設計索引
SQL Server 有數個索引類型可支援不同類型的工作負載。 概括而言,您可以將索引視為與資料表或檢視相關聯的磁碟結構,讓 SQL Server 相較於掃描整個資料表,更容易找到與索引鍵 (由資料表或檢視中的一或多個資料行組成) 相關聯的資料列。
叢集索引
常見的 DBA 作業面試問題是,要求叢集和非叢集索引之間差異的候選項目,因為索引是 SQL Server 中的基本資料儲存技術。 叢集索引是基礎資料表,依據索引鍵值以排序順序儲存。 在指定資料表上只能有一個叢集索引,因為資料列以單一順序儲存。 沒有叢集索引的資料表稱為堆積,堆積通常只會用來作為暫存表格。 重要的效能設計原則是讓叢集索引鍵盡可能縮小。 當您針對叢集索引考量索引鍵資料行時,您應該考量唯一的資料行或包含許多相異值的資料行。 良好叢集索引鍵的另一個屬性適用於依序存取的記錄,而且經常用來排序從資料表取出的資料。 在用來排序的資料行上擁有叢集索引,可以避免每次執行查詢時要排序的成本,因為資料會以所需的順序儲存。
注意
當我們假設資料表是依特定順序「儲存」時,我們指的是邏輯順序,而不一定是實體的磁碟上順序。 索引在頁面之間有指標,而指標可協助建立邏輯順序。 「依順序」掃描索引時,SQL Server 會遵循頁面至頁面的指標。 緊接在建立索引之後,最可能也會以實體順序儲存在磁碟上,但是在您開始修改資料之後,若要將新的頁面新增至索引,指標仍會為我們提供正確的邏輯順序,但是新的頁面非常可能不是實體磁碟順序。
[非叢集索引]
非叢集索引是與資料列不同的結構。 非叢集索引包含針對索引定義的索引鍵值,而每個索引鍵值項目都有一個指標,指向包含索引鍵值的資料列。 您可以在非叢集索引的分葉層級中新增其他的非索引鍵資料行,以利用 SQL Server 中包含的資料行功能來涵蓋更多資料行。 您可以在資料表上建立多個非叢集索引。
當您需要將索引或資料行新增至現有非叢集索引時的範例顯示如下:

查詢計劃會指出針對使用索引搜尋所取出的每個資料列,必須從叢集索引 (資料表本身) 中擷取更多的資料。 有非叢集索引,但是只包含 product 資料行。 如果您將查詢中的其他資料行新增至非叢集索引 (如下所示),您可以看到執行計畫變更,以消除索引鍵查閱。

上面建立的索引是涵蓋索引的範例,其中除了索引鍵資料行之外,您還包括其他資料行來涵蓋查詢,以及消除存取資料表本身的需要。
非叢集和叢集索引都可以定義為唯一的,這表示不會有重複的索引鍵值。 當您在資料表上建立 PRIMARY KEY 或 UNIQUE 條件約束時,會自動建立唯一索引。
本節的重點在於 SQL Server 中的 B 型樹狀結構索引,這些索引也稱為資料列存放區索引。 B 型樹狀結構的一般結構如下所示:
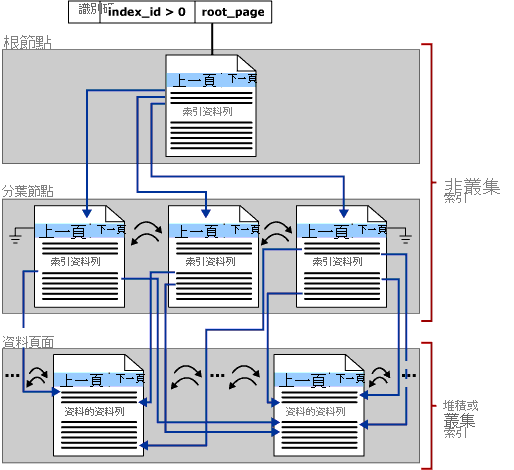
索引 B 型樹狀結構中的每個頁面都稱為索引節點,B 型樹狀結構的最上層節點稱為根節點。 索引中的底部節點稱為分葉節點,而分葉節點的集合則是分葉層級。
索引設計是藝術和科學的結合。 在索引鍵中具有少量資料行的縮小索引需要的更新時間較少,而且維護額外負荷較低;但是,對於與更廣泛索引 (包含更多資料行) 一樣多的查詢,可能不是很有用。 您可能需要根據您的應用程式查詢所選取的資料行,進行數個編製索引方法的實驗。 查詢最佳化工具通常會選擇其認為是最適合查詢的現有索引;但是,這並不表示沒有更好的索引可建立。
適當地為資料庫編製索引是一項複雜的工作。 規劃資料表的索引時,您應該牢記一些基本準則:
- 了解系統的工作負載。 主要用於插入作業的資料表,比起用於 90% 讀取活動的資料倉儲作業的資料表,可以從額外索引獲得的效益少很多。
- 了解最常執行的查詢,並針對這些查詢將索引最佳化。
- 了解您的查詢中所使用資料行的資料類型。 索引適用於整數資料類型,或唯一或非 Null 資料行。
- 在頻繁用於述詞和聯結子句的資料行上建立非叢集索引,並且儘可能縮小這些索引,以避免額外負荷。
- 了解您的資料大小/磁碟區 - 小型資料表上的資料表掃描會是相對便宜的作業,而且 SQL Server 可能會僅僅因為很簡單而決定執行資料表掃描。 在大型資料表上進行資料表掃描,成本可能十分昂貴。
SQL Server 提供的另一個選項是建立篩選索引。 篩選索引最適合大型資料表中的資料行,其中有大量百分比的資料列在該資料行中具有相同的值。 實際範例是如下所示的員工資料表,其中儲存了所有員工的記錄,包括已離開或淘汰的員工。
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
在此資料表中,有一個稱為 CurrentFlag 的資料行,指出員工目前是否為僱用中。 這個範例會使用位元資料類型,僅指出兩個值,1 代表目前僱用中,0 代表並非目前僱用中。 在 CurrentFlag 資料行上具有 WHERE CurrentFlag = 1 的篩選索引,可讓您有效率地查詢目前的員工。
您也可以在檢視上建立索引,當檢視包含彙總和/或資料表聯結等查詢元素時,可提供顯著的效能提升。
資料行存放區索引
資料行存放區為執行大型彙總工作負載的查詢提供改善的效能。 這種類型的索引原本是以資料倉儲為目標,但是經過一段時間資料行存放區索引已用於許多其他工作負載,以協助解決大型資料表上的查詢效能問題。 從 SQL Server 2014 開始,有非叢集和叢集資料行存放區索引。 如同 B 型樹狀結構索引,叢集資料行存放區索引是以特殊方式儲存的資料表本身,而非叢集資料行存放區索引是獨立儲存的資料表。 叢集資料行存放區索引原本就包含指定資料表中的所有資料行。 但是,與資料列存放區叢集索引不同的是,叢集資料行存放區索引「不會」排序。
非叢集資料行存放區索引通常用於兩個案例中,第一個是當資料表中的資料行具有資料行存放區索引不支援的資料類型時。 支援大部分的資料類型,但是在資料行存放區索引中不支援 XML、CLR、sql_variant、ntext、text 和 image。 因為叢集資料行存放區一律包含資料表的所有資料行 (因為「是」資料表),所以非叢集是唯一的選項。 第二個案例是篩選索引,此案例用於稱為混合式交易分析處理 (HTAP) 的架構,其中資料會載入基礎資料表中,同時在資料表上執行報告。 藉由篩選索引 (通常會在日期欄位上進行),這項設計可讓您獲得良好的插入和報告效能。
資料行存放區索引在其儲存機制中是唯一的,因為索引中的每個資料行都是分開儲存。 它提供了一體兩面的優點。 使用資料行存放區索引的查詢只需要掃描符合查詢所需的資料行,減少執行的 IO 總計,並且允許較大的壓縮,因為相同資料行中的資料在本質上可能很類似。
資料行存放區索引最適合用於掃描大量資料的分析查詢,例如資料倉儲中的事實資料表。 從 SQL Server 2016 開始,您可以使用其他的 B 型樹狀結構非叢集索引來增強資料行存放區索引,這在某些查詢對單一值進行查閱時很有幫助。
資料行存放區索引也可以從批次執行模式中獲益,也就是一次處理一組資料列 (通常大約是 900 個),而不是資料庫引擎一次處理這些資料列。 查詢引擎會針對該 900 個記錄的群組進行計算,而不是個別載入每個記錄並加以處理。 此處理模型可大幅減少 CPU 指示的數目。
SELECT SUM(Sales) FROM SalesAmount;
相較傳統資料列處理,批次模式可大幅提升效能。 SQL Server 2019 也包含資料列存放區資料的批次模式。 雖然資料列存放區的批次模式沒有與資料行存放區索引相同層級的讀取效能,但是分析查詢最多可能會上看 5x 倍的效能改進。
資料行存放區索引提供給資料倉儲工作負載的其他優點,是針對 102400 個或更多資料列進行大量插入作業的最佳化載入路徑。 雖然 102400 是直接載入資料行存放區的最小值,但是每個資料列集合 (稱為資料列群組) 最多可以有大約 1024000 個資料列。 擁有較少但是更完整的資料列群組可讓您的 SELECT 查詢更有效率,因為需要掃描較少的資料列群組,就可以取出要求的記錄。 這些載入會在記憶體中發生,並直接載入至索引。 針對較小的磁碟區,資料會寫入至稱為差異存放區的 B 型樹狀結構,並以非同步方式載入至索引。
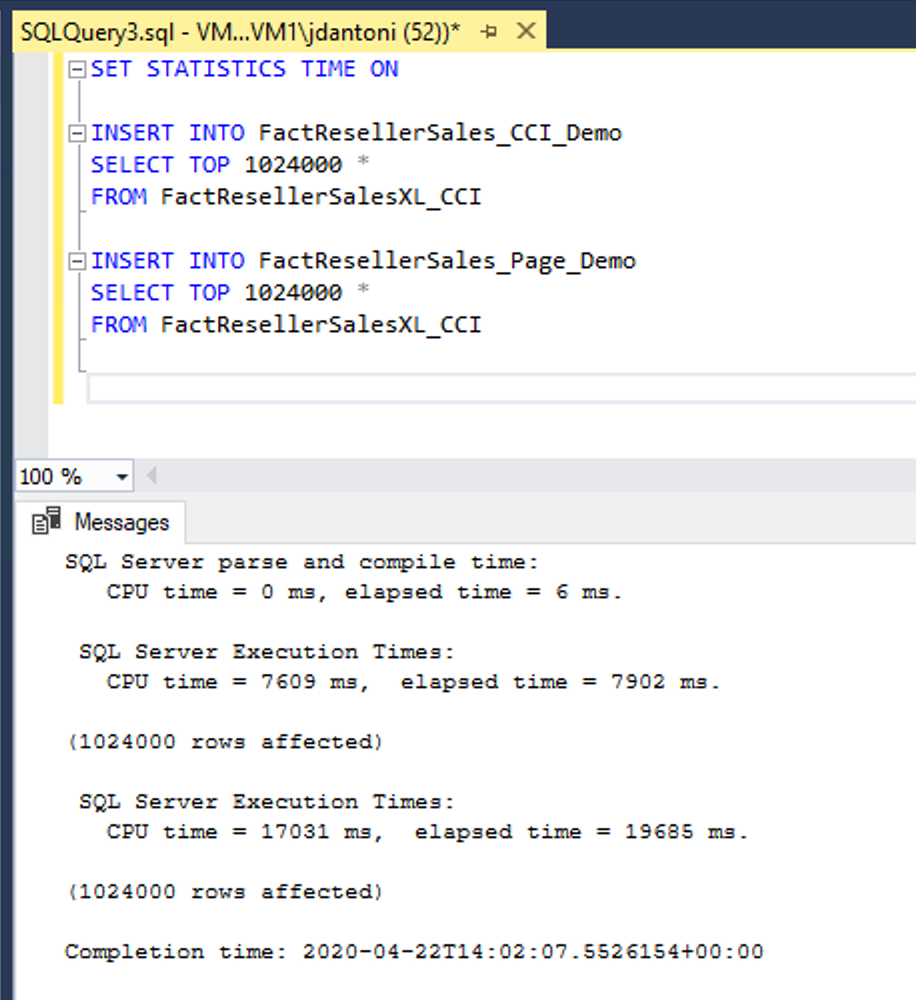
在此範例中,相同的資料會載入兩個資料表中,FactResellerSales_CCI_Demo 和 FactResellerSales_Page_Demo。 FactResellerSales_CCI_Demo 具有叢集資料行存放區索引,而 FactResellerSales_Page_Demo 具有叢集 B 型樹狀結構索引,其中有兩個資料行且頁面進行壓縮。 您可以看到每個資料表都會從 FactResellerSalesXL_CCI 資料表載入 1,024,000 個資料列。 當 SET STATISTICS TIME 為 ON 時,SQL Server 會追蹤查詢執行的已耗用時間。 將資料載入資料行存放區資料表大約需要 8 秒,載入頁面壓縮資料表大約需要 20 秒。 在此範例中,進入資料行存放區索引的所有資料列都會載入到單一資料列群組中。
如果您在單一作業中將少於 102,400 個資料列載入資料行存放區索引,則會載入 B 型樹狀結構 (稱為差異存放區)。 資料庫引擎會使用稱為 Tuple Mover 的非同步程序,將此資料移至資料行存放區索引。 擁有開放差異存放區可能會影響查詢的效能,因為讀取這些記錄比從資料行存放區讀取更沒有效率。 您也可以使用 COMPRESS_ALL_ROW_GROUPS 選項來重新組織索引,以強制將差異存放區新增並壓縮至資料行存放區索引。