將 Azure AI 搜尋服務解決方案的效能最佳化
您的搜尋解決方案效能可能受到索引的大小和複雜度影響。 您也需要知道如何撰寫有效率的搜尋索引查詢,並選擇正確的服務層級。
接著要探索所有這些層面,並了解您可採取哪些步驟來改善搜尋解決方案的效能。
衡量目前的搜尋效能
不知道搜尋服務的執行效能時,即無法最佳化。 建立基準效能評定才能驗證您所做的改善,但也可以檢查是否會隨時間出現效能降低的情況。
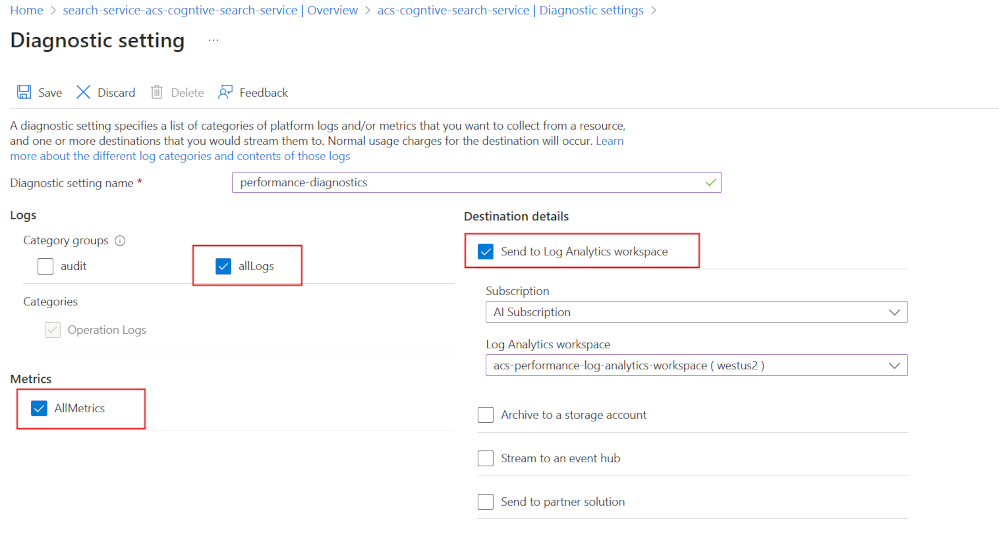
若要開始,請使用 Log Analytics 啟用診斷記錄:
- 在 Azure 入口網站中,選取 [診斷設定]。
- 選取 [+ 新增診斷設定]。

- 指定診斷設定的名稱。
- 選取 [allLogs] 和 [AllMetrics]。
- 選取 [傳送至 Log Analytics 工作區]。
- 選擇或建立 Log Analytics 工作區。
請務必在搜尋服務層級擷取此診斷資訊。 因為終端使用者或應用程式可以在多個環境看到效能問題。

如果您可以證明搜尋服務執行良好,發生效能問題時即可將執行問題排除在可能的因素之外。
檢查搜尋服務是否受到節流
Azure AI 搜尋服務的搜尋和索引編製作業可加以節流。 如果使用者或應用程式已將搜尋作業節流,Log Analytics 會記錄此情況,並附上 503 HTTP 回應。 如果您的索引已受到節流,即會顯示為 207 HTTP 回應。
如果搜尋服務已節流,即可針對搜尋服務記錄執行此查詢。

在 Azure 入口網站中的 [監視] 下,選取 [記錄]。 在 [新增查詢 1] 索引標籤中,您會使用此查詢:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
您可執行命令來查看搜尋服務 HTTP 回應的橫條圖。 在上方橫條圖中,您可以看到數個 503 回應。
檢查個別查詢的效能
測試個別查詢效能的最佳方式是,使用 Postman 等用戶端工具。 您可以使用任何工具,在查詢回應中顯示標頭。 Azure AI 搜尋服務一律會傳回服務完成查詢花費時間的「已耗用時間」值。

如果您想知道傳送和接收用戶端的回應需要多久,請從總來回行程減去已耗用時間。 在上述內容中,需要時間為 125 毫秒減 21 毫秒,所以是 104 毫秒。
將索引大小和結構描述最佳化
搜尋查詢的執行方式直接關聯到索引的大小和複雜度。 索引的規模較小且經過最佳化時,Azure AI 搜尋服務更能快速回應查詢。 如果您發現個別查詢有效能問題,以下一些秘訣可以提供協助。
如果不多加注意,索引就會隨時間成長。 建議您檢查索引中仍然有所相關且必須可供搜尋的所有文件。
如果無法移除任何文件,是否能降低結構描述的複雜度? 相同的欄位是否仍必須可供搜尋? 您是否仍需要用來啟動索引的所有技能?

建議檢查您在每個欄位上啟用的所有屬性。 例如,加入對篩選、Facet 和排序功能的支援,可能會讓支援索引所需的儲存體增為四倍。
注意
欄位上有太多屬性會限制其功能。 例如可供 Facet、篩選和搜尋的欄位,只能儲存 16 KB, 但僅可供搜尋的欄位最多可以保留 16 MB 的文字。
如果您的索引已經過最佳化,但效能仍不理想,請選擇擴大或擴增搜尋服務。
提升查詢的效能
如果您知道搜尋服務的運作方式,即可微調查詢,大幅改善效能。 可使用此檢查清單,撰寫效果更佳的查詢:
- 使用 searchFields 參數,僅指定所需搜尋的欄位。 因為欄位數量更多時,就需要額外的處理能力。
- 盡可能減少需要轉譯至搜尋結果頁面上的傳回欄位數目。 傳回越多資料就需要越多時間。
- 請嘗試避免部分搜尋字詞,例如前置詞搜尋或規則運算式。 這類搜尋的計算成本較高。
- 避免使用高略過值。 這會強制搜尋引擎擷取較大量的資料並排列順位。
- 將可供 Facet 和篩選的欄位的使用限制在低基數資料。
- 使用搜尋函式,而不是篩選準則中的個別值。 例如可使用
search.in(userid, '123,143,563,121',','),而不是$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121。
如果已套用上述所有值,但仍有未執行的個別查詢,請擴增索引。 視您用來建立搜尋解決方案的服務層級而定,最多可以新增 12 個磁碟分割區。 磁碟分割區是索引所在的實體儲存體。 根據預設,所有新的搜尋索引都會以單一磁碟分割區建立。 如果新增更多磁碟分割區,索引會跨分割區儲存。 例如若索引是 200 GB,而您有四個磁碟分割區時,每個分割區會包含 50 GB 的索引。
新增額外的磁碟分割區有助於效能,因為搜尋引擎可以在每個分割區中平行執行。 在傳回大量文件和使用 Facet 提供大量文件計數的查詢上,會看到最大的改善效果。 這是評分文件相關度的計算成本高低因素。
針對搜尋需求使用最佳服務層級
您已了解新增更多磁碟分割區,可以擴增服務層級。 因為負載增加需要調整時,可以擴增複本。 您也可以使用較高層級來擴大搜尋服務。

上述兩個搜尋索引的大小為 200 GB。 S1 層使用八個磁碟分割區,而 S2 層只使用兩個。 這兩個層級都有兩個複本,且成本大致相同。 若要選擇搜尋解決方案的最佳層級,您必須知道所需儲存體大約的總計大小。 目前支援的最大索引是提供總計 24 TB、L2 層中的 12 個磁碟分割區。
| 層 | 類型 | 儲存體 | 複本 | 資料分割 |
|---|---|---|---|---|
| F | 免費 | 50 MB | 1 | 1 |
| B | 基本 | 2 GB | 3 | 1 |
| S1 | 標準 | 25 GB/分割區 | 12 | 12 |
| S2 | 標準 | 100 GB/分割區 | 12 | 12 |
| S3 | 標準 | 200 GB/分割區 | 12 | 12 |
| S3HD | 高密度 | 200 GB/分割區 | 12 | 3 |
| L1 | 儲存體最佳化 | 1 TB/分割區 | 12 | 12 |
| L2 | 儲存體最佳化 | 2 TB/分割區 | 12 | 12 |
上述範例中的兩個層級,您認為何者效能最佳? 您已了解基於平行處理原則,擴增可以提供效能優勢。 但較高層級也隨附進階儲存體、更強大的計算資源和額外的記憶體。 選擇第二個選項可提供更強大的基礎結構,讓日後的索引得以繼續成長。 但哪個層級執行的效能最佳,取決於索引的大小和複雜度,及您撰寫的搜尋索引查詢。 換句話說,兩者都可能是最合適的選擇。
若要規劃搜尋解決方案日後在使用上的成長,即需考慮搜尋單位。 搜尋單位 (SU) 是複本和磁碟分割區的乘積。 所以上述 S1 層使用 16 SU ,而 S2 層只使用 4 SU。 成本類似每個 SU 的較高層級費用。
需考慮到因為負載增加而調整搜尋解決方案的需求。 新增另一個複本至這兩個層級會增加 S1 層為 24 SU,但 S2 層只增加為 6 SU。