使用 NumPy 和 Pandas 探索資料
資料科學家可以使用各種工具和技術來探索、視覺化及操作資料。 資料科學家處理資料的最常見方式之一,就是使用 Python 語言和一些特定的套件來處理資料。
什麼是 NumPy?
NumPy 是一種 Python 程式庫,可提供相當於數學工具 (例如 MATLAB 和 R) 的功能。雖然 NumPy 可大幅簡化使用者體驗,但它也提供完整的數學函數。
什麼是 Pandas?
Pandas 是非常熱門的 Python 程式庫,可進行資料分析和操作。 Pandas 就像是適用於 Python 的試算表應用程式 - 提供容易使用的資料表功能。
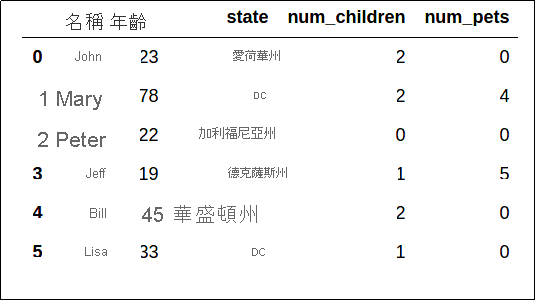
探索 Jupyter 筆記本中的資料
Jupyter 筆記本是使用您的網頁瀏覽器執行基本指令碼的熱門方式。 一般而言,這些筆記本是單一網頁,分為在伺服器上執行的文字區段和程式碼區段,而不是在您的本機電腦上執行。 藉由在伺服器上的 Jupyter 筆記本中執行程式碼,即可快速開始使用,而不需要在本機電腦上安裝 Python 或其他工具。
測試假設
資料探索和分析通常是疊代流程,其中的資料科學家會取得資料的範例,並執行下列類型的工作來分析和測試假設:
- 清除資料以處理錯誤、遺漏值和其他問題。
- 套用統計技術進一步了解資料,並瞭解樣本如何可能如預期中代表實際的資料母體,且將隨機變化納入考量。
- 將資料視覺化,以判斷變數之間的關聯性,並且在機器學習專案的情況下,識別可能為標籤預測的功能。
- 修訂假設,然後重複此流程。