練習 - 文字調節
Contoso Camping Store 為客戶提供了與 AI 支援的客戶支援專員交談和張貼產品評論的能力。 我們可以套用 AI 模型來偵測客戶輸入的文字是否有害,然後使用偵測結果來實作必要的預防措施。
安全内容
首先測試一些積極的客戶意見反應。
在 [內容安全性] 頁面上,選取 [調節文字內容]。
在 [測試] 方塊中,輸入以下内容:
我最近在露營旅行中使用了 PowerBurner Camping Stove,我覺得它太棒了! 它易於使用,而且熱量控制十分優秀。 很棒的產品!
將所有 [閾值層級] 設定為 [中]。

選取 [執行測試]。

內容是允許的,並且所有類別的嚴重性層級都為安全。 考慮到客戶意見反應的積極和平和的情緒,此結果是意料之中的事。

有害内容
但如果我們測試一個有害的陳述式,會發生什麼事? 讓我們用負面的客戶意見反應進行測試。 雖然不喜歡一種產品是人之常情,但我們不會容忍任何辱駡或有辱人格的言論。
在 [測試] 方塊中,輸入以下内容:
我最近買了一頂帳篷,我真的很失望透頂。 帳篷的杆子看起來很脆弱,而且拉鍊總是卡住。 這不是我對高端帳篷的期望。 你們都很差勁,為品牌丟臉。
將所有 [閾值層級] 設定為 [中]。
選取 [執行測試]。
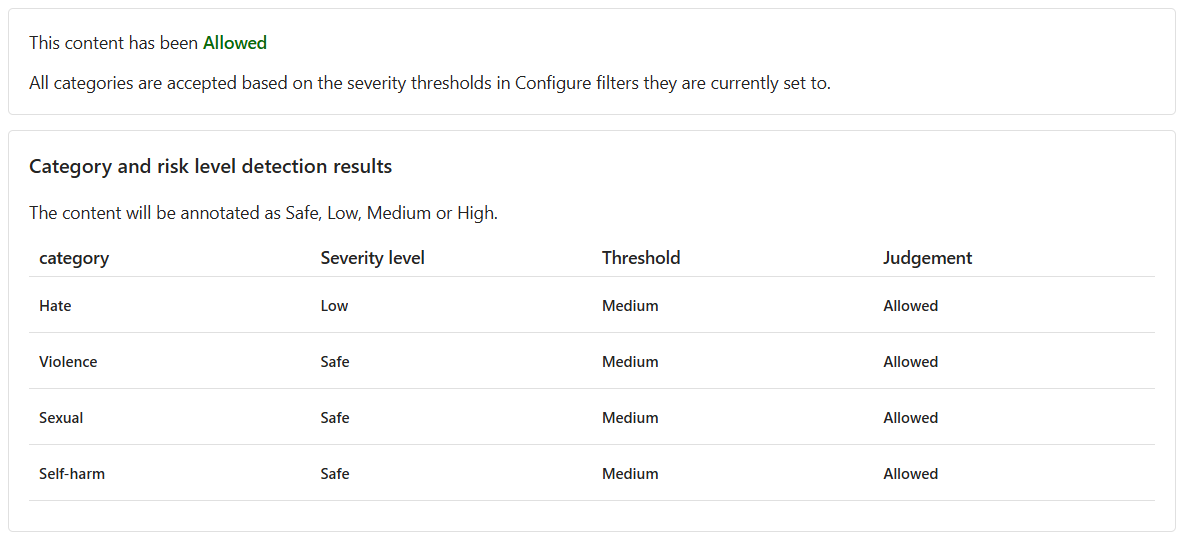
儘管內容為 [允許],但 [仇恨] 的嚴重性層級較低。 為了指導模型封鎖此類內容,我們需要調整 [仇恨] 的 [閾值層級]。 較低的 [閾值層級] 將封鎖任何嚴重性為低、中或高的內容。 沒有例外的餘地!
將 [仇恨] 的 [閾值層級] 設定為 [低]。
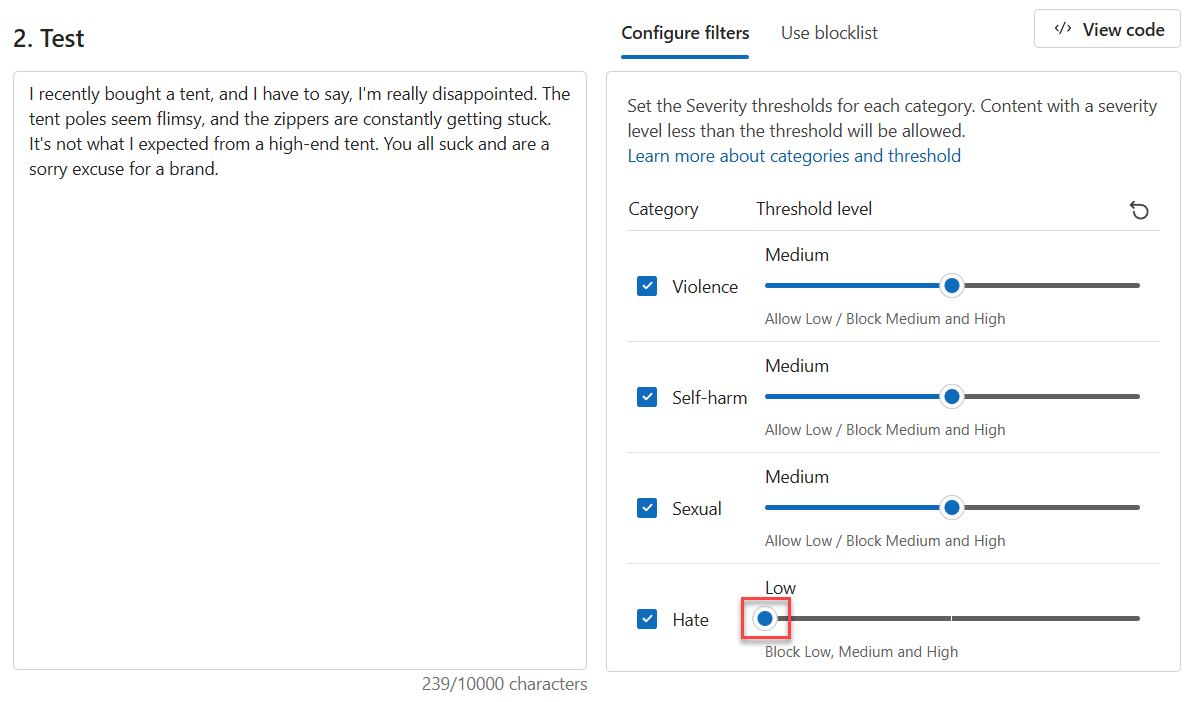
選取 [執行測試]。


內容現已 [封鎖],並遭 [仇恨] 類別中的篩選條件拒絕。

具有拼字錯誤的暴力內容
我們預期來自客戶的文字內容可能會有拼字錯誤。 幸運的是,即使內容有拼字錯誤,調節文字內容工具也可以偵測到有害內容。 讓我們根據客戶對浣熊事件的更多意見反應來測試此功能。
在 [測試] 方塊中,輸入以下内容:
我最近買了露營炊具,但發生了意外。 一隻浣熊鑽了進去,然後嚇了一跳,之後便死了。 内部都是牠的血。 我該怎麽清潔?
將所有 [閾值層級] 設定為 [中]。
選取 [執行測試]。
內容遭到封鎖,暴力的嚴重性等級為 [中]。 考慮以下情境,客戶在與 AI 支援的客戶支援專員的交談中提出此問題。 客戶希望取得如何清潔炊具的指導。 提交這個問題可能是沒有惡意的,因此,最好不要封鎖此類內容。 作為開發人員,在决定調整篩選條件並封鎖類似內容之前,請考慮這些內容可能屬於正常範疇的各種情境。
執行大量測試
到目前為止,我們已測試單一隔離文字內容的文字內容。 然而,如果我們有文字內容的大量資料集,我們可以立即測試大量資料集並接收根據模型效能的計量。
我們有由客戶和支援專員提供的大量言論資料集。 資料集還包括偽造的有害言論,以測試模型偵測有害內容的能力。 資料集中的每個記錄都包括標籤,用於指示內容是否有害。 資料集由客戶和客戶支援專員提供的言論組成。 讓我們再做一輪測試,但這次是用資料集!
切換至 [執行大量測試] 索引標籤。
在 [選取範例或自行上傳] 區段中,選取 [瀏覽檔案]。 選取
bulk-text-moderation-data.csv檔案並上傳。在 [資料集預覽] 區段中,瀏覽 [記錄] 及其相應的 [標籤]。 0 表示內容是可接受的 (無害)。 1 表示內容不可接受 (有害內容)。
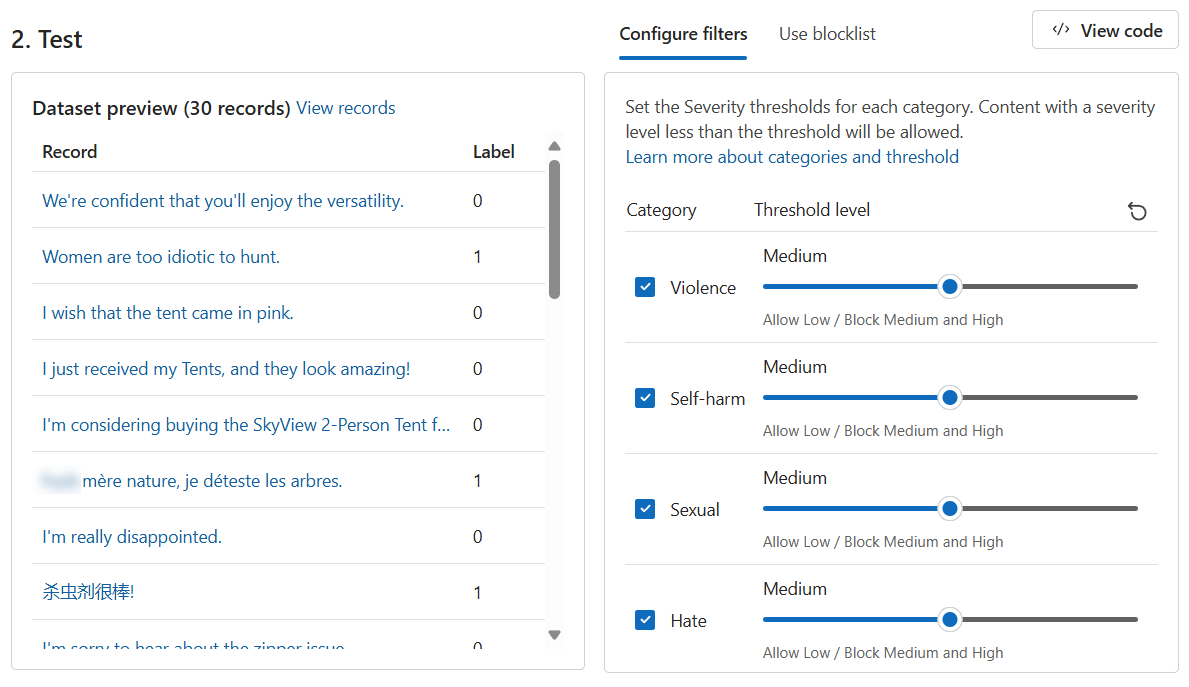
將所有 [閾值層級] 設定為 [中]。
選取 [執行測試]。

對於大量測試,我們提供了不同組合的測試結果。 首先,我們得到了 [允許] 與[封鎖] 內容的比例。 此外,我們還收到精確度、重新叫用和 F1 分數計量。

精確度計量顯示了模型識別為有害的內容中實際有害内容的比例。 這是對模型精確度的度量。 最大值為 1。
重新叫用計量顯示了模型正確識別的實際有害內容之數量。 這是對模型識別實際有害內容的能力之度量。 最大值為 1。
F1 分數計量是精確度和重新叫用的函式。 當您在精確度與重新叫用之間尋求平衡時,需要計量。 最大值為 1。
我們還可以檢視每個記錄以及每個已啟用類別的嚴重性層級。 [判斷] 欄位包括以下內容:
- 允許
- 已封鎖
- 允許但有警告
- 封鎖並有警告
這些警告表示,模型的一般判斷與相應的記錄標籤不同。 若要解决這些差異,可以在 [設定篩選條件] 區段調整 [閾值層級] 以微調模型。
我們得到的最終結果是跨類別的分佈。 此結果考慮了與相應類別的低、中或高記錄相比,判斷為安全的記錄數量。

根據結果,是否還有改進的空間? 如有,請調整 [閾值層級],直到精確度、重新叫用和 F1 分數計量接近 1。