了解湖資料庫的概念
在傳統的關聯式資料庫中,資料庫結構是由資料表、檢視和其他物件所組成。 關聯式資料庫中的資料表會定義儲存資料的實體,例如零售資料庫可能包含產品、客戶和訂單的資料表。 每個實體都包含一組屬性,在資料表中定義為行,而且每一行中都有名稱和資料類型。 資料表的資料會儲存在資料庫中,並且與資料表定義緊密結合;即會在相關索引鍵之間強制執行資料類型、Null 屬性、索引鍵唯一性和參考完整性。 所有查詢和資料操作都必須透過資料庫系統執行。
資料湖中沒有固定結構。 資料會儲存在檔案中,這些資料可能是結構化、半結構化或非結構化。 應用程式和資料分析師可以使用他們選擇的工具直接使用資料湖中的檔案,無須使用關聯式資料庫系統的限制式。
湖資料庫會在資料湖中的一或多個檔案上提供關聯式中繼資料圖層。 您可以建立湖資料庫,其中包含資料表的定義,包括行名稱和資料類型,以及主要索引鍵和外部索引鍵行之間的關聯。 資料湖中的資料表參考檔案,可讓您套用關聯式語意來使用資料,並使用 SQL 進行查詢。 不過,資料檔案的儲存空間會與資料庫結構分離,因此通常可提供比關聯式資料庫系統更多的彈性。
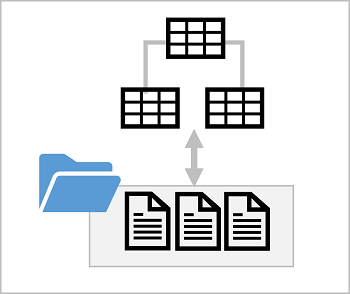
湖資料庫結構
您可以在 Azure Synapse Analytics 中建立湖資料庫,並定義資料表,代表此為您需要儲存資料的實體。 您可以套用經過實證的資料模模組化原則來建立資料表之間的關聯,並為資料表、行與其他資料庫物件使用合適的命名轉換。
Azure Synapse Analytics 包含圖形資料庫設計介面,您可以使用此圖形資料庫設計介面來建立複雜資料庫結構的模型,使用其中許多可用於傳統資料庫的資料庫設計最佳做法。
湖資料庫儲存空間
湖資料庫中資料表的資料會以 Parquet 或 CSV 檔案的形式儲存在資料湖中。 您可以獨立管理資料庫資料表中的檔案,讓您更輕鬆地使用各種資料處理工具和技術以管理資料擷取和操作。
湖資料庫計算
若要透過您定義的資料表查詢與操作資料,您可以使用 Azure Synapse Analytics 無伺服器 SQL 集區來執行 SQL 查詢或 Azure Synapse Apache Spark 集區,以使用 Spark SQL API 來處理資料表。