HdInsight 設定選項
HDInsight 具有內嵌在其中的各種 OSS 技術,可用於處理串流和批次資料案例,這些案例均定義於 Lambda 架構內。 在此架構模型中,具有資料的最忙碌路徑和資料的冷路徑。 裝置、感應器或應用程式會即時產生資料的最忙碌路徑,而資料分析會以近乎即時的方式執行,這通常稱為串流資料。 冷資料路徑是批次移動資料的時機,一般是從其他資料存放區,而且通常稱為批次資料。
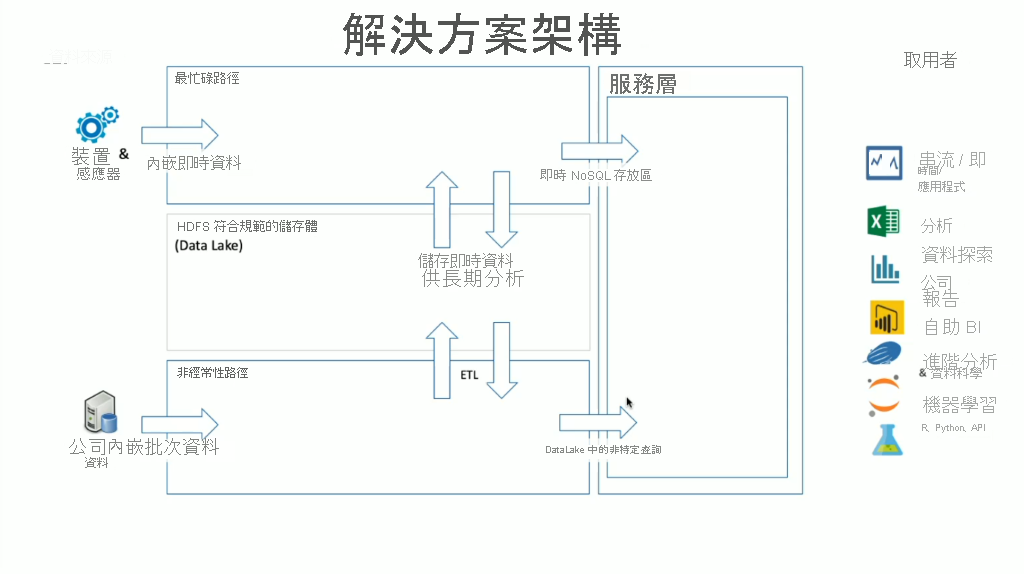
實作 HDInsight 時,資料的儲存體會保留於符合規範的 Hadoop 分散式檔案系統 (HDFS) 中。 在 Azure 中,Data Lake Gen2 通常用來作為資料存放區,因為它符合 HDFS 規範。 來自最忙碌路徑與冷路徑的資料會在處理後,儲存於名為 Data Lake 的集中式資料存放區中。 Data Lake 本身可劃分來將資料保存於不同區間,而這些區間可透過資料的狀態 (登陸區域、轉換區域等)、存取需求 (經常性、一般性及非經常性) 與業務群組來定義。 服務層是資料湖中的最後一個區間,會以可供各種類型的取用者取用的格式來保存資料。
重要的是,HDInsight 的計算層面會處理串流或批次資料的處理,而且可能根據您在佈建 HDInsight 叢集時選取的叢集類型而有所不同。 HDInsight 會在個別的叢集選項中提供服務,如下表所示。
| 叢集類型 | 說明 |
|---|---|
| Apache Hadoop \(英文\) | 使用 HDFS 和簡單 MapReduce 程式設計模型的架構,用來處理和分析批次資料。 |
| Apache Spark | 開放原始碼的平行處理架構,可支援記憶體內部處理,以大幅提升巨量資料分析應用程式的效能。 |
| hbase | 建置於 Hadoop 上的 NoSQL 資料庫,可針對大量非結構化及半結構化資料 (可能是數十億個資料列乘以數百萬個資料行) 提供隨機存取功能和強大的一致性。 |
| Apache Interactive Query | 更快速進行互動式 Hive 查詢的記憶體內部快取。 |
| Apache Kafka | 用來建置串流資料管線和應用程式的開放原始碼平台。 Kafka 也提供訊息佇列功能,可讓您發佈和訂閱資料流。 |
因此,務必選取正確的叢集類型,以符合您嘗試解決的業務案例。 不論選取的叢集類型為何,叢集內部也會新增額外的開放原始碼元件來提供額外功能,包括:
Hadoop 管理
HCatalog - 適用於 Hadoop 的資料表和儲存體管理層
Apache Ambari - 有助於管理及監視 Apache Hadoop 叢集
Apache Oozie - 用於管理 Apache Hadoop 作業的工作流程排程器系統
Apache Hadoop YARN - 管理資源管理及作業排程/監視
Apache ZooKeeper - 用於維護設定資訊、命名、提供分散式同步處理,以及提供群組服務的集中式服務。
資料處理
Apache Hadoop MapReduce - 可輕鬆撰寫應用程式來處理大量資料的架構
Apache Tez - 用於處理資料的應用程式架構
Apache Hive - 有助於使用 SQL 來管理位於分散式儲存體的大型資料集
資料分析
Apache Pig – 透過 MapReduce 提供抽象層來分析大型資料集
Apache Phoenix - 在 Hadoop 中啟用 OLTP 和作業分析
Apache Mahout – 一種代數架構,可建立您自己的演算法
注意
撰寫本文時,Azure Data Lake Gen1 和 Azure Blob 儲存體均為支援 HDInsight 的資料儲存層。 您應該查看如何將此資料遷移至 Azure Data Lake Gen2,因為它是建議用於 Spark 和 Hadoop 的儲存體平台,也是適用於 HBase 的預設選項。