多類別分類
多類別分類是用來預測觀察所屬多個可能類別的哪一個。 作為監督式機器學習技術,其會遵循與迴歸和二元分類相同的反復定型、驗證和評估流程,在其中保留定型資料的子集以驗證定型模型。
範例 - 多類別分類
多類別分類演算法可用來計算多個類別標籤的機率值,讓模型能夠預測指定觀察的最可能類別。
讓我們探索一個範例,其中有一些企鵝的觀察,其中會記錄每隻企鵝的鰭肢長度 (x)。 針對每個觀察,資料包括企鵝物種 y (y),其編碼方式如下:
- 0:阿德利
- 1:巴布亞
- 2:南極
注意
如同本課程模組先前的範例,實際案例會包含多個特徵 (x) 值。 我們將使用單一特徵來保持簡單。
 |
 |
|---|---|
| 鰭肢長度 (x) | 物種 (y) |
| 167 | 0 |
| 172 | 0 |
| 225 | 2 |
| 197 | 1 |
| 189 | 1 |
| 232 | 2 |
| 158 | 0 |
定型多類別分類模型
若要定型多類別分類模型,我們需要使用演算法,將定型資料放入計算每個可能類別機率值的函式。 您可以使用兩種演算法來執行此動作:
- 一對多 (OvR) 演算法
- 多項式演算法
一對多 (OvR) 演算法
一對多演算法會為每個類別定型二元分類函式,每個都會計算觀察為目標類別範例的可能性。 每個函式都會計算與任何其他類別相較之下,觀察為特定類別的可能性。 針對我們的企鵝物種分類模型,演算法基本上會建立三個二元分類函式:
- f0(x) = P(y=0 | x)
- f1(x) = P(y=1 | x)
- f2(x) = P(y=2 | x)
每個演算法都會產生 sigmoid 函式,計算介於 0.0 到 1.0 之間的機率值。 使用這種演算法定型的模型會預測產生最高機率輸出之函式的類別。
多項式演算法
另一種方法是使用多項式演算法,這會建立傳回多重值輸出的單一函式。 輸出是一個向量 (值陣列),其中包含所有可能類別的機率分佈 - 每個類別的機率分數,總計最多為 1.0 時:
f(x) =[P(y=0|x), P(y=1|x), P(y=2|x)]
此類函式的範例是 softmax 函式,可能會產生類似下列範例的輸出:
[0.2, 0.3, 0.5]
向量中的元素分別代表類別 0、1 和 2 的可能性;因此,在此情況下,機率最高的類別為 2。
不論使用哪一種演算法類型,模型都會使用產生的函式來判斷指定一組特徵 (x) 的最可能類別,並預測對應的類別標籤 (y)。
評估多類別分類模型
您可以計算每個個別類別的二元分類計量,以評估多類別分類器。 或者,您可以計算將所有類別納入考慮的彙總計量。
假設我們已驗證多類別分類器,並取得下列結果:
| 鰭肢長度 (x) | 實際物種 (y) | 預測的物種 (ŷ) |
|---|---|---|
| 165 | 0 | 0 |
| 171 | 0 | 0 |
| 205 | 2 | 1 |
| 195 | 1 | 1 |
| 183 | 1 | 1 |
| 221 | 2 | 2 |
| 214 | 2 | 2 |
多類別分類器的混淆矩陣與二元分類器的混淆矩陣類似,不同之處在於其會顯示每個預測 (ŷ) 和實際類別標籤 (y) 的預測數目:
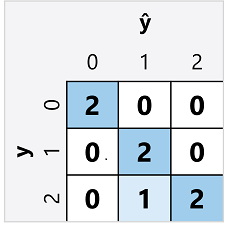
從這個混淆矩陣中,我們可以判斷每個個別類別的計量,如下所示:
| 類別 | TP | TN | FP | FN | 準確率 | 重新叫用 | 精確度 | F1 分數 |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | 5 | 0 | 0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 1 | 2 | 4 | 1 | 0 | 0.86 | 1.0 | 0.67 | 0.8 |
| 2 | 2 | 4 | 0 | 1 | 0.86 | 0.67 | 1.0 | 0.8 |
若要計算整體正確性、叫用率和精確度計量,您可以使用 TP、 TN、 FP和 FN 計量總計:
- 整體正確性 = (13+6) ÷ (13+6+1+1) = 0.90
- 整體叫用率 = 6÷(6+1) = 0.86
- 整體精確度 = 6÷ (6+1) = 0.86
整體 F1 分數是使用整體叫用率和精確度計量來計算:
- 整體 F1 分數 = (2x0.86x0.86) ÷ (0.86+0.86) = 0.86