使用 Microsoft Fabric 探索及處理資料
資料是資料科學的基礎,特別是在將機器學習模型定型以實現人工智慧時。 一般而言,當訓練資料集大小增加時,模型會展現增強的效能。 除了資料數量之外,資料的品質也同樣重要。
為了保證資料的品質和數量,使用 Microsoft Fabric 的強固資料擷取和處理引擎很值得。 建立基本資料擷取、探索和轉換管線時,您可以彈性選擇低程式碼或程式碼優先方法。
將資料內嵌至 Microsoft Fabric
若要在 Microsoft Fabric 中使用資料,您必須先擷取資料。 您可以內嵌來自多個來源的資料,包括本機和雲端資料來源。 例如,您可以從儲存在本機電腦上的 CSV 檔案或 Azure Data Lake Storage (Gen2) 內嵌資料。
提示
深入瞭解如何 使用 Microsoft Fabric 擷取及協調各種來源的資料。
連線到資料來源之後,您就可以將資料儲存到 Microsoft Fabric Lakehouse。 您可以使用 Lakehouse 作為中央位置來儲存任何結構化、半結構化和非結構化檔案。 然後,每當您想要存取資料以進行探索或轉換時,您就可以輕鬆地連線到 Lakehouse。
探索並轉換您的資料
作為資料科學家,您可能非常熟悉如何在 筆記本 中撰寫和執行程式碼。 Microsoft Fabric 提供熟悉的筆記本體驗,由 Spark 計算提供。
Apache Spark 是用於大規模資料處理和分析的開放原始碼平行處理架構。
Notebook 會自動附加至 Spark 計算。 當您第一次在筆記本中執行資料格時,就會啟動新的 Spark 工作階段。 當您執行後續的儲存格時,工作階段會持續存在。 Spark 工作階段會在一段時間閒置後自動停止,以節省成本。 您也可以手動停止該工作階段。
當您在筆記本中工作時,可以選擇要使用的語言。 針對資料科學工作負載,您可能會使用 PySpark (Python) 或 SparkR (R) 作業。
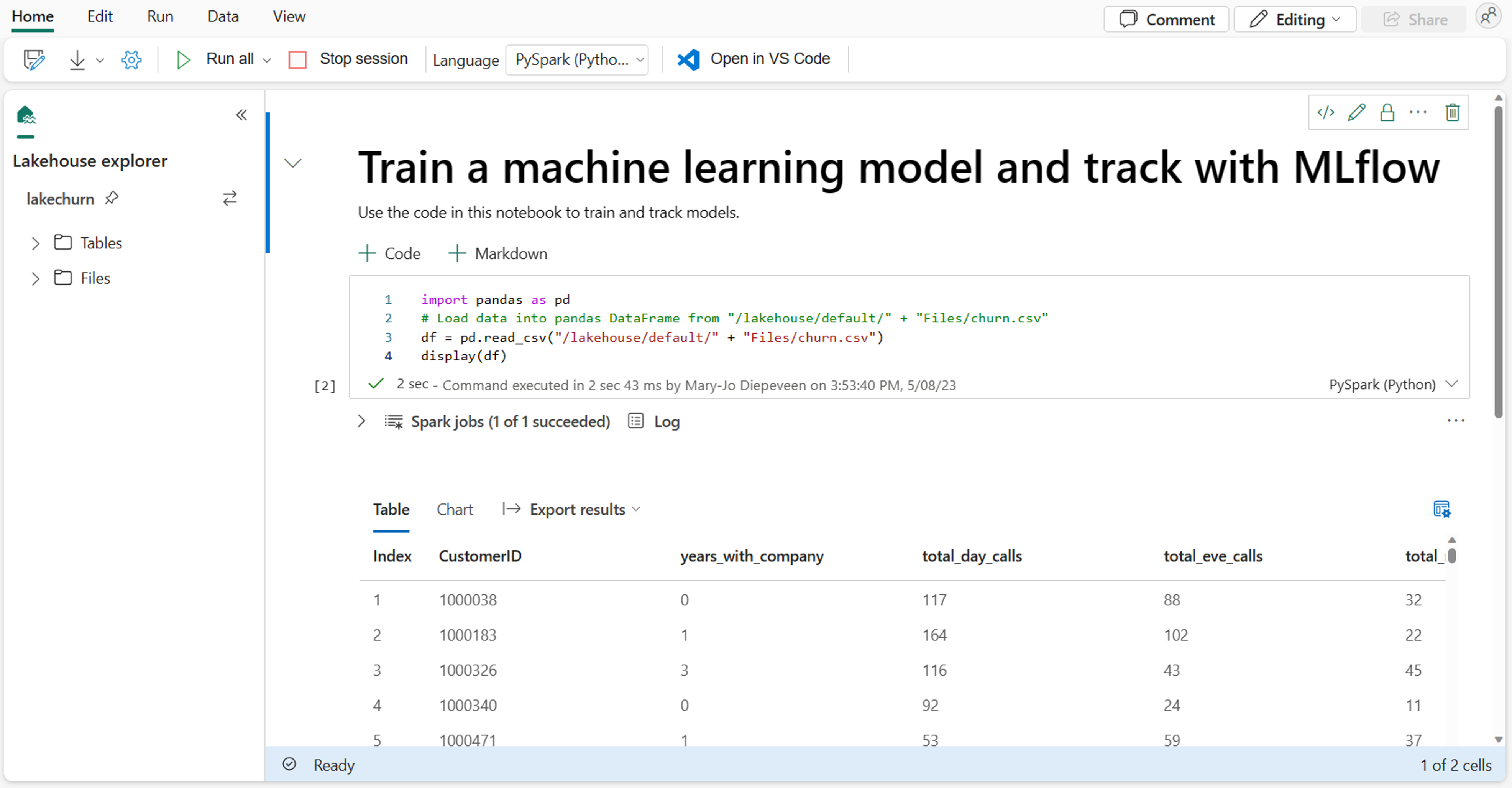
在筆記本中,您可以使用慣用的程式庫,或任何內建視覺效果選項來探索資料。 如有必要,您可以轉換資料,並將已處理的資料寫回 Lakehouse 來儲存。
使用 Data Wrangler 準備您的資料
為了協助您更快速地探索和轉換資料,Microsoft Fabric 提供便於使用的 Data Wrangler。
啟動 Data Wrangler 之後,您將取得所使用資料的描述性概觀。 您可以檢視資料的摘要統計資料,以找出任何像是遺漏值的問題。
若要清除您的資料,您可以選擇任何內建的資料清理作業。 當您選取作業時,系統會自動為您產生結果預覽和相關聯的程式碼。 當您選取所有必要的作業時,您可以將轉換匯出至程式碼,並在您的資料上執行。