設定提早終止
超參數微調可協助您微調模型,並選取可讓模型發揮最佳效能的超參數值。
不過,若要找到最佳模型,可以是永無止境的征服。 您一律必須考慮是否值得測試新的超參數值的時間和費用,以尋找可能效能較佳的模型。
掃掠作業中的每個試用版,都會使用超參數值的新組合來定型新的模型。 如果定型新模型不會產生明顯更好的模型,您可能會想要停止掃掠作業,並使用到目前為止效能最佳的模型。
當您在 Azure Machine Learning 中設定掃掠作業時,也可以設定最大試用版數目。 當較新的模型不會產生明顯更好的結果時,較複雜的方法可能是停止掃掠作業。 若要根據模型的效能停止掃掠作業,您可以使用提早終止原則。
使用早期終止原則的時機
是否要使用早期終止原則,可能取決於您正在使用的搜尋空間和取樣方法。
例如,您可以選擇將格線取樣方法用於導致最多六個試用版的離散搜尋空間。 在六項試驗中,最多將訓練六個模型,而且可能不需要提前終止原則。
在搜尋空間中使用連續超參數時,早期終止原則特別有用。 連續超參數提供不限數目的可能值可供選擇。 使用連續超參數和隨機或貝氏取樣方法時,您很可能會使用早期終止原則。
設定提早終止原則
當您選擇使用早期終止原則時,有兩個主要參數:
evaluation_interval:指定您想要評估原則的間隔。 每次記錄試用的主要計量時,都會計算為間隔。delay_evaluation:指定何時開始評估原則。 此參數至少允許至少完成試用版,而不需要影響其早期終止原則。
新的模型可能只會比先前的模型稍微好一些。 若要判斷模型應該執行得比先前試用更好的程度,有三個選項可供提早終止:
- Bandit 原則:使用
slack_factor(相對)或slack_amount(絕對)。 任何新模型都必須在最佳執行模型的寬限範圍內執行。 - 中位數停止原則:使用主要計量平均值的中位數。 任何新模型的執行效能都必須優於中位數。
- 截斷選取原則:使用
truncation_percentage,這是執行中最低試用版的百分比。 任何新模型的執行效能必須優於最低效能的試用版。
Bandit 原則
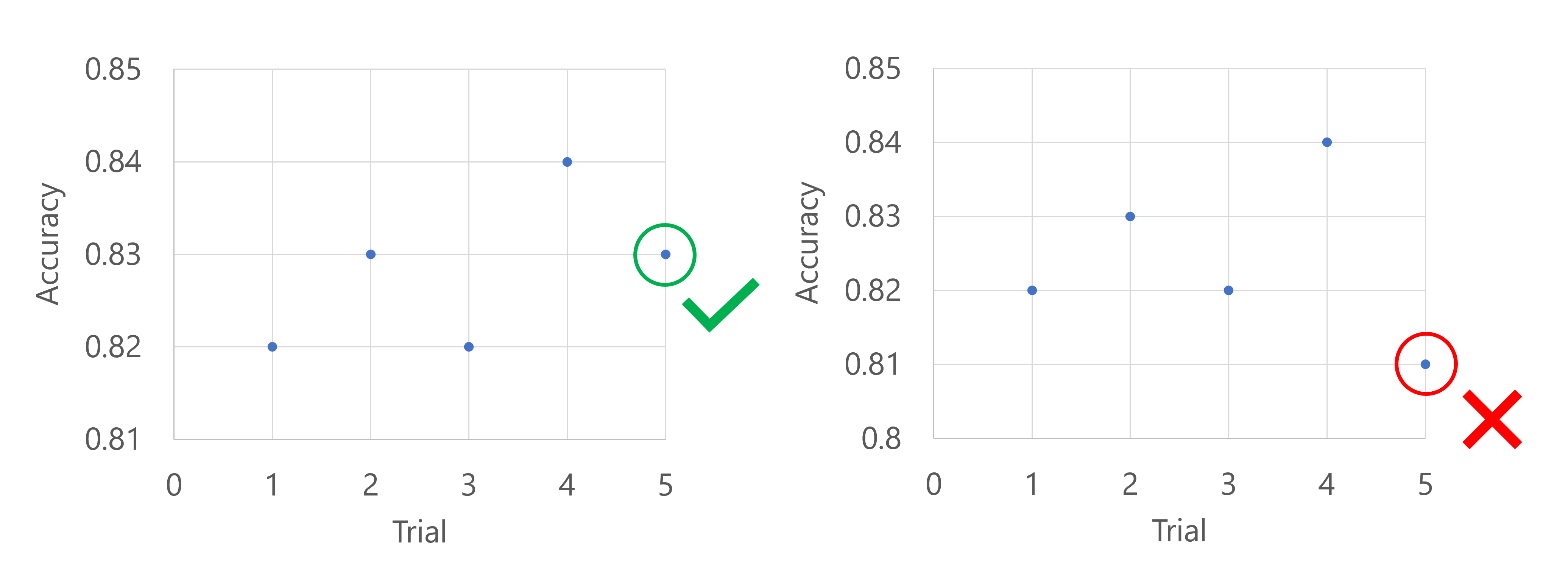
您可以使用 bandit 原則,在目標效能計量目前的執行表現較最佳執行不佳達指定差額時停止該執行。
例如,下列程式碼會套用延遲為 5 個試用版的 bandit 原則、在每個間隔評估原則,並允許絕對寬限時間量為 0.2。
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(
slack_amount = 0.2,
delay_evaluation = 5,
evaluation_interval = 1
)
假設主要計量是模型的精確度。 在前五次試驗之後,最佳執行模型的正確性為 0.9,任何新模型的執行效能都必須優於 (0.9-0.2) 或 0.7。 如果新模型的精確度高於 0.7,則掃掠作業將會繼續。 如果新模型的正確性分數低於 0.7,原則將會終止掃掠作業。
您也可以使用 slack 因數來套用 bandit 原則,其會將效能計量與比率 (而非絕對值) 進行比較。
中位數停止原則
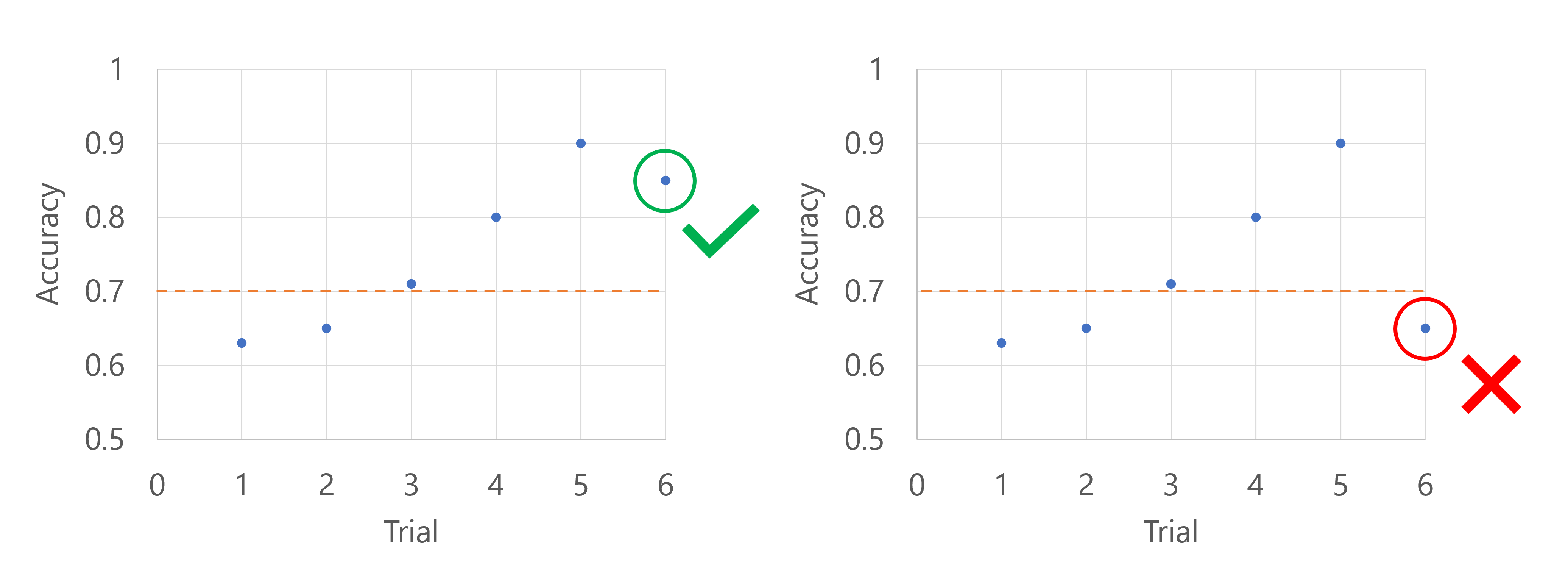
中位數停止原則會放棄試用,其中的目標效能計量比所有試用的平均試用平均值的中位數還差。
例如,下列程式碼會套用延遲為五個試用版的中位數停止原則,並在每個間隔評估原則。
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation = 5,
evaluation_interval = 1
)
假設主要計量是模型的精確度。 當第六次試用記錄精確度時,計量必須高於到目前為止精確度分數的中位數。 假設到目前為止精確度分數的中位數為 0.82。 如果新模型的精確度高於 0.82,掃掠作業將會繼續。 如果新模型的正確性分數低於 0.82,原則將會停止掃掠作業,而且不會訓練任何新模型。
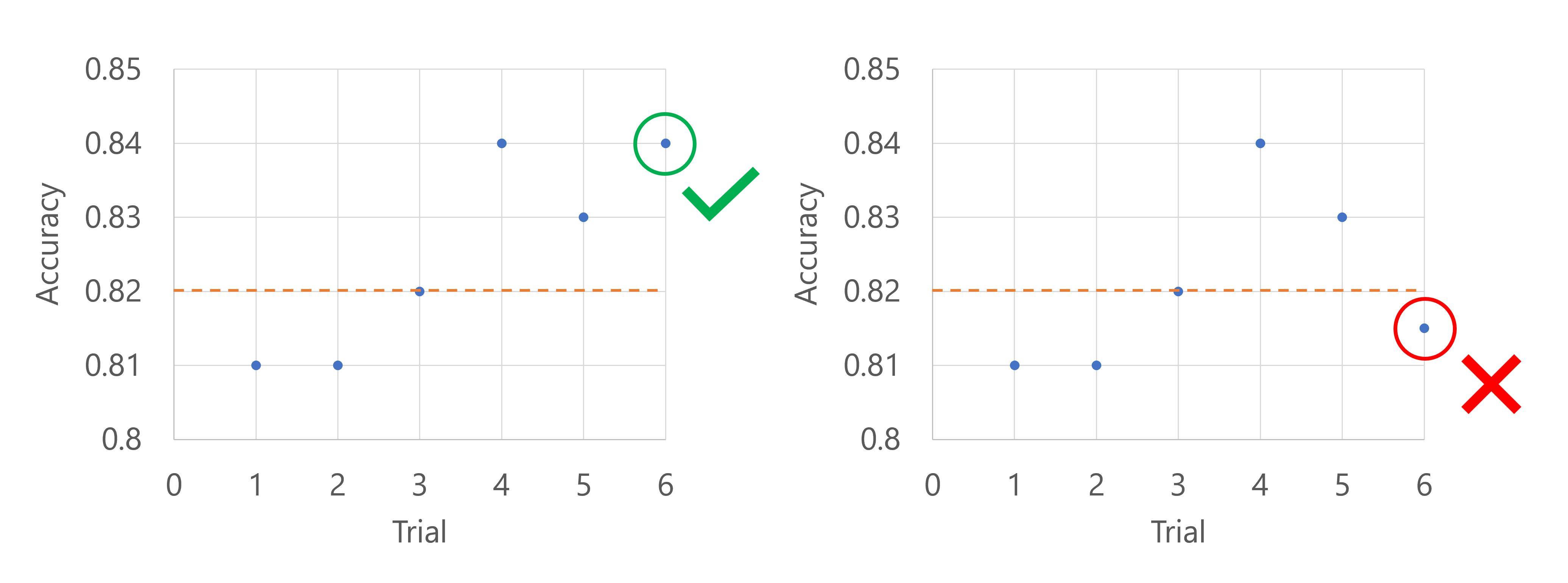
截斷選取原則
截斷選取原則會根據您為 X 指定的 truncation_percentage 值,取消每個評估間隔的試用最低的 X%。
例如,下列程式碼會套用延遲為四個試用版的截斷選取原則、在每個間隔評估原則,並使用截斷百分比為 20%。
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(
evaluation_interval=1,
truncation_percentage=20,
delay_evaluation=4
)
假設主要計量是模型的精確度。 當第五次試用的精確度記錄時,該計量目前不應處於最差的 20% 試驗中。 在此情況下,20% 會轉譯為一個試用版。 換句話說,如果第五次試驗不是迄今為止表現最差的模式,整理工作將繼續。 如果第五次試驗目前所有試驗的精確度分數最低,掃蕩工作將停止。