練習 - 建置和定型神經網路
在本單元中,您將使用 Keras 建置和定型神經網路來分析文字中的情感。 為了定型神經網路,您需要用來定型的資料。 您將使用 Keras 隨附的 IMDB movie reviews sentiment classification (IMDB 電影評論情感分類) 資料集,而不是下載外部資料集。 IMDB 資料集包含 50,000 則電影評論,已個別評分為正面 (1) 或負面 (0)。 此資料集分成用於定型的 25,000 則評論,以及用於測試的 25,000 則評論。 這些評論中所表達情感是您的神經網路用來分析所呈現文字,以及對其中情感進行評分的基礎。
IMDB 資料集是 Keras 隨附的幾個實用資料集之一。 如需完整的內建資料集清單,請參閱 https://keras.io/datasets/.
請將下列程式碼鍵入或貼至筆記本的第一個資料格,然後按一下 [執行] 按鈕 (或按 Shift+Enter) 加以執行,並在其下方新增資料格:
from keras.datasets import imdb top_words = 10000 (x_train, y_train), (x_test, y_test) = imdb.load_data(num_words=top_words)此程式碼會載入 Keras 隨附的 IMDB 資料集,並建立字典來將所有 50,000 則評論中的文字,對應至指出文字相對出現頻率的整數。 每個字組會獲指派唯一的整數。 最常見的字組會獲指派數字 1,第二個最常見的字組會獲指派數字 2,依此類推。
load_data也會傳回一對 Tuple,其中包含電影評論 (在此範例中為x_train和x_test),並以 1 和 0 將這些評論分類為正面和負面 (y_train和y_test)。確認您看到訊息「正在使用 TensorFlow 後端」,這表示 Keras 使用 TensorFlow 作為其後端。
正在載入 IMDB 資料集
若您希望 Keras 使用 Microsoft Cognitive Toolkit (也稱為 CNTK) 作為其後端,可以在筆記本開頭新增幾行程式碼來執行此作業。 如需範例,請參閱 Azure Notebooks 中的 CNTK 和 Keras。
那麼,
load_data函式實際載入的內容為何? 名為x_train的變數是由 25,000 份清單組成的清單,每份清單各代表一則電影評論。 (x_test也是由 25,000 份清單 (代表 25,000 則電影評論) 組成的清單。x_train會用於定型,而x_test會用於測試)。但內部清單 (代表電影評論的清單) 不會包含文字,而會包含整數。 它在 Keras 文件中的描述如下:
內部清單包含數字而非文字的原因在於,您不會使用文字來定型神經網路,而會使用數字將它定型。 具體而言,您會使用張量將其定型。 在此情況下,每則評論都是一維張量 (可想成一維陣列),其中包含識別評論所含字組的整數。 為了示範,請在空白資料格中鍵入下列 Python 陳述式,並執行此陳述式以查看代表定型集中第一則評論的整數:
x_train[0]
「正在組成 IMDB 定型集中第一則評論的整數」
清單中的第一個數字 1 不代表任何文字。 其標示評論的開始,且對於資料集中的所有評論都相同。 數字 0 和 2 也會保留,而您從其他數字減去 3 即可將評論中整數對應至字典中的對應整數。 第二個數字 14 會參考對應至字典中數字 11 的文字,第三個數字會代表字典中指派數字 19 的文字,依此類推。
想了解字典看起來的樣子嗎? 在新的筆記本資料格中執行下列陳述式:
imdb.get_word_index()只會顯示字典項目的子集,但字典總計包含超過 88,000 個字組和對應到這些字組的整數。 您所看到輸出可能不符合螢幕擷取畫面中的輸出,因為每次呼叫
load_data都會重新產生字典。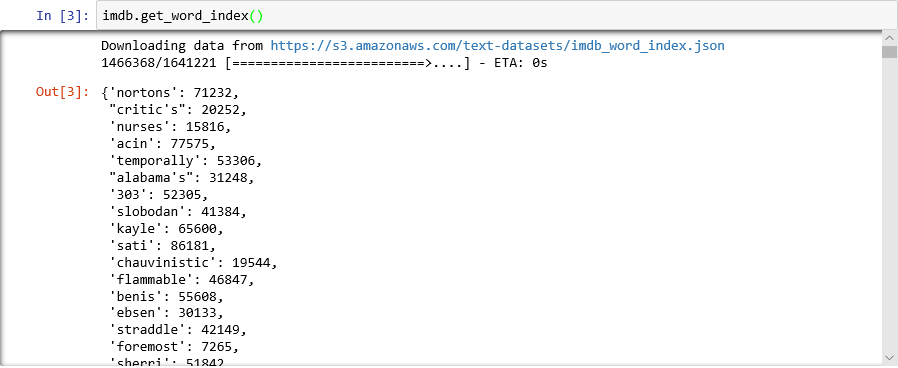
將字組對應至整數的字典
如您所見,資料集中每一篇影評都會編碼成整數集合,而不是文字集合。 是否可以對評論進行反向編碼,以便看到其中包含的原始文字? 在新的資料格中輸入下列陳述式,並執行這些陳述式以文字格式顯示
x_train中的第一則評論:word_dict = imdb.get_word_index() word_dict = { key:(value + 3) for key, value in word_dict.items() } word_dict[''] = 0 # Padding word_dict['>'] = 1 # Start word_dict['?'] = 2 # Unknown word reverse_word_dict = { value:key for key, value in word_dict.items() } print(' '.join(reverse_word_dict[id] for id in x_train[0]))在輸出中,">" 標示評論的開始,而 "?" 標示不在資料集中最常見 10,000 個文字間的文字。 這些「未知」文字在代表評論的整數清單中,是以 2 表示。 還記得您傳遞給
load_data的num_words參數嗎? 此時適合使用該參數。 它不會降低字典的大小,但會限制用來編碼評論的整數範圍。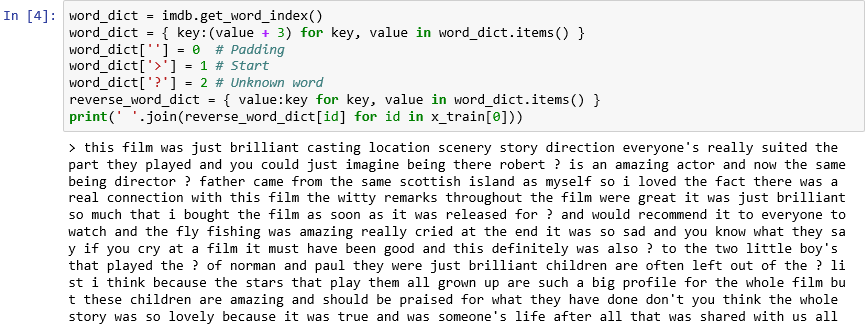
文字格式的第一篇評論
這些評論會經過「清理」,其中字母已轉換成小寫並移除了標點符號字元。 但尚未準備好定型神經網路來分析文字中的情感。 當您使用張量集合來定型神經網路時,每個張量的長度必須相同。 目前,
x_train和x_test中代表評論的清單長度不一。幸好,Keras 包含一個函式,可接受由多份清單組成的清單作為輸入,並視需要截斷或以 0 填補,來將內部清單轉換成指定長度。 在筆記本中輸入下列程式碼,並執行此程式碼以將
x_train和x_test中代表電影評論的所有清單,強制轉換成 500 個整數的長度:from keras.preprocessing import sequence max_review_length = 500 x_train = sequence.pad_sequences(x_train, maxlen=max_review_length) x_test = sequence.pad_sequences(x_test, maxlen=max_review_length)現在已備妥定型和測試資料,您可以開始建置模型! 在筆記本中執行下列程式碼來建立神經網路以執行情感分析:
from keras.models import Sequential from keras.layers import Dense from keras.layers.embeddings import Embedding from keras.layers import Flatten embedding_vector_length = 32 model = Sequential() model.add(Embedding(top_words, embedding_vector_length, input_length=max_review_length)) model.add(Flatten()) model.add(Dense(16, activation='relu')) model.add(Dense(16, activation='relu')) model.add(Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy',optimizer='adam', metrics=['accuracy']) print(model.summary())確認輸出與以下內容相似:
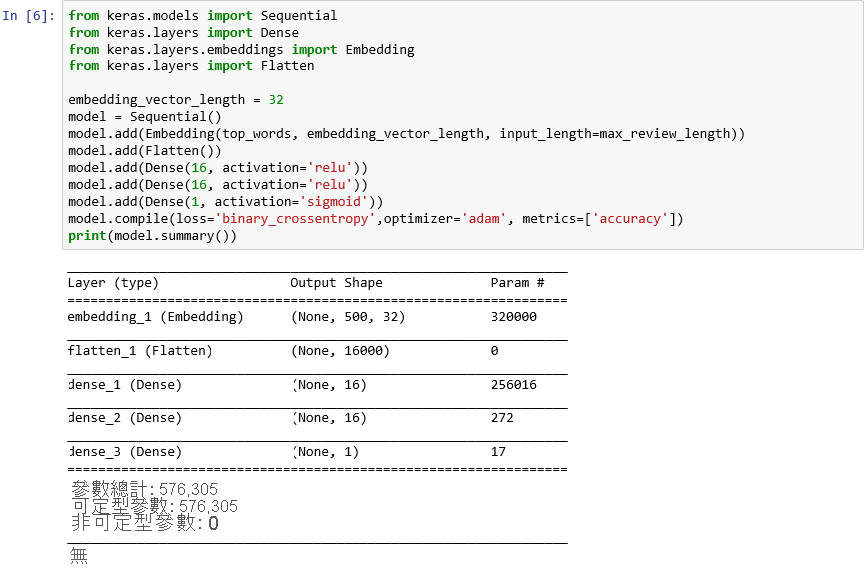
使用 Keras 建立神經網路
此程式碼基本上會示範如何使用 Keras 建構神經網路。 其會先具現化代表「循序」模型的
Sequential物件,該模型包含端對端的階層堆疊,其中某個階層輸出會提供下一個階層的輸入。接下來幾個陳述式會將階層新增至模型。 第一個是內嵌層,這對處理字組的神經網路至關重要。 內嵌層基本上會將包含整數文組索引的多維度陣列,對應至包含較少維度的浮點數陣列。 其也允許將具有類似意義的字組視為相似。 字組內嵌的完整處理方式不在本實驗室範圍內,但您可以閱讀為何需要開始使用內嵌層來深入了解。 如果您偏好較學術的說明,請參閱有效率地評估向量空間中的字組表示法。 在新增內嵌層之後呼叫 Flatten,可為下一個階層的輸入調整輸出。
接下來新增至模型的三個階層是密集層,也稱為「完全連接」層。 這些是神經網路中常見的傳統層。 每一層都包含 n 個節點或神經,而每個神經都會接收上一層中每個神經的輸入,因此稱為「完全連線」。便是這些層透過反復猜測輸出、檢查結果,以及微調連線來產生更好的結果,藉此讓神經網路能從輸入資料「學習」。 此網路中的前兩個密集層各包含 16 個神經元。 此數字是任意選擇的;您可以試驗不同大小來改善模型的精確度。 最後一個密集層只包含一個神經元,因為網路的終極目標是預測一個輸出,也就是 0.0 到 1.0 的情感分數。
結果是下圖所示的神經網路。 此網路包含一個輸入層、一個輸出層,以及兩個隱藏層 (各包含 16 個神經元的密集層)。 相較之下,現今某些更複雜的神經網路會超過 100 層。 由 Microsoft 研究所提供的 ResNet-152 即為一例,其在識別相片中物件方面的精確度有時超過人類。 您可以使用 Keras 建置 ResNet-152,但您需要配備 GPU 的電腦叢集,才能從頭將其定型。
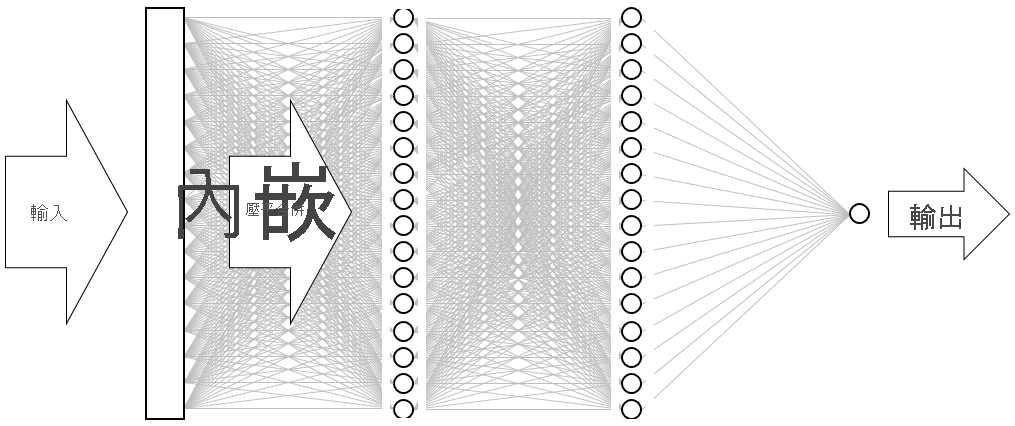
「正在將神經網路視覺化」
呼叫 compile 函式會藉由指定重要參數來「編譯」模型,例如要使用的最佳化工具,以及要在每個定型步驟中用來判斷模型精確度的計量。 定型會等到您呼叫模型的
fit函式才開始,因此compile呼叫的執行速度通常很快。現在呼叫 fit 函式以定型神經網路:
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=5, batch_size=128)定型應該需要約 6 分鐘的時間,或每個 Epoch 比 1 分鐘多一點。
epochs=5指示 Keras 正向和反向通過模型 5 次。 每次通過時,模型都會從訓練資料學習,並評估 (「驗證」) 使用測試資料的學習成效。 然後其會進行調整,並返回下一個行程或 Epoch。 這會反映在fit函式的輸出中,其中顯示每個 Epoch 的定型精確度 (acc) 和驗證精確度 (val_acc)。batch_size=128指示 Keras 一次使用 128 個定型樣本來定型網路。 較大的批次的訓練時間較快 (每個 Epoch 用盡所有訓練資料需要的操作次數較少),但較小的批次有時會提高精確度。 當您完成本實驗室之後,您可能想要返回並使用批次大小 32 來重新定型模型,看看這對模型的精確度有何影響 (如果有的話)。 大約會增加一倍的定型時間。
將模型定型
此模型並不常見,只要幾個 Epoch 就會有很好的學習成效。 定型精確度會快速提高到接近 100%,而驗證精確度會提高一兩個 Epoch 後保持水平。當您定型模型時,您通常不想要花費比這些精確度趨於穩定所需還要久的時間。 風險為過度學習,這會導致模型對測試資料的執行效能理想,但對真實世界資料的執行效能卻不理想。 模型過適的一個指標,就是定型精確度與驗證精確度之間的不一致情況增加。 如需過適的最佳簡介,請參閱 機器學習中的過度學習:其代表意義及預防方式。
若要將定型和驗證精確度中的變更視覺化為定型進度,請在新的筆記本資料格中執行下列陳述式:
import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline sns.set() acc = hist.history['acc'] val = hist.history['val_acc'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, '-', label='Training accuracy') plt.plot(epochs, val, ':', label='Validation accuracy') plt.title('Training and Validation Accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.legend(loc='upper left') plt.plot()精確度資料來自模型中
fit函式所傳回的history物件。 根據您看到的圖表,您建議增加或減少定型 Epoch 的數目,還是保持相同?檢查過適的另一種方式,就是在定型進行時,比較定型損失與驗證損失。 這類最佳化問題會嘗試最小化損失函式。 您可以在這裡取得詳細資訊。 在指定的 Eepoch 內,定型損失若高於驗證損失,則證明過適。 在上一個步驟中,您使用了
history物件中history屬性的acc和val_acc屬性來繪製定型和驗證精確度。 相同屬性也包含名為loss和val_loss的值,分別代表定型損失和驗證損失。 如果您想要繪製這些值來產生類似下面的圖表,您要如何修改上述程式碼來執行這項作業?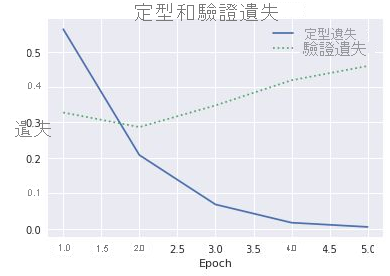
定型及驗證損失
假設定型損失與驗證損失的間距在第三個 Epoch 開始增加,若有人建議您將 Epoch 數目增加為 10 或 20,您會如何回應?
最後呼叫模型的
evaluate方法,根據x_test(評論) 和y_test(表示評論為正面和負面的 0 和 1 或「標籤」) 中的測試資料,判斷模型能夠量化文字中所表達情感的精確度:scores = model.evaluate(x_test, y_test, verbose=0) print("Accuracy: %.2f%%" % (scores[1] * 100))您模型的計算精確度為何?
您可能會達到 85% 到 90% 範圍的精確度。 考慮到您是從頭建置模型 (相對於使用預先定型的神經網路),且定型時間很短,甚至沒有 GPU,這是可接受的精確度。 使用其他神經網路架構「可能」會達到 95% (含) 以上的精確度,特別是利用長短期記憶 (LSTM) 層的 遞歸神經網路 (RNN)。 Keras 可讓您輕鬆地建置這類網路,但定型時間可能會以指數方式增加。 您所建置的模型會在精確度與定型時間之間取得適當平衡。 不過,如果您想要深入了解如何使用 Keras 建置 RNN,請參閱了解 LSTM 及其在 Keras 中針對情感分析的快速實作。