自訂文字分類技能
自訂文字分類可讓您將一段文字對應至不同的使用者定義類別。 例如可以訓練一個針對書籍封底的模型,用於自動判別書籍的內容類型。 接著使用判別出的內容類型,以內容類型 Facet 來擴充您的線上商店搜尋引擎。
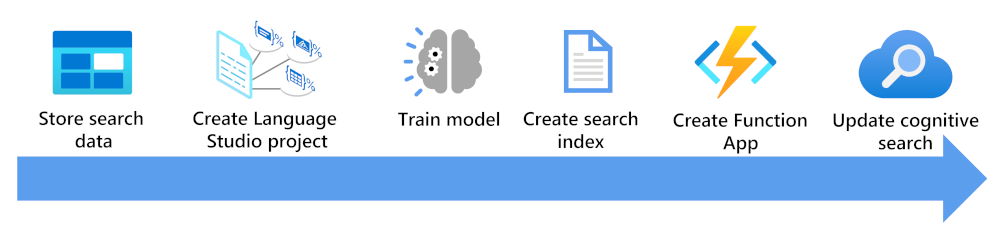
這邊可看到在使用自訂文字分類模型來擴充搜尋索引時,所需考量的因素:
- 請儲存您的文件,如此才能供 Language Studio 和 Azure AI 搜尋服務索引子存取。
- 建立自訂文字分類專案。
- 定型和測試模型。
- 根據所儲存的文件來建立搜尋索引。
- 建立函數應用程式,以使用部署好的已訓練模型。
- 更新您的搜尋解決方案、索引、索引子和自訂技能。
儲存您的資料
您可以從 Language Studio 和 Azure AI 服務存取 Azure Blob 儲存體。 容器必須可供存取,因此最簡單的選項是選擇 [容器],但也可以使用私人容器搭配一些額外的設定。
除了您的資料之外,還需要指派每份文件分類的方式。 Language Studio 提供圖形化工具,可供一次手動分類一份文件。
您可以選擇兩種不同類型的專案。 如果文件對應至單一類別,請使用單一標籤分類專案。 如果您想要將文件對應至多個類別,請使用多標籤的分類專案。
如果不想手動分類每份文件,可以在建立 Azure AI 語言專案之前先標記所有文件。 此程序牽涉到以下列格式建立標籤 JSON 文件:
{
"projectFileVersion": "2022-05-01",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectKind": "CustomMultiLabelClassification",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectName": "{PROJECT-NAME}",
"multilingual": false,
"description": "Project-description",
"language": "en-us"
},
"assets": {
"projectKind": "CustomMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
}
]
}
您可以在 classes 陣列中新增無數量限制的類別。 您可以為 documents 陣列中的每份文件新增項目,包含與文件相符的類別。
建立您的 Azure AI 語言專案
有兩種方式可以建立您的 Azure AI 語言專案。 如果您開始使用 Language Studio 時並未先在 Azure 入口網站中建立語言服務,則 Language Studio 可為您建立語言服務。
建立 Azure AI 語言專案的最彈性方式,是先使用 Azure 入口網站來建立您的語言服務。 如果選擇此選項,則會獲得新增自訂功能的選項。
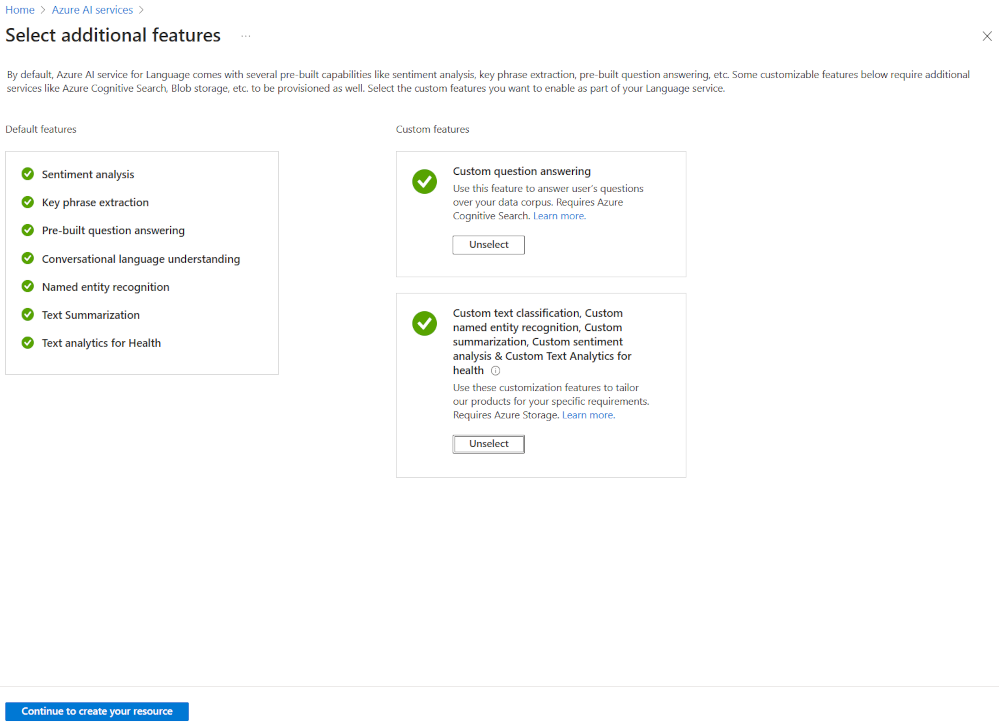
建立自訂文字分類前,請在建立語言服務時,選取該自訂功能。 您也會透過此方法將語言服務連結到儲存體帳戶。
部署資源之後,可從語言服務的概觀窗格直接導覽至 Language Studio。 然後就可以建立新的自訂文字分類專案。
注意
如果您已從 Language Studio 建立語言服務,您可能需要遵循下列步驟。 設定 Azure 語言資源和儲存體帳戶的角色,將您的儲存體容器連線到自訂文字分類專案。
訓練分類模型
如同所有 AI 模型,您必須有可用來訓練模型的已識別資料。 模型需要透過範例來理解如何將資料對應至類別,也需要一些用於測試模型的範例。 您可以選擇讓模型自動分割您的訓練資料,預設會使用 80% 的文件來訓練模型,其餘 20% 則用於模型的盲目測試。 如果想將一些特定文件用於測試模型,可以先標記要測試的文件。

請在 Language Studio 中,於您的專案選取 [資料標記]。 您會看到您的所有文件。 選取您想要新增至測試集的每份文件,然後選取 [測試模型效能]。儲存更新後的標籤,再建立新的訓練作業。
建立搜尋索引
您不需要執行任何特定動作,就能建立將由自訂文字分類模型擴充的搜尋索引。 請遵循建立 Azure AI 搜尋服務解決方案中的步驟。 建立函數應用程式之後,需要更新索引、索引子和自訂技能。
建立 Azure 函數應用程式
您可以選擇函數應用程式要使用的語言和技術。 應用程式必須能夠將 JSON 傳遞至自訂文字分類端點,例如:
{
"displayName": "Extracting custom text classification",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en-us",
"text": "This film takes place during the events of Get Smart. Bruce and Lloyd have been testing out an invisibility cloak, but during a party, Maraguayan agent Isabelle steals it for El Presidente. Now, Bruce and Lloyd must find the cloak on their own because the only non-compromised agents, Agent 99 and Agent 86 are in Russia"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"project-name": "movie-classifier",
"deployment-name": "test-release"}
}
]
}
然後處理模型的 JSON 回應,例如:
{
"jobId": "be1419f3-61f8-481d-8235-36b7a9335bb7",
"lastUpdatedDateTime": "2022-06-13T16:24:27Z",
"createdDateTime": "2022-06-13T16:24:26Z",
"expirationDateTime": "2022-06-14T16:24:26Z",
"status": "succeeded",
"errors": [],
"displayName": "Extracting custom text classification",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomMultiLabelClassificationLROResults",
"taskName": "Multi Label Classification",
"lastUpdateDateTime": "2022-06-13T16:24:27.7912131Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "1",
"class": [
{
"category": "Action",
"confidenceScore": 0.99
},
{
"category": "Comedy",
"confidenceScore": 0.96
}
],
"warnings": []
}
],
"errors": [],
"projectName": "movie-classifier",
"deploymentName": "test-release"
}
}
]
}
}
函式接著會將結構化 JSON 訊息傳回 AI 搜尋服務中的自訂技能集,例如:
[{"category": "Action", "confidenceScore": 0.99}, {"category": "Comedy", "confidenceScore": 0.96}]
函數應用程式必須知道下列五項資訊:
- 要分類的文字。
- 已訓練自訂文字分類部署模型的端點。
- 自訂文字分類專案的主索引鍵。
- 專案名稱。
- 部署名稱。
要分類的文字是以輸入的形式,從 AI 搜尋服務中的自訂技能集傳遞至函式。 其餘四個項目可在 Language Studio 中找到。

端點和部署名稱都位於部署模型窗格上。

專案名稱和主索引鍵都位於專案設定窗格中。
更新您的 Azure AI 搜尋服務解決方案
您必須在 Azure 入口網站進行三項變更,才能擴充搜尋索引:
- 必須將欄位新增至索引,以儲存自訂文字分類擴充。
- 必須新增自訂技能集,以使用要分類的文字呼叫函數應用程式。
- 必須將技能集的回應對應至索引。
將欄位新增至現有的索引
在 Azure 入口網站中,請前往您的 AI 搜尋服務資源,選取索引,並以下列格式新增 JSON:
{
"name": "classifiedtext",
"type": "Collection(Edm.ComplexType)",
"analyzer": null,
"synonymMaps": [],
"fields": [
{
"name": "category",
"type": "Edm.String",
"facetable": true,
"filterable": true,
"key": false,
"retrievable": true,
"searchable": true,
"sortable": false,
"analyzer": "standard.lucene",
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
},
{
"name": "confidenceScore",
"type": "Edm.Double",
"facetable": true,
"filterable": true,
"retrievable": true,
"sortable": false,
"analyzer": null,
"indexAnalyzer": null,
"searchAnalyzer": null,
"synonymMaps": [],
"fields": []
}
]
}
此 JSON 會將複合欄位新增至索引,以將類別儲存在可搜尋的 category 欄位中。 第二個 confidenceScore 欄位會將信賴度百分比儲存在雙精確度欄位中。
編輯自訂技能集
在 Azure 入口網站中,選取技能集,並以下列格式新增 JSON:
{
"@odata.type": "#Microsoft.Skills.Custom.WebApiSkill",
"name": "Genre Classification",
"description": "Identify the genre of your movie from its summary",
"context": "/document",
"uri": "https://learn-acs-lang-serives.cognitiveservices.azure.com/language/analyze-text/jobs?api-version=2022-05-01",
"httpMethod": "POST",
"timeout": "PT30S",
"batchSize": 1,
"degreeOfParallelism": 1,
"inputs": [
{
"name": "lang",
"source": "/document/language"
},
{
"name": "text",
"source": "/document/content"
}
],
"outputs": [
{
"name": "text",
"targetName": "class"
}
],
"httpHeaders": {}
}
此 WebApiSill 技能定義會指定將文件的語言和內容作為輸入,傳遞至函數應用程式。 應用程式會傳回名稱為 class 的 JSON 文字。
將函數應用程式的輸出對應至索引
最後一個變更是將輸出對應至索引。 在 Azure 入口網站中,選取索引子並編輯 JSON,以擁有新的輸出對應:
{
"sourceFieldName": "/document/class",
"targetFieldName": "classifiedtext"
}
索引子現在知道函數應用程式的 document/class 輸出應該儲存在 classifiedtext 欄位中。 由於這已定義為複合欄位,因此函數應用程式必須傳回包含 category 和 confidenceScore 欄位的 JSON 陣列。
您現在可以搜尋自訂分類文字的擴充搜尋索引。