什麼是語言模型?
生成式 AI 應用程式由語言模型支援,這是一種特殊類型的機器學習模型,可用來執行自然語言處理 (NLP) 工作,包括:
- 判斷 情感 或分類自然語言文字。
- 摘要文字。
- 比較多個文字來源的語意相似性。
- 產生新的自然語言。
雖然這些語言模型背後的數學原則可能十分複雜,但對用來實作之結構的基本了解,可協助您了解其運作方式的概念。
轉換程式模型
自然語言處理的機器學習模型已有多年的演進。 現今的先進大型語言模型是以 轉換程式 架構為基礎,其構建並擴充了一些技術,這些技術在為支持 NLP 工作的 詞彙 建模方面,已經被證明是成功的 - 特別是在生成語言方面。 轉換程式模型使用大量的文字進行訓練,讓模型能夠代表單字之間的語意關聯性,並使用這些關聯性來判斷可能有意義的文字序列。 具有夠大的詞彙的轉換程式模型能夠產生難以與人類回應區別開來的語言回應。
轉換程式模型架構包含兩個元件或 區塊:
- 建立訓練詞彙語意表示的 編碼器 區塊。
- 生成新語言序列的 解碼器 區塊。
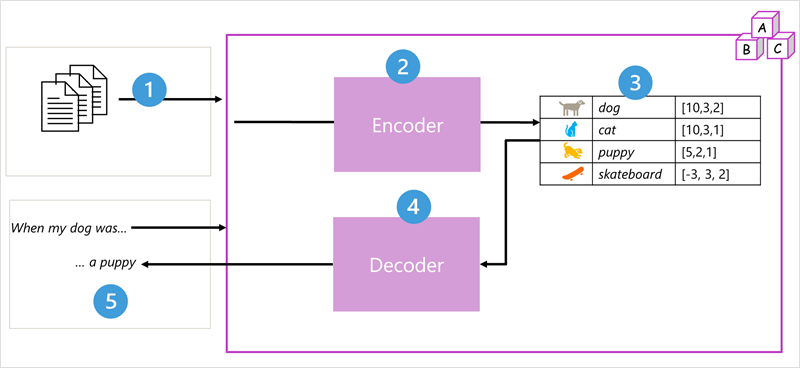
- 會使用大量自然語言文字定型此模型,這些文字的來源通常是網際網路或其他公開文字來源。
- 文字序列會細分成語彙基元 (例如個別單字),而編碼器區塊會使用名為注意的技術以處理這些語彙基元序列,以判斷語彙基元之間的關聯性 (例如,哪些語彙基元會影響序列中其他語彙基元的存在、通常用於相同脈絡中的不同語彙基元等)。
- 編碼器的輸出是向量集合 (多重值數值陣列),其中向量的每個元素都代表詞元的語意屬性。 這些向量稱為內嵌。
- 解碼器區塊適用於新的文字詞元序列,並使用編碼器所產生的內嵌,以產生適當的自然語言輸出。
- 例如,假設有類似「我的狗當時」的輸入序列,此模型可以使用注意技術,分析在內嵌中編碼的輸入語彙基元和語意屬性,以預測句子的適當完成,例如「一隻小狗」。
在實踐上,該架構的具體實作會有所不同 - 例如,Google 為支援其搜尋引擎而開發的轉換程式 (BERT) 模型的雙向編碼器標示法僅使用編碼器區塊,而 OpenAI 所開發的生成預先訓練轉換程式 (GPT) 模型僅使用解碼器區塊。
雖然轉換程式模型的各個層面的完整說明超出本課程模組的範圍,但轉換程式中某些重要元素的說明可協助您瞭解其支援 AI 的方式。
語彙基元化
訓練轉換程式模型的第一個步驟是將訓練文字分解成 語彙基元 - 換句話說,識別每個唯一的文字值。 簡單起見,您可以將訓練文字中的每個不同字視為一個語彙基元 (但實際上,語彙基元可以針對部分單字產生,或單字和標點符號的組合)。
例如,您可以參考以下句子:
I heard a dog bark loudly at a cat
若要語彙基元化此文字,您可以識別每個離散字組,並將語彙基元識別碼指派給它們。 例如:
- I (1)
- heard (2)
- a (3)
- dog (4)
- bark (5)
- loudly (6)
- at (7)
- *("a" is already tokenized as 3)*
- cat (8)
句子現在可以透過語彙基元來表示:{1 2 3 4 5 6 7 3 8}。 同樣地,「我聽到貓的聲音」的句子可以表示為 {1 2 3 8}。
隨著您繼續訓練模型,訓練文字中的每個新語彙基元都會新增至具有適當語彙基元識別碼的詞彙:
- 喵 (9)
- 滑板 (10)
- 依此類推...
使用一組夠大的訓練文字,便可以編譯數千個語彙基元的詞彙。
Embeddings
雖然將語彙基元表示為簡單識別碼可能很方便 - 基本上,這可為詞彙中的所有單字建立索引,但不會告訴我們任何單字相關的意涵,或它們之間的關聯性。 為了建立一個詞彙來封裝語彙基元之間的語意關聯性,我們會為其定義稱為 內嵌 的內容向量。 向量是資訊的多重數值標記法,例如 [10, 3, 1] ,其中每個數值元素都代表資訊的特定屬性。 對於語言標記,語彙基元向量的每個元素都代表語彙基元的一些語意屬性。 語言模型中向量元素的特定類別會根據在訓練期間,根據一般字組在一起使用或類似內容的方式來決定。
向量代表多維空間中的線條,描述沿著多個軸的方向和距離 (您可以將其稱為幅度和量級,讓數學家朋友留下深刻印象)。 將詞元內嵌向量中的元素視為在多維空間中沿著路徑的表示步驟非常有用。 例如,具有三個元素的向量代表 3 維空間中的路徑,其中元素值表示向前/向後、向左/右和向上/向下移動的單位。 整體而言,向量描述從原點到終點的路徑方向和距離。
內嵌空間中的詞元元素各代表詞元的一些語意屬性,因此語意類似的詞元應該會產生方向類似的向量:換言之,其會指向相同方向。 稱為餘弦相似性的技術可用來判斷兩個向量是否有類似的方向 (而不論距離為何),因此可代表語意相關的字組。 例如,假設語彙基元的內嵌包含三個元素的向量,例如:
- 4 ([狗]): [10.3.2]
- 8 ([貓]): [10,3,1]
- 9 (「小狗」): [5,2,1]
- 10 ([滑板]): [-3,3,2]
我們可以如下所示,在 3D 空間中繪製這些向量:
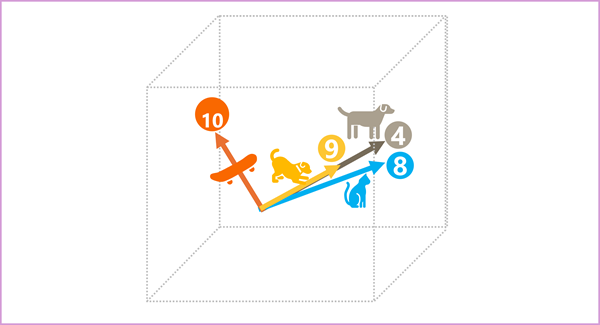
「狗」和「小狗」的內嵌向量描述沿著幾乎完全相同的方向的路徑,這與「貓」的方向也相當類似。 然而,「滑板」內嵌向量的旅程描述方向卻截然不同。
注意
上一個範例顯示簡單的範例模型,其中每個內嵌只有三個維度。 實際語言模型有更多維度。
您可以使用多種方式來計算指定語彙基元集的適當內嵌,包括 Word2Vec 之類的語言模型化演算法,或轉換程式模型中的 編碼器 區塊。
注意
轉換程式模型中的 編碼器 和 解碼器 區塊包含多層,構成模型的類神經網路。 我們不需要進入所有這些圖層的詳細資料,但考慮這兩個區塊中使用的其中一種圖層會很實用: 注意 層。 [注意] 是用來檢查文字語彙基元序列的技術,並嘗試量化它們之間的關聯性強度。 特別是,[自我注意] 牽涉到考慮一個特定語彙基元周圍的其他語彙基元如何影響語彙基元的意義。
在編碼器區塊中都會仔細檢查內容中的每個權杖,並判斷其向量內嵌的適當編碼方式。 向量值是以語彙基元和經常與之搭配出現之其他語彙基元間的關聯性為基礎。 此內容化方法表示同一個字組可能會有多個內嵌,視使用的內容而定,例如「樹狀結構直條」和「我聽到狗吠」有不同的意義。
在解碼器區塊中,注意層是用來預測序列中的下一個語彙基元。 針對產生的每個語彙基元,模型都有一個注意層,它會將語彙基元序列納入到該點為止。 模型會考慮在考量下一個語彙基元應是什麼時,哪些語彙基元會最具影響力。 例如,假設序列「我聽到狗」,注意層可能會在考慮序列中的下一個單字時,將更大的權數指派給語彙基元「聽到」和「狗」:
我聽到狗 [吠]
請記住,注意層正使用語彙基元的數值向量標記法,而不是實際文字。 在解碼器中,程序會以代表要完成之文字的語彙基元內嵌序列開始。 發生的第一件事是,另一個 位置編碼 層會將值新增至每個內嵌,以指出其在序列中的位置:
- [1,5,6,2] (我)
- [2,9,3,1] (聽到)
- [3,1,1,2] (一隻)
- [4,10,3,2] (狗)
在訓練期間,目標是根據上述標記預測序列中最終語彙基元的向量。 注意層目前為止會將數值 權數 指派給序列中的每個語彙基元。 它會使用該值在加權向量上執行計算,產生 注意力分數,以用來計算下一個語彙基元的可能向量。 實際上,稱為 多頭注意 的技術會使用內嵌的不同元素來計算多個注意力分數。 然後,神經網路會用來評估所有可能的語彙基元,以判斷要繼續序列的最可能語彙基元。 此程序會針對序列中的每個語彙基元反覆運算,到目前為止,輸出序列會以迴歸方式作為下一個反覆運算的輸入,基本上一次建置一個語彙基元的輸出。
下列動畫顯示此運作方式的簡化標記法 - 事實上,注意力層執行的計算更為複雜;但原則可以簡化,如下所示:

- 語彙基元內嵌的序列會饋送至注意層。 每個語彙基元都會以數值的向量表示。
- 解碼器的目標是預測序列中的下一個語彙基元,這也是對齊模型詞彙中內嵌的向量。
- 注意層到目前為止會評估序列,並將權數指派給每個語彙基元,以代表其對下一個語彙基元的相對影響力。
- 權數可用來計算具有注意分數的下一個語彙基元的新向量。 多頭注意會使用內嵌中的不同元素來計算多個替代語彙基元。
- 完全連接的類神經網路會使用計算向量中的分數,從整個詞彙預測最可能語彙基元。
- 到目前為止,預測輸出會附加至序列,做為下一個反覆運算的輸入。
在訓練期間,已知語彙基元實際順序 – 我們只會遮罩序列中稍後的語彙基元位置,而非目前考慮的語彙基元位置。 如同任何神經網路,語彙基元向量的預測值會與序列中下一個向量的實際值進行比較,並計算損失。 然後會累加調整權數,以減少損失並改善模型。 用於推斷 (預測新語彙基元序列) 時,訓練的注意層會套用加權,以預測模型詞彙中最可能且目前為止以語意方式對齊序列的語彙基元。
這表示,GPT-4 之類的轉換程式模型 (ChatGPT 和 Bing) 背後的模型,其旨在採用文字輸入 (稱為提示),並產生語法正確的輸出 (稱為完成)。 實際上,模型的「魔法」在於將一致的句子串在一起的能力。 這項功能並不表示模型部分的任何「知識」或「智慧」;只是大型詞彙,以及產生有意義的單字序列的能力。 不過,GPT-4 這類大型語言模型的功能非常強大,就是其經過訓練的資料量 (網際網路的公用和授權資料),以及網路的複雜度。 這可讓模型根據模型訓練詞彙中的單字之間的關聯性來產生完成;通常會產生難以從人類回應到相同提示作出區別的輸出。