使用 Microsoft Fabric Lakehouse
由於您已了解 Microsoft Fabric 湖存放庫的核心功能,就讓我們來探索如何使用。
建立和探索 Lakehouse
建立新的湖存放庫時,便會在工作區中自動建立三個不同的資料項目。
- 湖存放庫包含捷徑、資料夾、檔案和資料表。
- 語意模型 (預設值) 為 Power BI 報告開發人員提供簡單的資料來源。
- SQL 分析端點允許使用 SQL 對查詢資料進行唯讀存取。
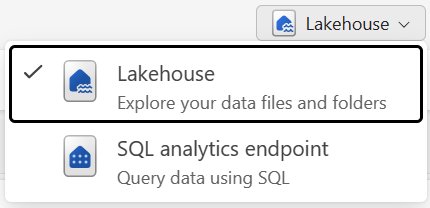
您可以在兩種模式中使用 Lakehouse 中的資料:
- 湖存放庫可讓您在湖存放庫中新增資料表、檔案和資料夾並與其互動。
- SQL 分析端點可讓您使用 SQL 來查詢 Lakehouse 中的資料表,並管理其關聯式語意模型。
將資料內嵌至 Lakehouse
將資料內嵌到湖存放庫是 ETL 流程中的第一步。 使用下列任一方法,將資料帶入湖存放庫。
- 上傳:上傳本機檔案。
- 資料流程 Gen2:使用 Power Query 匯入和轉換資料。
- 筆記本:使用 Apache Spark 來內嵌、轉換和載入資料。
- 資料處理站管線:使用複製資料活動。
然後,可以直接將此資料載入檔案或資料表。 在內嵌資料時,請考慮資料載入模式,以判斷您是否應該先將所有未經處理資料載入為檔案,然後再處理或使用暫存資料表。
Spark 作業定義也可用來將批次/串流作業提交至 Spark 叢集。 藉由從不同語言的編譯輸出上傳二進位檔(例如,從 Java .jar),您可以將不同的轉換邏輯套用至 Lakehouse 上裝載的資料。 除了二進位檔,您可以上傳更多連結庫和命令行自變數,進一步自定義作業的行為。
注意
如需詳細資訊,請參閱建立 Apache Spark 作業定義文件。
使用捷徑存取資料
另一種在 Fabric 中存取和使用資料的方式是使用捷徑。 捷徑可讓您將資料整合到您的 Lakehouse,同時將其儲存在外部儲存體中。
當您需要在不同的儲存體帳戶,甚至是不同的雲端提供者中來源資料時,捷徑會很有用。 在湖存放庫中,您可以建立指向不同儲存體帳戶和其他 Fabric 項目的捷徑,例如資料倉儲、KQL 資料庫和其他湖存放庫。
來源資料權限和認證全都由 OneLake 管理。 透過捷徑存取另一個 OneLake 位置的資料時,會利用呼叫使用者的身分識別來授權存取捷徑之目標路徑中的資料。 使用者必須具有目標位置的權限,才能讀取資料。
您可以在 Lakehouses 和 KQL 資料庫中建立捷徑,並在 Lake 中顯示為資料夾。 這可讓 Spark、SQL、Real-Time 智慧和 Analysis Services 在查詢資料時使用捷徑。
注意
如需詳細資訊,請參閱 Microsoft Fabric 文件中的 OneLake 捷徑文件。