練習 - 佈建 HDInsight 以執行進階串流資料轉換
若要建立 Azure 虛擬網路,然後在其中建立 Kafka 和 Spark 叢集,請使用以下步驟:
開啟此連結來登入 Azure 入口網站,然後在新視窗中開啟 [自訂部署] 頁面。
此範本會建立下列資源︰
- 適用於 HDInsight 4.0 的 Kafka 2.1.1 叢集。
- 適用於 HDInsight 4.0 的 Spark 2.4.4 叢集。
- Azure 虛擬網路,其中包含 HDInsight 叢集。
使用以下資訊填入 [自訂範本] 區段中的項木:
設定 值 訂用帳戶 選取要在其中建立叢集的訂用帳戶。 資源群組 按一下 [新建] 以建立新的資源群組,並為資源群組提供唯一的名稱。 Location 要在其中建立資源的 Azure 區域。 Spark 叢集名稱 輸入 Spark 叢集的名稱,例如 spark-mslearn-stock。 前六個字元必須與 Kafka 叢集名稱不同。 Kafka 叢集名稱 輸入 Kafka 叢集的名稱,例如 kafka-mslearn-stock。 前六個字元必須與 Spark 叢集名稱不同。 叢集登入使用者名稱 保留系統管理員的預設值。 叢集登入密碼 輸入密碼進行叢集登入。 SSH 使用者名稱 保留預設值 [sshuser]。 SSH 密碼 輸入 SSH 使用者的密碼。 閱讀 [條款與條件],然後選取 [我同意以上所述的條款及條件]。
選取 [購買] 。
按一下 [通知] 圖示以監看部署的進度。
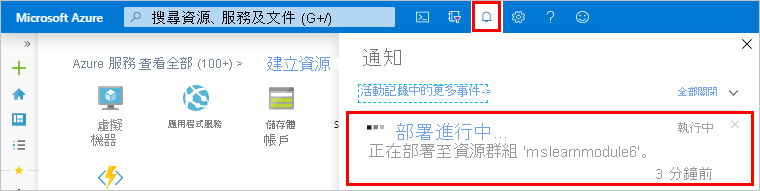
當部署成功時,訊息會變更為 [部署成功]。
在 [通知] 窗格中,按一下 [前往資源]。
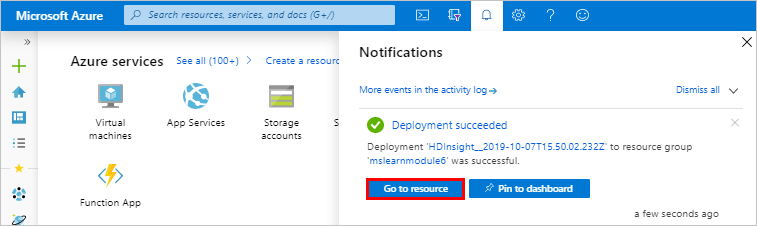
如果您收到有關部署的錯誤,請按一下 [通知] 圖示,確定 Kafka 和 Spark 叢集名稱不會共用相同的六個字元。 如果它們使用相同的六個字元,請重試 Azure 資源範本並更正叢集名稱。