使用 KEDA 調整
Kube 事件導向自動調整
Kube 事件驅動自動調整 (KEDA) 是單一用途和輕量型元件,可簡化應用程式自動調整。 您可以將 KEDA 新增至任何 Kube 叢集,並將其與標準 Kube 元件搭配使用,例如水平 Pod 自動調整程式 (HPA) 或叢集自動調整程式,以擴充其功能。 透過 KEDA,您可以將目標設為想要利用事件驅動縮放的特定應用程式,並允許其他應用程式使用不同的縮放方法。 KEDA 是彈性且安全的選項,可與任意數量的 Kube 應用程式或架構一起執行。
主要功能和特徵
- 建置具有 [調整至零] 功能的可持續且符合成本效益的應用程式
- 使用 KEDA 調整程式調整應用程式工作負載以符合需求
- 使用
ScaledObjects自動調整應用程式 - 使用
ScaledJobs自動調整作業 - 藉由將自動調整和驗證與工作負載分離,以使用生產等級的安全性
- 自備外部調整程式以使用量身打造的自動調整設定
架構
KEDA 提供兩個主要元件:
- KEDA 運算子:可讓終端使用者在支援 Kube Deployments、Jobs、StatefulSets 或任何定義
/scale子資源的客戶資源情況下,將工作負載從零調整為 N 執行個體。 - 計量伺服器:會將外部計量公開給 HPA (例如 Kafka 主題中的訊息或 Azure 事件中樞中的事件),以驅動自動調整動作。 由於上游限制,KEDA 計量伺服器必須是叢集中唯一安裝的計量配接器。
下圖顯示 KEDA 如何與 Kube HPA、外部事件來源和 Kube 的 API 伺服器整合,以提供自動調整功能:
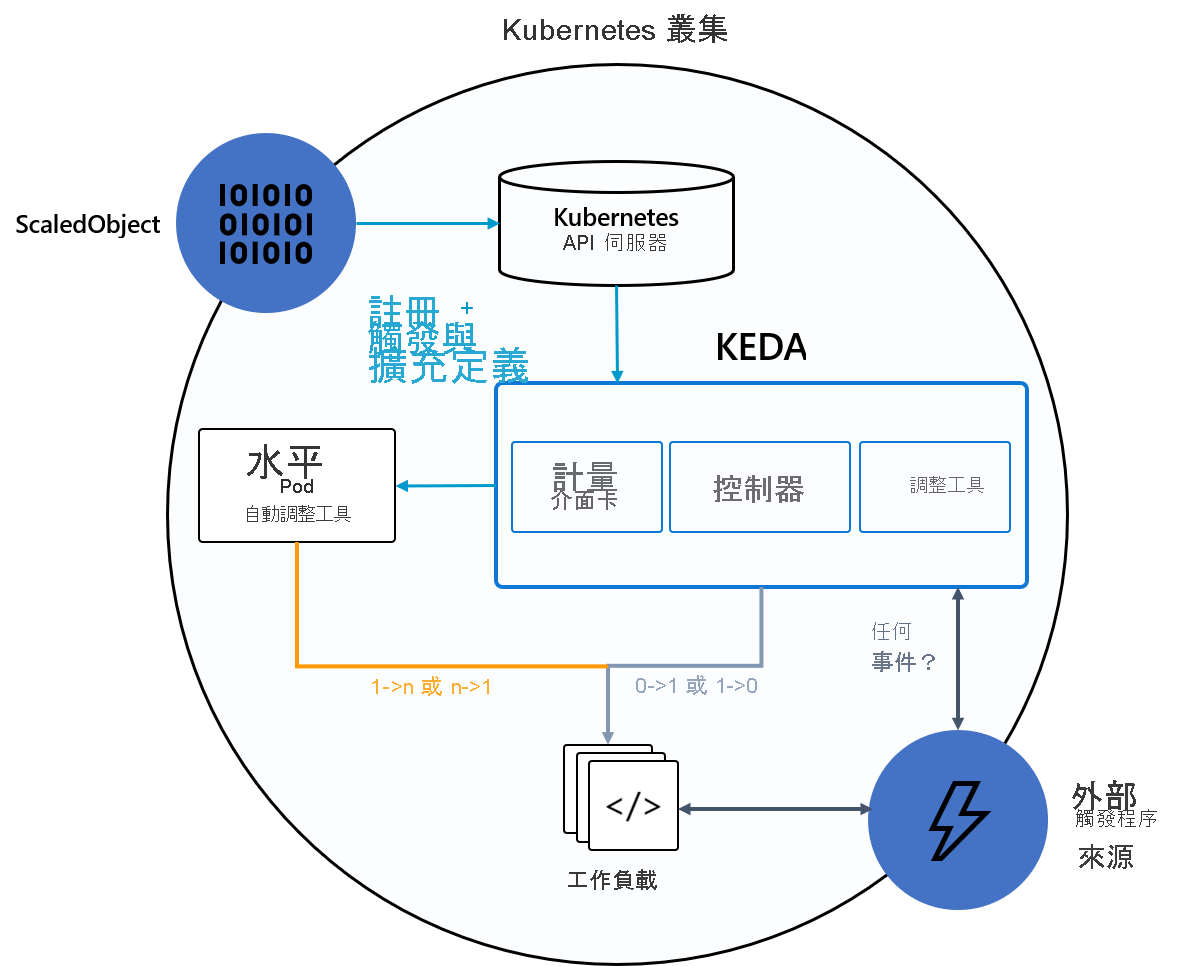
提示
如需詳細資訊,請參閱 KEDA 官方文件。
事件來源與調整程式
KEDA 調整程式可以偵測應該啟用或停用部署,並摘要特定事件來源的自訂計量。 部署與 StatefulSet 是使用 KEDA 調整工作負載最常見的方式。 您也可以調整實作 /scale 子資源的自訂資源。 您可定義您希望 KEDA 根據調整觸發程序進行調整的 Kube 部署或 StatefulSet。 KEDA 會監視這些服務,並根據發生的事件自動調整它們。
在幕後,KEDA 會監視事件來源,並將該資料摘要至 Kube 和 HPA,以加速資源縮放。 資源的每個複本都會主動地從事件來源提取項目。 透過 KEDA 與 Deployments/StatefulSets,您可以根據事件進行調整,同時透過事件來源來保留豐富的連線和處理語意 (例如,依序處理、重試、信件無效化、檢查點檢查)。
調整物件規格
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: {scaled-object-name}
spec:
scaleTargetRef:
apiVersion: {api-version-of-target-resource} # Optional. Default: apps/v1
kind: {kind-of-target-resource} # Optional. Default: Deployment
name: {name-of-target-resource} # Mandatory. Must be in the same namespace as the ScaledObject
envSourceContainerName: {container-name} # Optional. Default: .spec.template.spec.containers[0]
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 100 # Optional. Default: 100
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true/false # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
# {list of triggers to activate scaling of the target resource}
已調整的作業規格
作為將事件驅動程式代碼縮放為部署的替代方案,您也可以執行程式碼,並將程式碼縮放為 Kube 作業。 如果您需要處理長時間執行的執行作業,這會是考慮此選項的主要原因。 系統會針對每個偵測到的事件,排程其自己的 Kube 作業,而不是在部署內處理多個事件。 此方法可讓您隔離處理每個事件,並根據佇列中的事件數目來縮放並存執行次數。
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: {scaled-job-name}
spec:
jobTargetRef:
parallelism: 1 # [max number of desired pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
completions: 1 # [desired number of successfully finished pods](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/#controlling-parallelism)
activeDeadlineSeconds: 600 # Specifies the duration in seconds relative to the startTime that the job may be active before the system tries to terminate it; value must be positive integer
backoffLimit: 6 # Specifies the number of retries before marking this job failed. Defaults to 6
template:
# describes the [job template](https://kubernetes.io/docs/concepts/workloads/controllers/jobs-run-to-completion/)
pollingInterval: 30 # Optional. Default: 30 seconds
successfulJobsHistoryLimit: 5 # Optional. Default: 100. How many completed jobs should be kept.
failedJobsHistoryLimit: 5 # Optional. Default: 100. How many failed jobs should be kept.
envSourceContainerName: {container-name} # Optional. Default: .spec.JobTargetRef.template.spec.containers[0]
maxReplicaCount: 100 # Optional. Default: 100
scalingStrategy:
strategy: "custom" # Optional. Default: default. Which Scaling Strategy to use.
customScalingQueueLengthDeduction: 1 # Optional. A parameter to optimize custom ScalingStrategy.
customScalingRunningJobPercentage: "0.5" # Optional. A parameter to optimize custom ScalingStrategy.
triggers:
# {list of triggers to create jobs}