使用接收者運算子特性曲線來分析分類
分類模型必須將範例指派給類別。 例如,其必須使用大小、色彩和移動等特徵來判斷物體是登山客還是樹木。
我們可以透過許多方式來改善分類模型。 例如,我們可以確保資料是平衡的、乾淨的且已調整其規模。 我們也可以改變我們的模型架構,並使用超參數,從我們的資料和架構中擠出儘可能多的效能。 最終,我們找不到更好的方法來改善測試 (或保留) 集的效能,因此宣告我們的模型已準備就緒。
調整到這一點的模型可能會很複雜,但最後一個簡單的步驟可以用來進一步改善模型的運作效能。 不過,若要瞭解這一點,我們必須回到基本概念。
機率和分類
許多模型都有多個決策制定階段,而最後一個模型通常只是二元化步驟。 在二元化期間,機率會轉換成硬式標籤。 例如,假設模型隨附一些特徵,並算出有 75% 的機會顯示登山客,而有 25% 的機會顯示樹木。 物體不可能是 75% 登山客和 25% 樹木 – 不是登山客就是樹木! 因此,模型會套用閾值,通常是 50%。 當登山客類別大於 50% 時,物體就會宣告為登山客。
50% 閾值符合邏輯,這表示一律會選擇根據模型最可能的標籤。 不過,如果模型有偏差,此 50% 閾值可能不適當。 例如,如果模型稍微傾向於挑選樹木,而不是登山客 (挑選樹木的頻率比其應有的頻率多出 10%),我們可以調整決策閾值來解決此問題。
複習決策矩陣
決策矩陣是評估模型所犯錯誤類型的絕佳方法。 這提供我們確判為真 (TP)、確判為否 (TN)、誤判為否 (FP) 和誤判為真 (FN) 的比率

我們可以從混淆矩陣計算一些實用的特性。 兩個熱門的特性如下:
- 確判為真率 (靈敏度) :正確識別「True」標籤的頻率。例如,當模型顯示的樣本實際上是登山客時,模型預測「登山客」的頻率。
- 誤判為真率 (誤判警示率) :錯誤將「False」標籤識別為「True」的頻率。例如,模型在顯示樹木時預測「登山客」的頻率。
查看確判為真率和誤判為真率可協助我們了解模型的效能。
請想想我們的登山客範例。 在理想情況下,確判為真率很高,而誤判為真率很低,因為這表示模型會很好地識別出登山客,而不會經常將樹木識別為登山客。 但是,如果確判為真率很高,但誤判為真率也很高,則模型會產生偏差:會將其遇到的一切物體幾乎識別為登山客。 同樣地,我們不想要模型具有低的確判為真率,因為當模型遇到登山客時,其會將這些登山客標示為樹木。
接收者運算子特性曲線
接收者運算子特性 (ROC) 曲線是一種圖形,我們會在其中繪製確判為真率與誤判為真率。
ROC 曲線可能讓初學者感到混淆,有兩個主要原因。 第一個原因是,初學者知道對於確判為真率和確判為否率,模型只有一個值,因此,ROC 繪圖必須看起來像這樣:
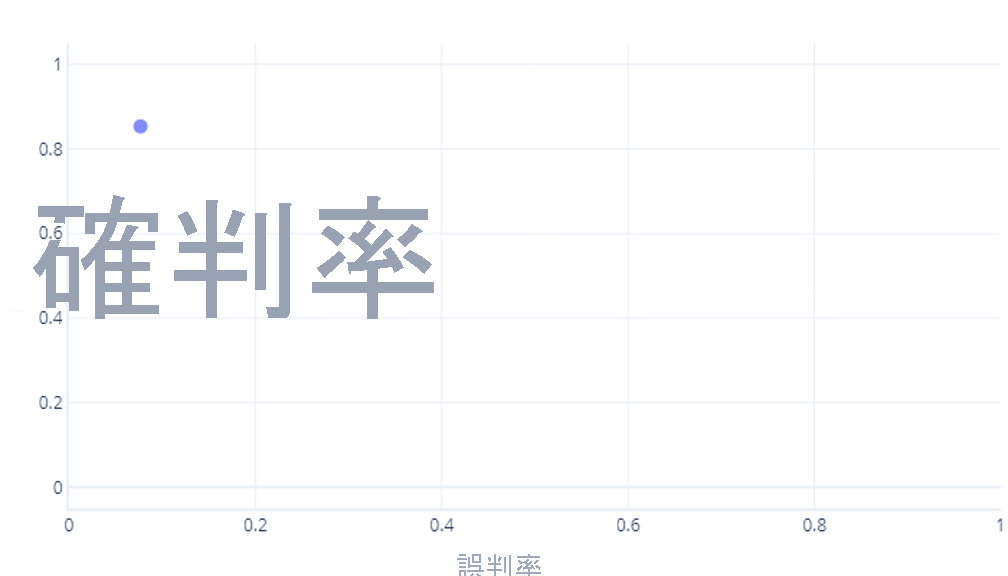
如果您也這樣想,那你就對了。 定型的模型只會產生一個點。 不過,請記住,我們的模型具有閾值 (通常是50%),用來決定應該使用 true (hiker) 還是 false (tree) 標籤。 如果我們將此閾值變更為 30%,並重新計算確判為真率和誤判為真率,我們會得到另一個點:
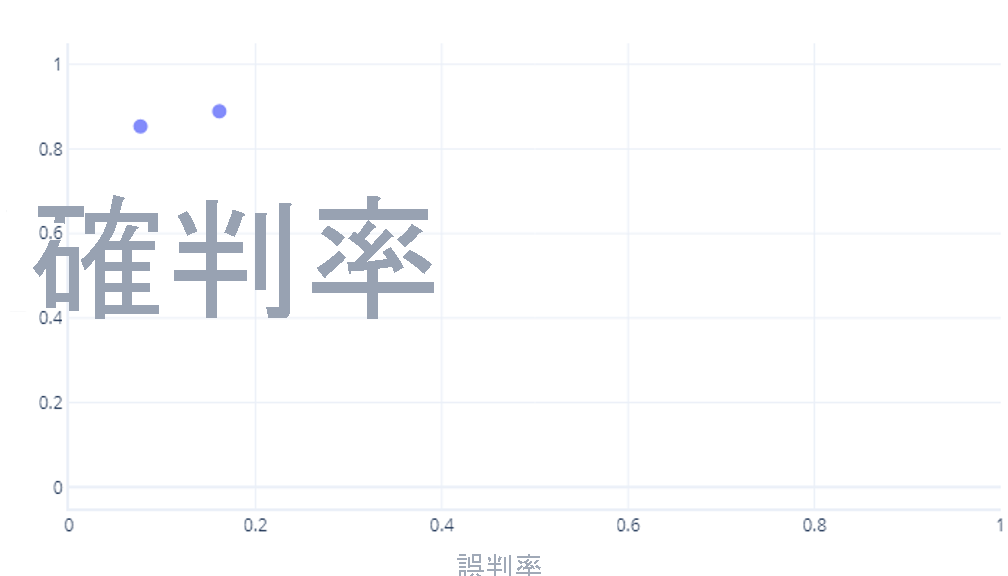
如果我們針對 0% - 100% 之間的閾值執行此動作,我們可能會得到如下的圖形:
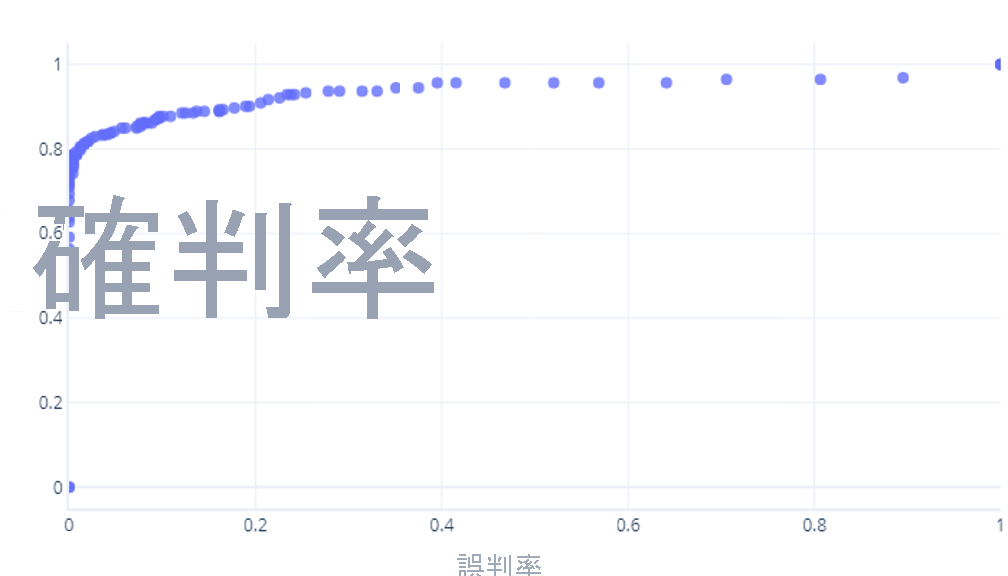
我們通常會將其顯示為一條線,而不是:
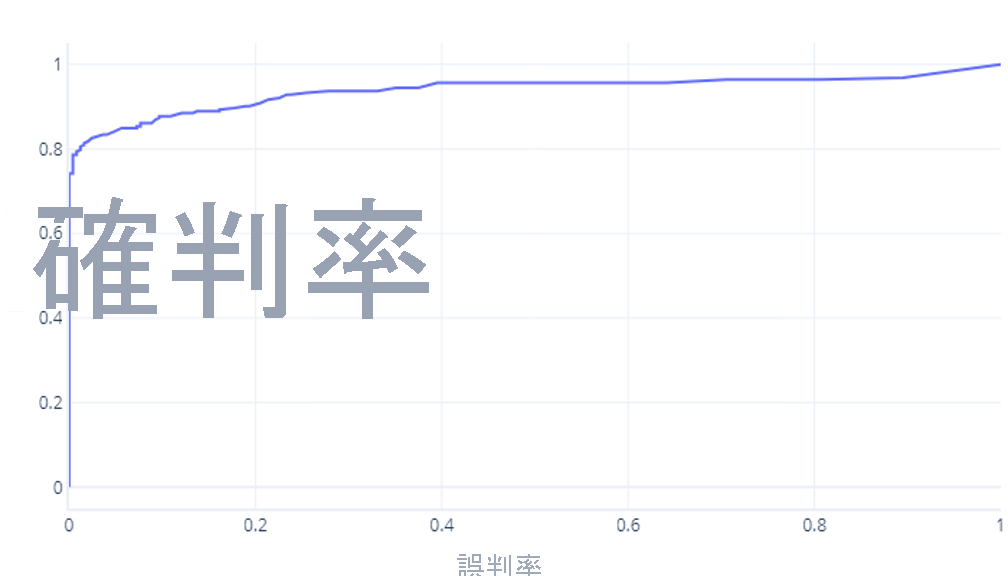
這些圖形可能令人混淆的第二個原因是所涉及的術語。 請記住,我們需要高確判為真率 (將登山客識別為登山客) 和低誤判為真率 (不會將樹木識別為登山客)。
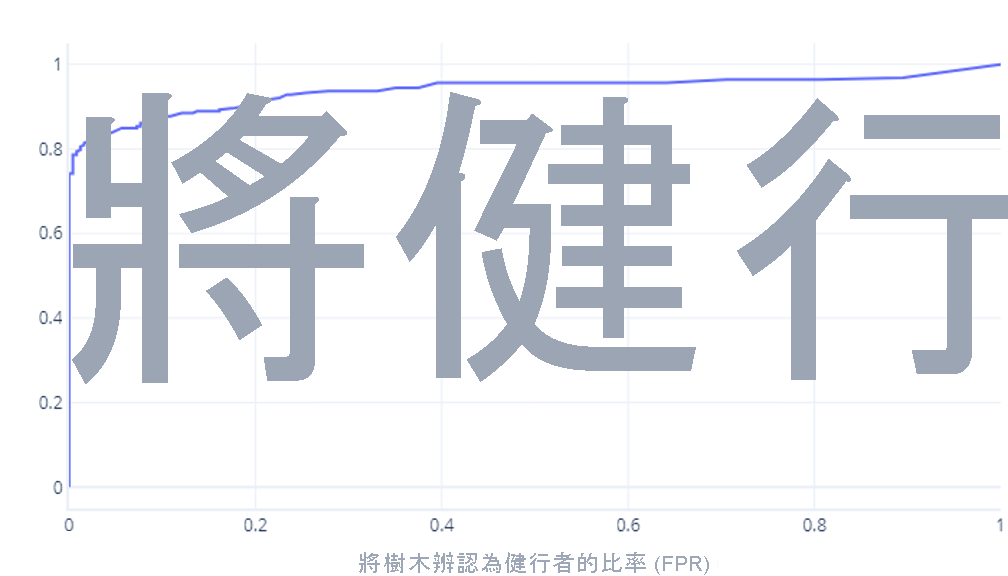
好 ROC、壞 ROC
了解好 ROC 和壞 ROC 曲線最好是在互動式環境中完成。 當您準備好時,請跳至下一個練習,以探索此主題。