探索 Azure Machine Learning 中的微調基礎模型
若要從 Azure Machine Learning 中的模型目錄微調基礎模型,您可以使用工作室、Python SDK 或 Azure CLI 中提供的使用者介面。
準備您的資料和計算
您必須先準備定型資料並建立 GPU 計算叢集,才能微調基礎模型來改善模型效能。
提示
在 Azure Machine Learning 中建立 GPU 計算叢集時,系統會為您建立經過最佳化的 GPU 虛擬機器。 深入了解 Azure 中可用的 GPU 虛擬機器大小。
定型資料可以是 JSON Line (JSONL)、CSV 或 TSV 格式。 資料需求會根據您想要微調模型的特定工作而有所不同。
| Task | 資料集需求 |
|---|---|
| 文字分類 | 兩個資料行:Sentence (字串) 和 Label (整數/字串) |
| 詞元分類 | 兩個資料行:Token (字串) 和 Tag (字串) |
| 問題解答 | 五個資料行:Question (字串)、Context (字串)、Answers(字串)、Answers_start (整數) 和 Answers_text (字串) |
| 摘要 | 兩個資料行:Document (字串) 和 Summary (字串) |
| 翻譯 | 兩個資料行:Source_language (字串) 和 Target_language (字串) |
注意
您的資料集必須具備必要的需求。 不過,您仍可使用不同的資料行名稱,將資料行對應至適當的需求。
準備好資料集和計算叢集後,就可以在 Azure Machine Learning 中設定微調作業。
選擇基礎模型
瀏覽至 Azure Machine Learning 工作室中的模型目錄時,您可以探索所有的基礎模型。
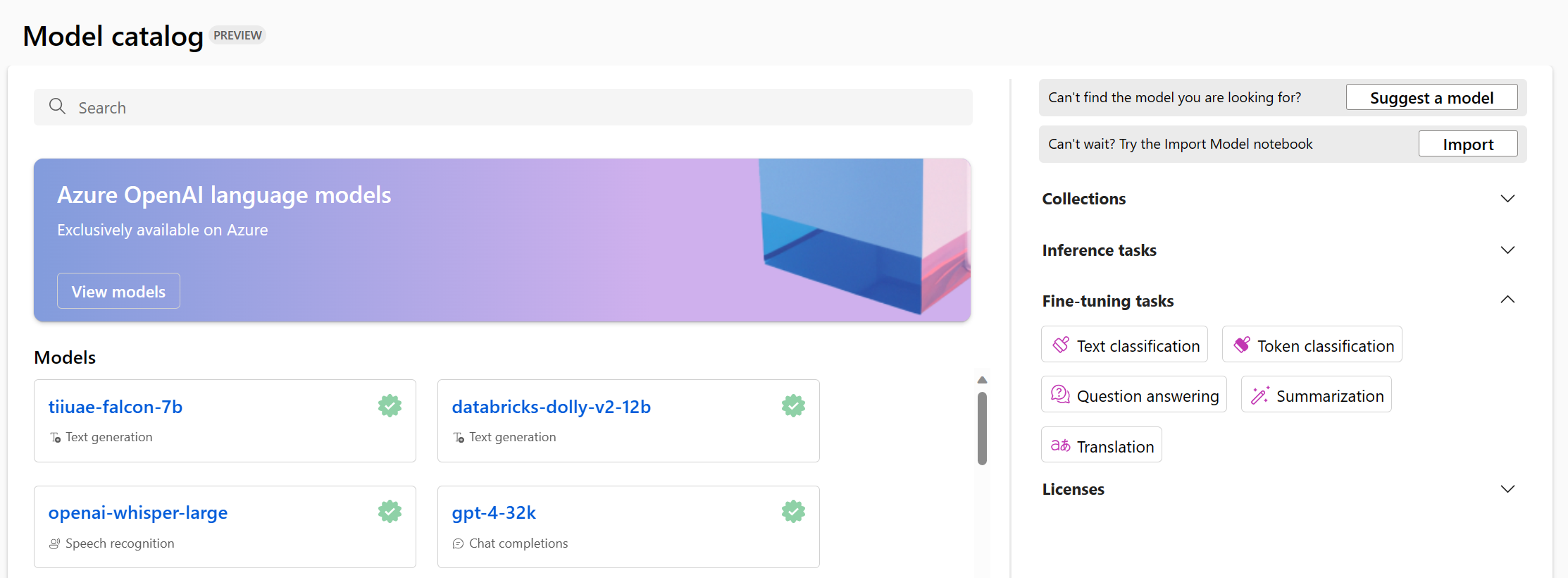
您可以根據想要微調模型的工作篩選可用的模型。 每個工作都有數個選項可供基礎模型選擇。 決定工作的基礎模型時,您可以檢查模型的描述以及參考的模型卡片。
決定為基礎模型進行微調之前,您不妨考量以下事項:
- 模型功能:評估基礎模型的功能及其與您工作的配合程度。 例如,BERT 之類的模型適合用來了解簡短文字。
- 預先定型資料:請考慮用於預先定型基礎模型的資料集。 例如,GPT-2 會根據網際網路上未經篩選而容易造成偏差的內容進行定型。
- 限制和偏差:請注意基礎模型中可能存在的任何限制或偏差。
- 語言支援:探索哪些模型提供特定語言支援或多語系功能,可滿足您的使用案例所需。
提示
雖然 Azure Machine Learning 工作室提供模型目錄中每個基礎模型的描述,您仍可透過個別模型卡片進一步找到每個模型的詳細資訊。 模型卡片可在各模型概觀中參考,並裝載於 Hugging Face 網站
設定微調作業
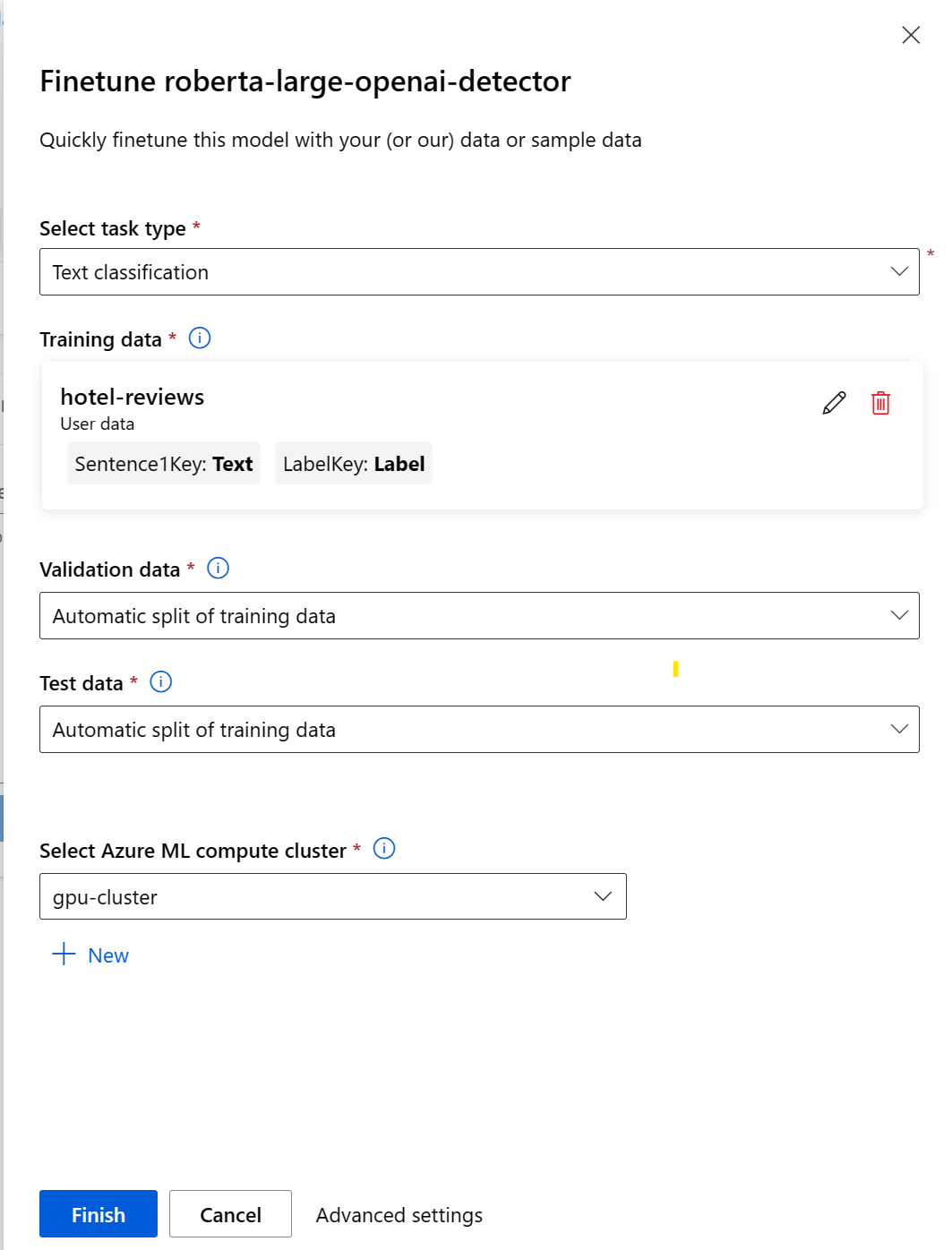
若要使用 Azure Machine Learning 工作室設定微調作業,請執行下列步驟:
- 選擇基礎模型。
- 選取 [微調] 開啟可協助您設定作業的快顯視窗。
- 選取工作型別。
- 選取定型資料,將定型資料中的資料行對應至資料集需求。
- 讓 Azure Machine Learning 自動分割定型資料來建立驗證和測試資料集,或提供您自己的資料集。
- 選取 Azure Machine Learning 管理的 GPU 計算叢集。
- 選取 [完成] 提交微調作業。
提示
或者,您也可以探索進階設定,變更微調作業的名稱和工作參數 (例如學習率) 之類的設定。
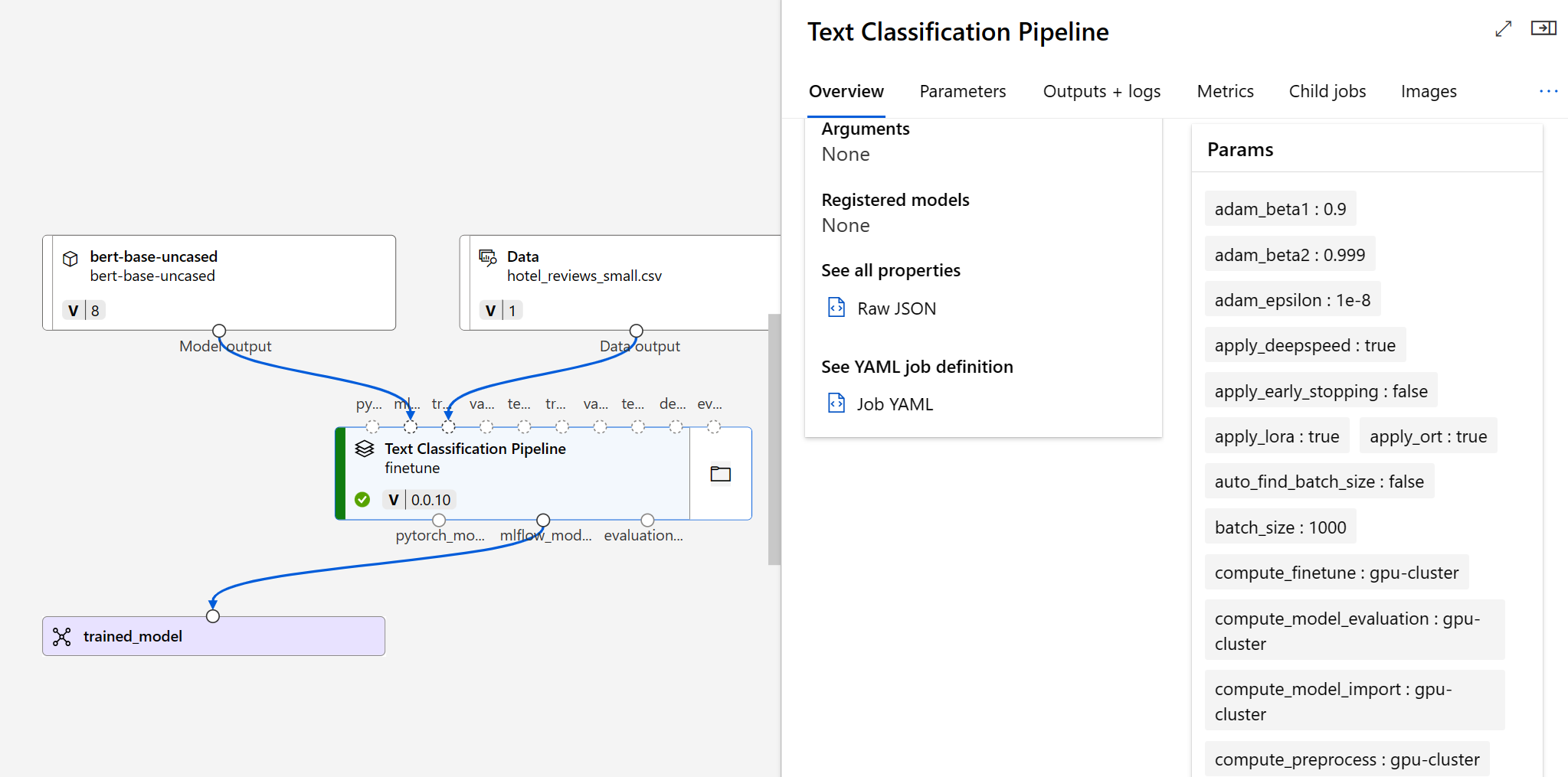
提交微調作業之後,系統會建立管線作業來定型模型。 您可以檢閱所有輸入,並從作業輸出收集模型。