評估您生成式 AI 應用程式的效能
當您想要建立生成式 AI 應用程式時,您可使用提示流程來開發聊天應用程式。 您可以在執行流程之後評估回應,以評估應用程式的效能。
使用個別提示測試流程
在作用中開發期間,您可以在計算工作階段執行時,使用聊天功能來測試您正在建立的聊天流程:

當您在聊天視窗中使用個別提示來測試流程時,您的流程會使用提供的輸入來執行。 成功執行之後,聊天視窗中會顯示回應。 您也可以探索流程的每個個別節點的輸出,以了解最終回應的建構方式:

使用評估流程自動測試流程
若要大量評估聊天流程,您可以執行自動化評估。 您可以使用內建的自動化評估,也可以藉由建立自己的評估流程來定義自訂評估。
使用 Microsoft 策劃的計量評估
內建或 Microsoft 策劃的計量包括下列計量:
效能和品質:
- 連貫性:測量生成式 AI 應用程式如何可以產生順暢地流動、讀起來自然並類似人類語言的輸出。
- 流暢度:測量生成式 AI 應用程式預測答案的語言熟練度。
- GPT 相似性:測量來源資料 (基礎真相) 句子與 AI 應用程式產生的回應之間的相似性。
- F1 分數:測量生成式 AI 應用程式預測與來源資料 (基礎真相) 之間字數的比例。
- 基礎性:測量生成式 AI 應用程式的答案與輸入來源資訊的如何對應。
- 相關性:測量生成式 AI 應用程式所產生回應的範圍,與給定的問題貼近且直接相關。
風險和安全:
- 自我傷害相關的內容:測量產生自我傷害相關內容的生成式 AI 應用程式的傾向。
- 仇恨和不公平的內容:測量產生仇恨和不公平內容的生成式 AI 應用程式的傾向。
- 暴力內容:測量產生暴力內容的生成式 AI 應用程式的傾向。
- 色情內容:測量產生色情內容的生成式 AI 應用程式的傾向。

若要使用內建的自動化評估來評估聊天流程,您必須:
- 建立測試資料集。
- 在 Azure AI Foundry 入口網站中建立新的自動化評估。
- 選取具有模型產生輸出的流程或資料集。
- 選取您要評估的計量。
- 執行評估流程。
- 檢閱結果。

提示
深入了解評估和監視計量
建立自訂評估計量
或者,您可以建立自己的自訂評估流程,在其中您會定義聊天流程輸出的評估方式。 例如,您可以使用 Python 程式碼或使用大型語言模型 (LLM) 節點來評估輸出,以建立 AI 輔助的計量。 讓我們使用簡單的範例來探索評估流程如何運作。
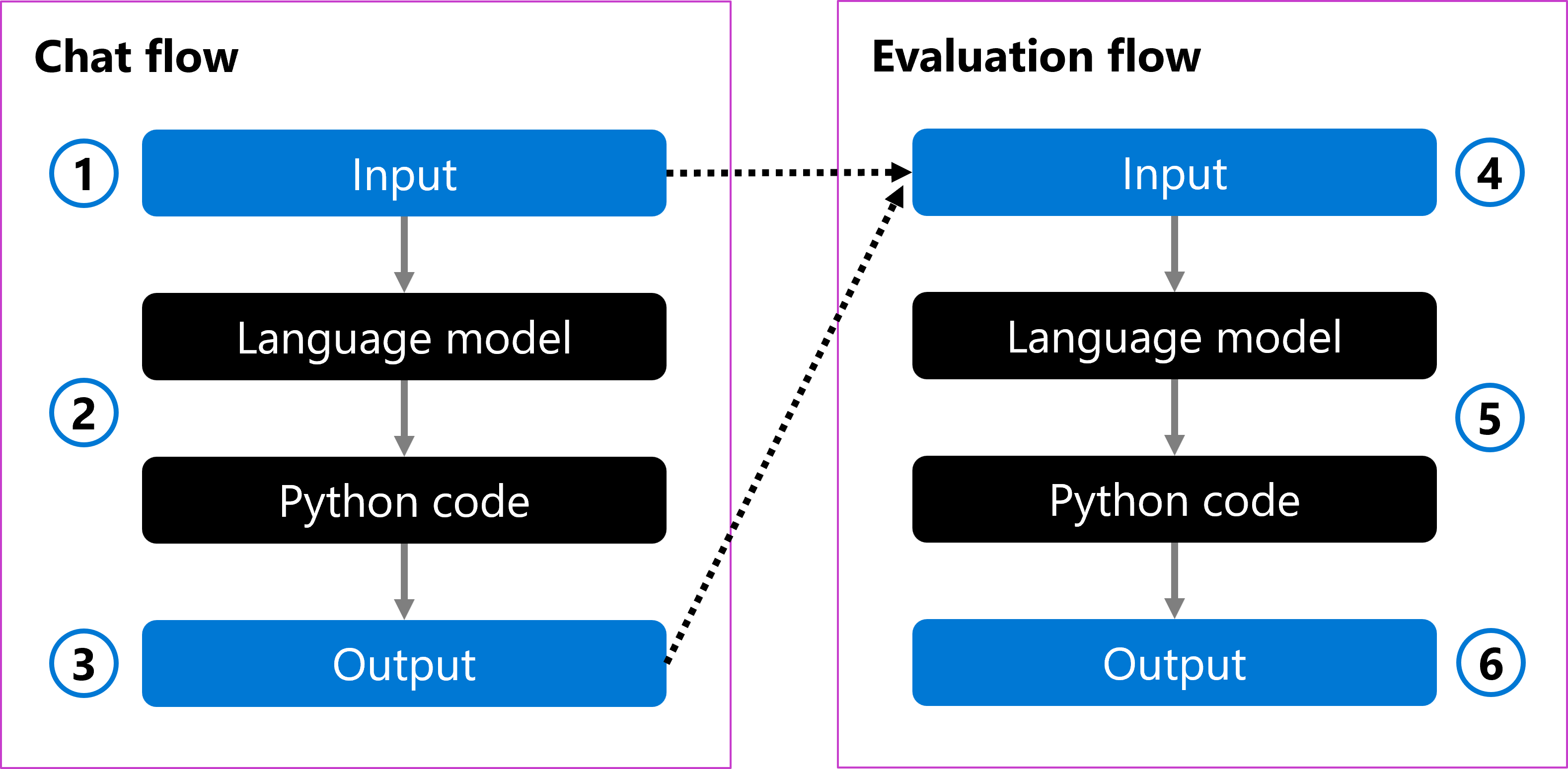
您可以有一個聊天流程,以使用者的問題作為輸入 (1)。 流程會使用語言模型處理輸入,並使用 Python 程式碼將答案格式化 (2)。 最後,它會以輸出的形式傳回回應 (3)。
若要評估聊天流程,您可以建立評估流程。 評估流程會採用原始使用者問題和產生的輸出作為輸入 (4)。 流程會使用語言模型來評估它,並使用 Python 程式碼來定義評估計量 (5),然後傳回為輸出 (6)。
建立評估流程時,您可以選擇如何評估聊天流程。 您可以使用語言模型來建立自己的自訂 AI 輔助計量。 在提示中,您可以定義您想要測量的計量,以及語言模型應使用的評分級別。 例如,評估提示可以是:
# Instructions
You are provided with the input and response of a language model that you need to evaluate on user satisfaction.
User satisfaction is defined as whether the response meets the user’s question and needs, and provides a comprehensive and appropriate answer to the question.
Assign each response a score of 1 to 5 for user satisfaction, with 5 being the highest score.
建立評估流程之後,您可以藉由提供測試資料集並執行評估流程來評估聊天流程。

在評估流程中使用語言模型時,可以在輸出追蹤中檢閱結果:

此外,您可以在評估流程中新增 Python 節點,以彙總測試資料集中所有提示的結果,並傳回整體計量。
提示