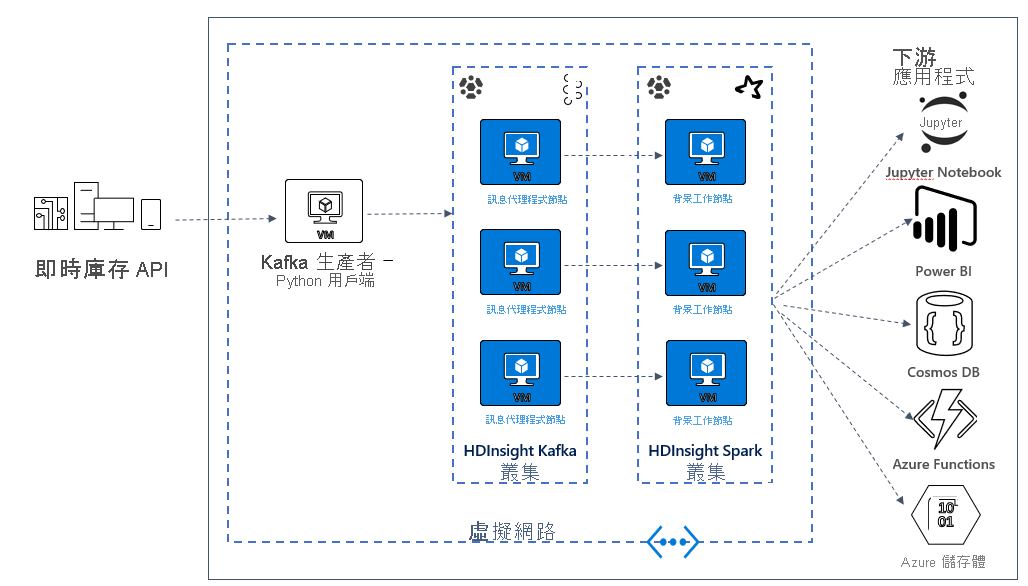
建立 Kafka 和 Spark 架構
若要在 Azure HDInsight 中一起使用 Kafka 和 Spark,您必須將它們放在同一 VNet 內或對等連接 Vnet,如此叢集才能搭配 DNS 名稱解析來操作。
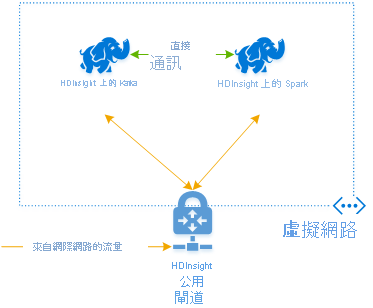
若要在同一 VNet 中建立叢集,程序如下:
- 建立資源群組
- 將 VNet 新增至資源群組
- 將 Kafka 叢集和 Spark 叢集新增至同一 VNet,或者對等連接 VNet,其中這些服務搭配 DNS 名稱解析來操作。
連接 HDInsight Kafka 和 Spark 叢集的建議方式是原生 Spark-Kafka 連接器,其可讓 Spark 叢集存取 Kafka 叢集內的個別資料分割區,這會增加您在即時處理作業中所擁有的平行處理原則,並提供極高的輸送量。
當這兩個叢集都位於同一 VNet 時,您也可以在 Spark 串流程式碼中使用 Kafka 訊息代理程式 FQDN,並可在 VNet 上建立 NSG 規則,以取得企業安全性。
解決方案架構
Azure 上的即時串流分析模式通常會使用下列解決方案架構。
- 內嵌:非結構化或結構化資料會內嵌至 Azure HDInsight 上的 Kafka 叢集。
- 準備和定型:在 HDInsight 上使用 Spark 準備和定型資料。
- 製作模型和提供服務:資料會放入資料倉儲中,例如 Azure Synapse 或 HDInsight Interactive Query。
- 智慧:資料會提供給分析儀表板,例如 Power BI 或 Tableau。
- 存放區:資料會放入冷儲存體解決方案 (例如 Azure 儲存體) 中,並於稍後提供。
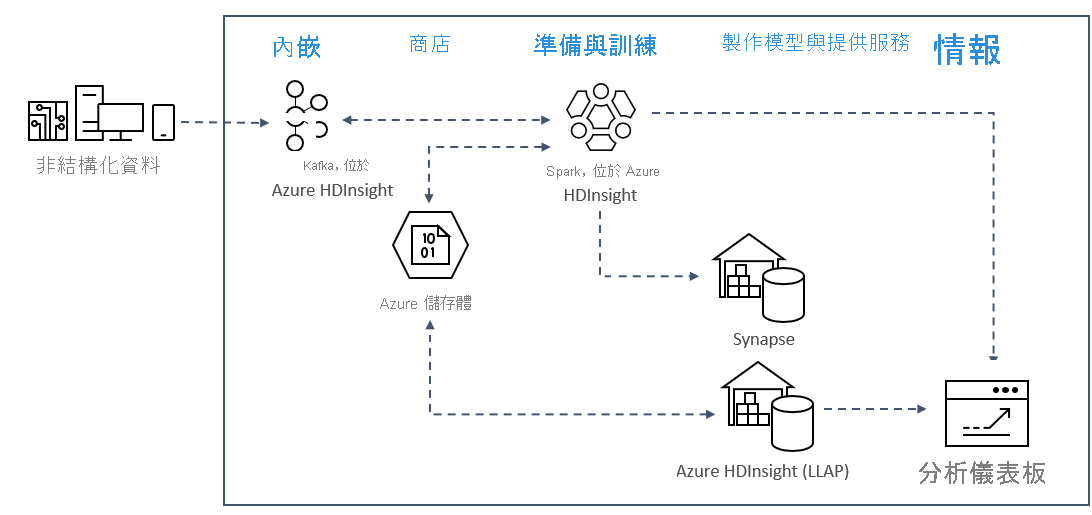
範例情節架構
在下一個單元中,您將開始為範例應用程式建立解決方案架構。 此範例會使用 Azure Resource Manager 範本檔案來建立資源群組、VNET、Spark 叢集和 Kafka 叢集。
一旦部署了叢集,就會透過 ssh 連線到其中一個 Kafka 訊息代理程式,並將 Python 生產者檔案複製到前端節點。 該生產者檔案每隔 10 秒會提供人工股票價格,也會將訊息的分割區編號和位移寫入至主控台。
一旦生產者執行中,您就可以將 Jupyter 筆記本上傳至 Spark 叢集。 在筆記本中,您將連接 Spark 和 Kafka 叢集,並對資料執行一些範例查詢,包括尋找事件視窗內股票的高低值。