL、DFW、SEA 等等) CRS_DEP_TIME 表定起飛時間 DEP_TIME 實際起飛時間 DEP_DELAY 誤點分鐘數 DEP_DEL15 0=航班誤點低於 15 分鐘、1=航班誤點 15 分鐘以上 CRS_ARR_TIME 表定到達時間 ARR_TIME 實際到達時間 ARR_DELAY 航班誤點分鐘數 ARR_DEL15 0=誤點不超過 15 分鐘,1=誤點 15 分鐘以上 CANCELLED 0=航班未取消,1=航班已取消 DIVERTED 0=航班未轉向,1=航班已轉向 CRS_ELAPSED_TIME 表定飛行時間 (分鐘) ACTUAL_ELAPSED_TIME 實際飛行時間 (分鐘) DISTANCE 航行距離 (英哩)
該資料集的全年日期分佈大致平均,這很重要,因為明尼阿波里斯市航班在 7 月時不太可能像在 1 月時的冬季風暴而誤點。 但是,此資料集還遠遠稱不上是「乾淨」且已隨時可用。 讓我們撰寫一些 Pandas 程式碼來加以清理。
準備用於機器學習之資料集的最重要層面之一是,選取與您嘗試預測結果相關的「功能」資料行,同時篩選掉不會影響結果的資料行,可能會以負面方式對其造成偏差,或可能產生 Multicollinearity (多重共線性)。 另一個重要工作是去除遺漏的值,方式為刪除包含這些值的資料列或資料行,或以有意義的值來加以取代。 在此練習中,您將刪除多餘的資料行,並取代其餘資料行中的遺漏值。
資料科學家通常會在資料集中尋找的第一個項目,就是遺漏的值。 沒有簡單的方法可檢查 Pandas 中的遺漏值。 為了示範,請在筆記本結尾的資料格中執行下列程式碼:
df.isnull().values.any()確認輸出為 "True",指出資料集中至少有一個遺漏值。

檢查遺漏值
下一步是找出遺漏值的位置。 若要執行此動作,請執行下列程式碼:
df.isnull().sum()確認您有看到下列輸出,列出每一個資料行中遺漏值的計數:
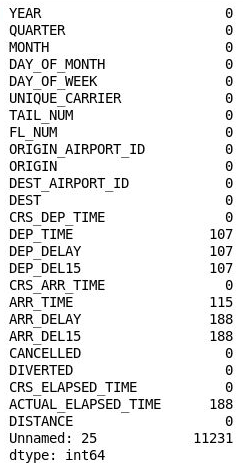
每一個資料行中的遺漏值數
奇怪的是,第 26 個資料行 ("未命名: 25") 包含 11,231 個遺漏值,這等於資料集中的資料列數。 此資料行是不小心建立的,因為您匯入的 CSV 檔案在每一行結尾都包含了一個逗號。 若要消除該資料行,請將下列程式碼新增到筆記本中並加以執行:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()檢查輸出並確認第 26 資料行已從 DataFrame 中消失:
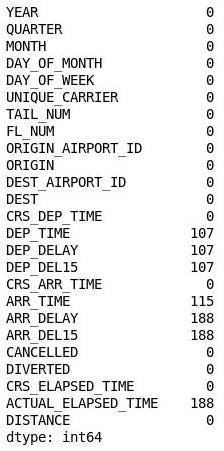
移除第 26 資料行的 DataFrame
DataFrame 仍包含許多遺失值,但其中某些遺失值並不實用,因為包含它們之資料行與您正在建置的模型無關。 該模型的目標是預測您正在考慮預訂的航班可能會準時抵達。 若您知道該航班可能會延誤,您便可能會選擇其他航班。
因此,下一步便是篩選資料集來消除與預測模型無關的資料行。 例如,飛機的尾端號碼與航班是否會準時抵達可能沒什麼關係,且當您預訂機票時,您也無法得知航班是否會遭到取消、改道或延誤。 相較之下,表定起飛時間可能會與準時抵達「高度相關」。 由於大多數航空公司使用的中樞和支點系統,上午的航班通常會比下午或晚上航班更常準時。 而在某些主要機場中,交通可能會在白天大量堆疊,增加後續航班延誤的可能性。
Pandas 提供一種簡單的方式,可讓您篩選掉您不需要的資料行。 請在筆記本結尾的新資料格中執行下列程式碼:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()輸出會顯示 DataFrame 現在只包含與模型相關的資料行,且遺漏值的數量也已大幅減少:
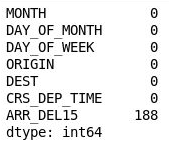
篩選後的 DataFrame
現在包含遺失值的唯一資料行即是 ARR_DEL15 資料行,該資料行使用 0s 來識別準時抵達的航班,並使用 1s 來識別未準時抵達的航班。 請使用下列程式碼來顯示具有遺漏值的前五個資料列:
df[df.isnull().values.any(axis=1)].head()Pandas 會使用
NaN來代表遺漏值,其代表「非數字」。 輸出會顯示這些資料列的確在 ARR_DEL15 資料行中遺漏了值: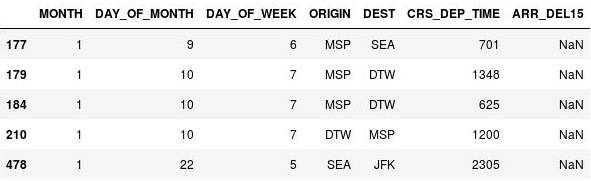
具有遺漏值的資料列
這些資料列遺漏 ARR_DEL15 值的原因是它們全部都對應到遭到取消或改道的航班。 您可以在 DataFrame 上呼叫 dropna 來移除這些資料列。 但由於遭到取消或改道至另一個機場的航班可被視為「延誤」,因此讓我們使用 fillna 方法來將遺漏值取代為 1s。
使用下列程式碼將 ARR_DEL15 資料行中的遺失值取代為 1s,並顯示第 177 至第 184 資料列:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]確認位於第 177、179 與 184 資料列的
NaN都已取代為 1s,指出航班已延誤抵達: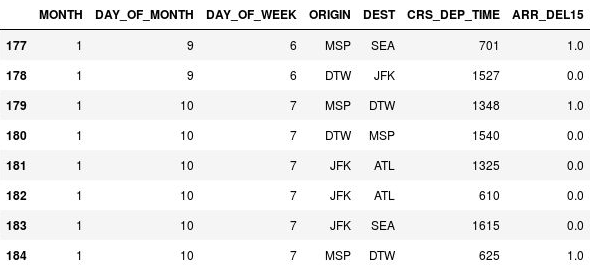
替換成 1s 的 NaN
由於遺漏值皆已取代,且資料行的清單也已縮減至與模型最相關項目,因此資料集現在在這方面已可視為「乾淨」。 但是您還未完成。 準備資料集以用於機器學習服務,仍需要許多作業來進行準備。
您正在使用資料集中的 CRS_DEP_TIME 資料行代表排程後的起飛時間。 此資料行中數字的細微性 (包含超過 500 個唯一值) 可能會對機器學習服務模型中的正確性產生不良影響。 您可以使用稱為量化的技術來解決此問題。 若您將此資料行中每個數字都除以 100 並捨去到最接近的整數會怎麼樣? 1030 會變成 10,1925 會變成 19 等,且您將會需要面對此資料行中最多 24 個離散值。 直覺來說,這很合理,因為航班究竟是上午 10:30 或上午 10:40 起飛並沒有太大差別。但如果是上午 10:30 或下午 5:30 起飛,就有差別了。
此外,資料集的 ORIGIN 和 DEST 資料行包含機場代碼,代表類別機器學習值。 這些資料行也需要轉換成包含指示變數 (有時稱為「虛擬」變數) 的離散資料行。 換句話說,包含五個機場代碼的 ORIGIN 資料行需要轉換成五個資料行 (每個機場各一個),其中每個資料行都包含 1s 和 0s,指出航班是否來自該資料行代表的機場。 DEST 資料行需要以類似的方式處理。
在此練習中,您會「拋棄」 CRS_DEP_TIME 資料行中的起飛時間,然後使用 Pandas 的 get_dummies 方法來從 ORIGIN 和 DEST 資料行建立指示資料行。
使用下列命令來顯示 DataFrame 的前五個資料列:
df.head()觀察 CRS_DEP_TIME 資料行包含 0 到 2359 的值,表示軍事時間。
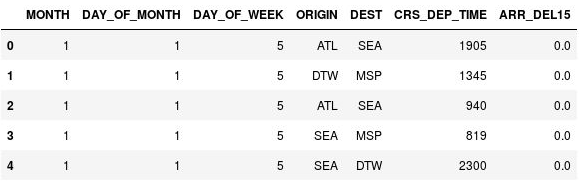
包含尚未拋棄起飛時間的 DataFrame
使用下列陳述式來拋棄起飛時間:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()確認 CRS_DEP_TIME 資料行中數字現在介於 0 到 23 的範圍內:
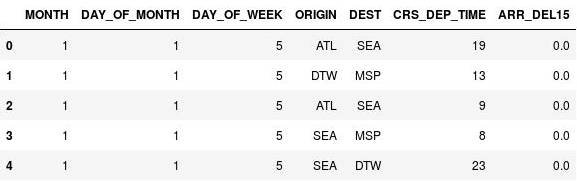
包含拋棄後起飛時間的 DataFrame
現在使用下列陳述式來從 ORIGIN 和 DEST 資料行產生指示資料行,同時卸除 ORIGIN 及 DEST 資料行本身:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()檢查產生的 DataFrame 並觀察 ORIGIN 和 DEST 資料行已使用對應到原始資料行中機場代碼的資料行來取代。 新的資料行現在會包含 1s 和 0s,指出指定的航班是否來自或目標是否為對應的機場。
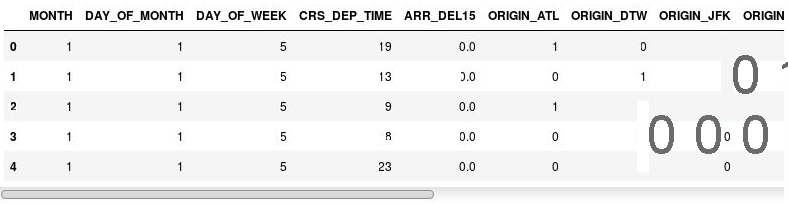
包含指示資料行的 DataFrame
使用 File ->Save and Checkpoint 命令來儲存筆記本。
資料集看起來與剛開始的時候相當不同,但現在已針對機器學習服務進行最佳化。