定義監督式學習
將模型定型的流程可以是監督式或非監督式。 我們的目標是對比這些方法,然後深入探討該學習流程,並著重於監督式學習。 在這段討論中有一點值得注意,監督式學習與非監督式學習的唯一差異在於目標函式的運作方式。
何謂非監督式學習?
在非監督式學習中,我們會在不知道正確答案的情況下來將模型定型以解決問題。 事實上,非監督式學習通常用於沒有單一正確答案的問題,而是要分辨更好或更糟的解決方案。
假設我們希望機器學習模型能夠繪製雪崩搜救犬隻的寫實圖片。 沒有一幅要繪製的「正確」繪圖。 只要影像看起來有點像隻狗,我們就很滿意了。 但是,如果產生的影像是貓,那就是一個更糟的解決方案。
別忘了,定型作業需要多個要素:
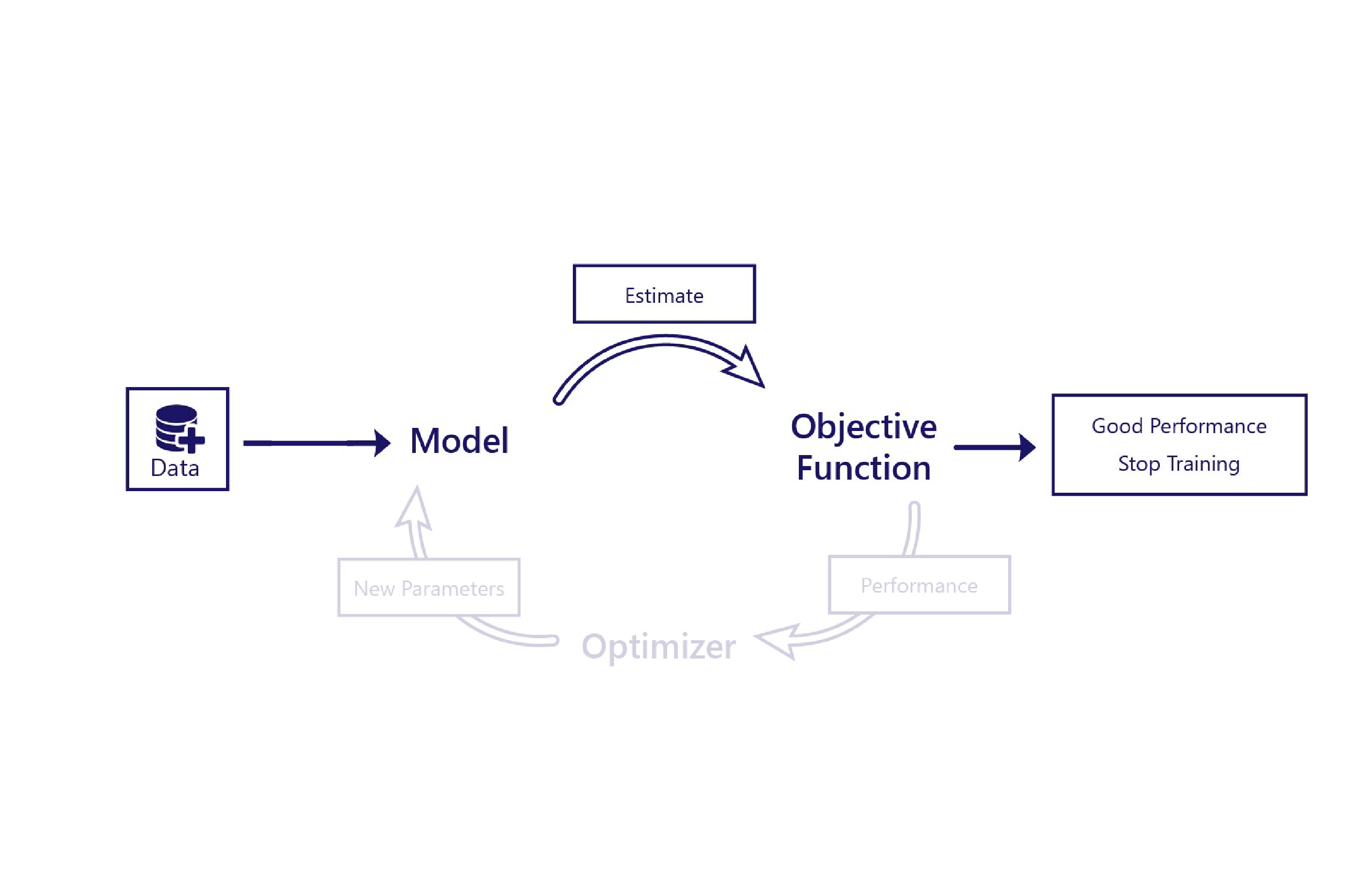
在非監督式學習中,目標函式會單純地根據模型的估計值做出判斷。 這表示目標函式通常需要相對的複雜性。 例如,目標函式可能需要包含「犬隻偵測器」,來評估模型繪製的影像是否看起來很寫實。 非監督式學習所需的唯一資料是特徵,即我們提供給模型的資料。
何謂監視式學習?
將監督式學習視為依照範例的學習。 在監督式學習中,我們會透過比較模型的預估值與正確答案來評定其效能。 雖然我們可以有簡單的目標函式,但我們需要以下兩者:
- 提供來作為模型輸入的特徵
- 標籤,其為我們希望模型能夠產生的正確答案
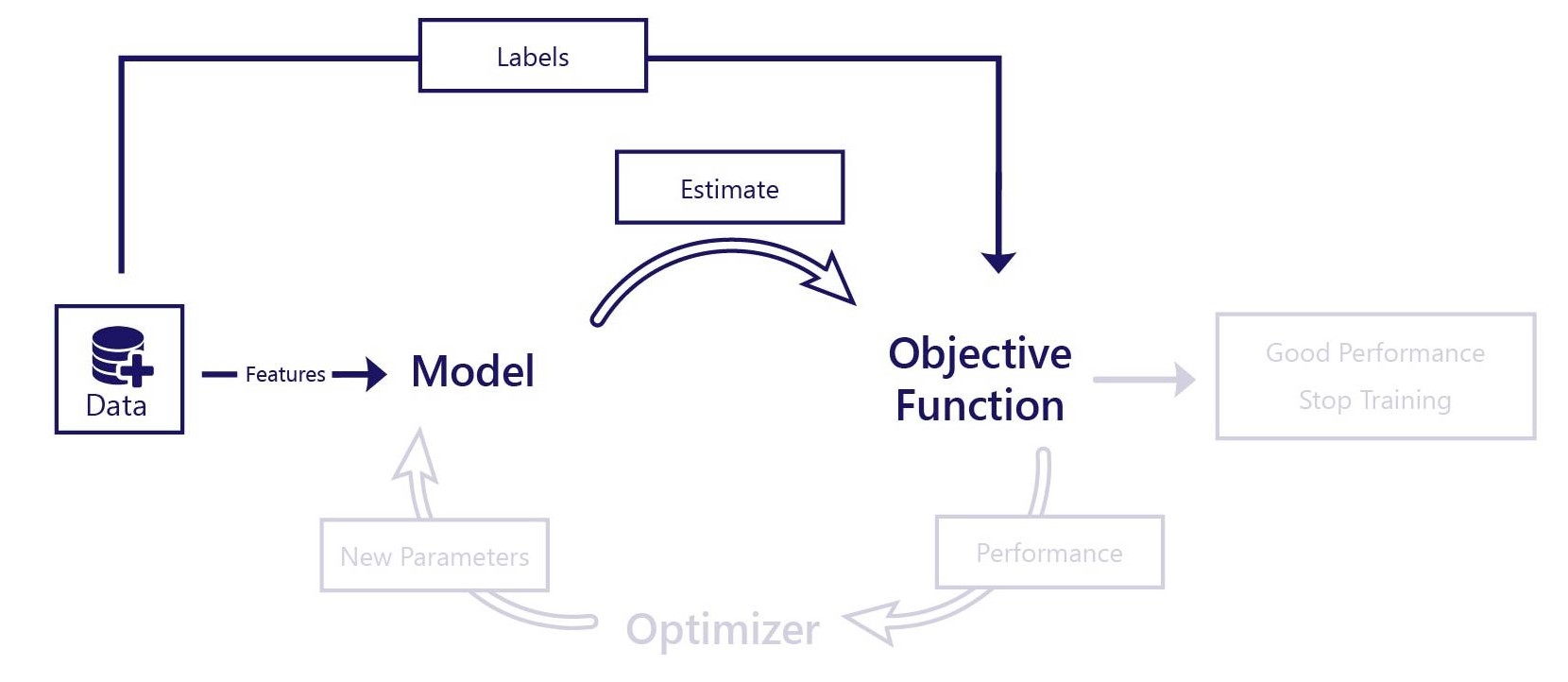
例如,假設我們想要預測某個指定年份 1 月 31 日的溫度。 針對此預測,我們需要具有兩個元件的資料:
- 特徵:日期
- 標籤:每日溫度 (例如來自歷史記錄)
在此案例中,我們為模型提供日期特徵。 此模型會預測溫度,而我們會將此結果與資料集的「正確」溫度進行比較。 然後,目標函式可以計算模型的運作效能,而我們可以調整模型。
標籤僅供學習使用
務必記住,無論模型如何定型,它們都只會處理特徵。 在監督式學習期間,目標函式是唯一依賴標籤存取權的元件。 定型之後,我們不需要標籤來使用模型。