適用於電腦視覺的機器學習
使用篩選將效果套用至影像的能力在影像處理工作中是很有用的,例如,您可以使用影像編輯軟體來執行。 不過,電腦視覺的目標通常是要從影像中擷取意義 (或至少可操作的深入解析),因而必須建立已定型的機器學習模型,以根據大量的現有影像來辨識特徵。
提示
本單元假設您熟悉機器學習的基本原理,且具有使用神經網路進行深度學習的概念知識。 如果您不熟悉機器學習,建議您完成 Microsoft Learn 上的機器學習的基礎知識課程模組。
卷積神經網路 (CNN)
電腦視覺最常見的機器學習模型架構之一,是卷積神經網路 (CNN),這是一種深度學習架構。 CNN 會使用篩選從影像中擷取數值特徵圖,然後將特徵值饋送至深度學習模型中,以產生標籤預測。 例如,在影像分類案例中,標籤代表影像的主體 (換句話說,這是什麼的影像?)。 您可以使用不同種類水果 (例如蘋果、香蕉和橘子) 的影像來定型 CNN 模型,讓預測的標籤是指定影像中的水果類型。
在 CNN 的定型過程中,會使用隨機產生的權數值進行篩選核心的初始定義。 然後,在定型程序進行時,系統會根據已知的標籤值來評估模型預測,並調整篩選權數以提升精確度。 最後,定型的水果影像分類模型所使用的,將是最能準確擷取特徵以利識別不同種類水果的篩選權數。
下圖說明影像分類模型的 CNN 如何運作:
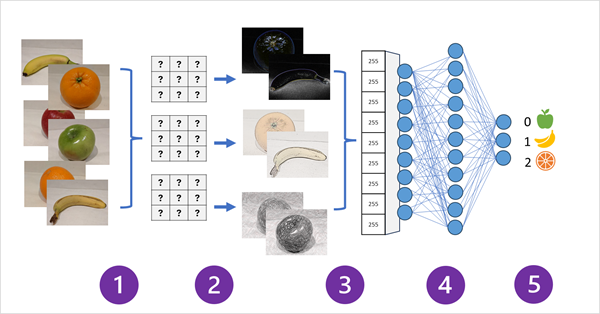
- 我們將具有已知標籤的影像 (例如,0:蘋果、1:香蕉或 2:橙色) 送入網路中,用以定型模型。
- 透過網路饋送影像時,有一或多個篩選層可用來從影像中擷取特徵。 篩選核心一開始會使用隨機指派的權數,並產生名為特徵圖的數值陣列。
- 特徵圖會扁平化為特徵值的單一維度陣列。
- 特徵值會送入完全連線的神經網路中。
- 神經網路的輸出層會使用 softmax 或類似的函式產生結果,其中包含每個可能類別的機率值,例如 [0.2, 0.5, 0.3]。
在定型期間,輸出機率會與實體類別標籤相比較,例如,香蕉 (類別 1) 的影像的值應為 [0.0, 1.0, 0.0]。 預測與實體類別分數之間的差異會用來計算模型中的損失,而完全連線的神經網路中的權數和特徵擷取層中的篩選核心會經過修改,以減少損失。
定型程序會重複多個 ,直到學習到一組最佳權數為止。 然後,權數會儲存起來,而模型可用來對標籤未知的新影像預測標籤。
注意
CNN 架構通常包含多個卷積篩選層和附加層,以減少特徵圖的大小、限制擷取的值,或是操作特徵值。 這個簡化的範例中省略了前述幾層,而將重點放在關鍵概念上,也就是篩選可用來從影像中擷取數值特徵,而特徵後續將神經網路中用來預測影像標籤。
轉換器和多重模組模型
CNN 多年來一直位居電腦視覺解決方案的核心。 雖然 CNN 如前所述通常用來解決影像分類問題,但其同時也是更複雜的電腦視覺模型的基礎。 例如,物件偵測模型會結合 CNN 特徵擷取層與影像中相關區域的識別,以在相同影像中找出多個物件類別。
轉換器
數十年來,電腦視覺的進展多半是由 CNN 模型的改良所推動的。 然而,在另一個 AI 專業領域 自然語言處理 (NLP) 中,另一種名為轉換器的神經網路架構讓人們得以開發複雜的語言模型。 轉換器的運作方式是處理大量資料,並將語言語彙基元 (代表個別單字或片語) 編碼為以向量為基礎的內嵌 (數值陣列)。 您可以將內嵌視為一組維度,每個維度分別代表語彙基元的某個語意屬性。 建立內嵌,讓在相同內容中常用的語彙基元在維度上比不相關的單字更接近。
下圖以簡單的範例顯示編碼為三維向量、且在 3D 空間中繪製的一些文字:
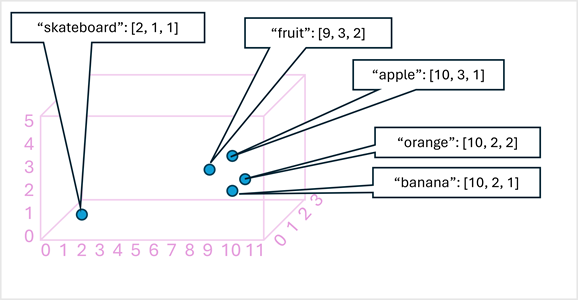
語意上類似的語彙基元會編碼於類似的位置,以建立能夠讓您建置複雜 NLP 解決方案的語意語言模型,供文字分析、翻譯、語言產生和其他工作使用。
注意
我們只使用了三個維度,因為這樣容易視覺化。 事實上,轉換器網路中編碼器會建立具有更多維度的向量,並根據線性代數計算來定義語彙基元之間的複雜語意關聯性。 涉及的數學很複雜,轉換器模型的架構也是如此。 在此,我們的目標是要提供概念讓您了解編碼如何建立模型,以封裝實體之間的關聯性。
多重模組模型
轉換器順利成為建置語言模型的途徑,促使 AI 研究人員開始考量相同的方法對於影像資料是否有效。 多重模組模型的開發於焉展開;這類模型使用大量附有文字說明、沒有固定標籤的影像來定型。 影像編碼器會根據像素值從影像中擷取特徵,並將其與語言編碼器所建立的文字內嵌結合。 整體模型會封裝自然語言語彙基元內嵌與影像特徵之間的關聯性,如下所示:
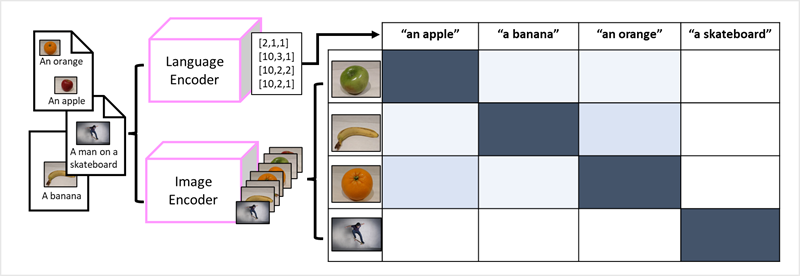
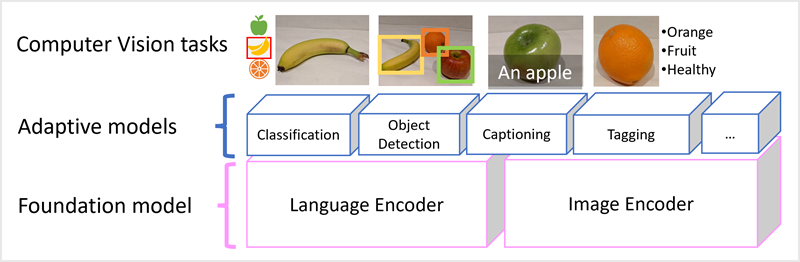
Microsoft Florence 模型就是這樣的模型。 使用大量附有文字說明的影像透過網際網路進行定型,其中包含語言編碼器和影像編碼器。 Florence 是基礎模型的範例。 換句話說,就是一個預先定型的模型,可讓您據以為專業工作建置多個自適性模型。 例如,您可以將 Florence 作為自適性模型的基礎模型,用以執行:
- 影像分類:識別影像所屬的類別。
- 物件偵測:在影像內尋找個別物件。
- 輔助字幕:產生適當的影像描述。
- 標記:編譯影像的相關文字標籤清單。
Florence 等多重模組模型通常位居電腦視覺和 AI 的前沿,可望能帶動因 AI 而實現的各種解決方案持續推展。