使用遺漏索引建議調整非叢集索引
適用於:![]() Microsoft Fabric 中的 SQL Server
Microsoft Fabric 中的 SQL Server![]() Azure SQL 資料庫
Azure SQL 資料庫![]() Azure SQL 受控執行個體
Azure SQL 受控執行個體 ![]() SQL 資料庫
SQL 資料庫
遺漏索引功能是一種輕量型工具,用來尋找可大幅提升查詢效能的遺漏索引。 本文介紹如何使用遺漏索引建議來有效調整索引及改善查詢效能。
遺漏索引功能的限制
查詢最佳化工具在產生查詢計劃時,會分析適合特定篩選條件的最佳索引。 如果最佳索引不存在,查詢最佳化工具仍會使用可用的最低成本存取方法來產生查詢計劃,但也會儲存這些索引的相關資訊。 遺漏索引功能可讓您存取這些最佳索引的資訊,讓您決定是否應該加以實作。
查詢最佳化是相當注重時間的流程,因此對遺漏索引功能有所限制。 限制包括:
- 遺漏索引建議的根據,是在執行查詢之前,進行單一查詢最佳化的期間所做的估計。 查詢執行之後,不會測試或更新遺漏索引建議。
- 遺漏索引功能只會建議非叢集磁片資料列存放區的索引。 不會建議不重複和經過篩選的索引。
- 會建議索引鍵資料行,但在建議中不會指定這類資料行的順序。 如需進一步了解資料行排序,請參閱本文的套用遺漏索引建議一節。
- 建議內含資料行,但當建議大量內含資料行時,SQL Server 不會針對結果索引的大小,執行任何成本效益分析。
- 遺漏索引要求可能會對查詢之間相同的資料表和資料行,提供類似的索引變化版本。 請務必檢閱索引建議,並盡可能合併。
- 不會對瑣碎的查詢計劃提出建議。
- 針對只涉及不相等述詞的查詢,成本資訊比較不精確。
- 最多只能針對 600 個遺漏索引群組收集建議。 達到此臨界值之後,便不會再收集任何遺漏索引群組資料。
由於這些限制,在執行索引分析、設計、調整和測試時,最好只將遺漏索引建議當作資訊來源之一。 遺漏索引建議並不是建立索引時必須完全遵循的方針。
注意
Azure SQL Database 提供自動索引調整。 自動索引調整會使用機器學習,透過 AI 從 Azure SQL Database 中的所有資料庫進行水平學習,並動態改善其調整動作。 自動索引調整包含驗證程序,以確保建立的索引對工作負載效能有正面改善。
檢視遺漏索引建議
遺漏索引功能是由兩大要素組成:
- 執行計畫的 XML 中的
MissingIndexes元素。 對於查詢最佳化工具視為遺漏的索引,此元素可讓您將這些索引與遺漏它們的查詢建立關聯。 - 一組可接受查詢以傳回遺漏索引資訊的動態管理檢視 (DMV)。 可用來檢視資料庫所有的遺漏索引建議。
檢視執行計畫中的遺漏索引建議
查詢執行計畫可以透過多種方式產生或取得:
- 撰寫或調整查詢時,您可以使用 SQL Server Management Studio (SSMS) 來顯示估計的執行計畫,而不執行查詢;或執行查詢並顯示實際的執行計畫。
- 查詢存放區啟用時,會收集執行計畫。
- 您可以查詢 DMV (例如 sys.dm_exec_text_query_plan) 來識別已快取處理的執行計畫。
例如可以使用下列查詢,針對 AdventureWorks 範例資料庫產生遺漏索引要求。
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
如何產生並檢視遺漏索引要求:
開啟 SSMS,並將工作階段連線到 AdventureWorks 範例資料庫的複本。
選取 [顯示估計執行計畫] 工具列按鈕,將查詢貼到工作階段中,並在 SSMS 中針對查詢產生估計的執行計畫。 執行計畫會在目前工作階段的窗格中顯示。 綠色的遺漏索引陳述式會出現在圖形計畫的頂端附近。
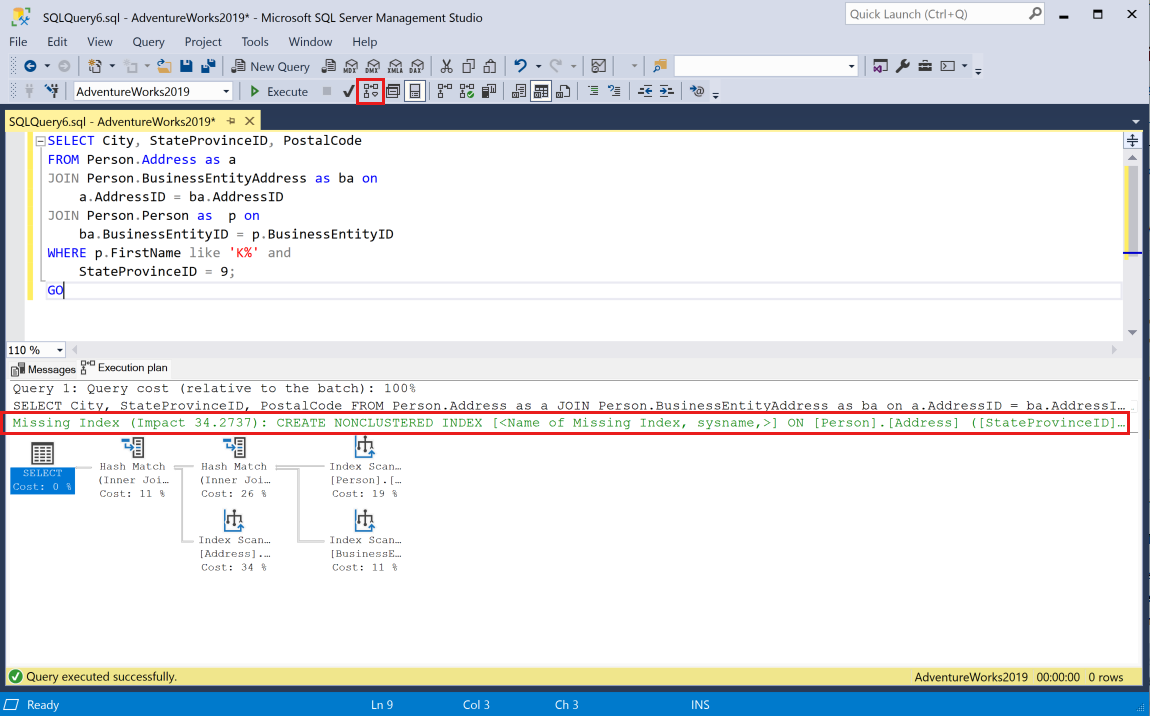
單一執行計畫可能會包含多個遺漏索引要求,但圖形執行計畫中只能顯示一個遺漏索引要求。 若要檢視執行計畫的遺漏索引完整清單,其中一個選項是檢視執行計畫 XML。
以滑鼠右鍵按一下執行計畫,然後從功能表中選取 [顯示執行計畫 XML...]。
執行計畫 XML 會在 SSMS 內以新的索引標籤開啟。
注意
只有單一遺漏索引建議會顯示在 [遺漏索引詳細資料...] 功能表選項中,即使執行計畫 XML 中有多個建議也一樣。 顯示的遺漏索引建議,對於查詢來說可能不是預估改善效果最好的建議。
使用 CTRL+f 快速鍵顯示 [尋找] 對話方塊。
搜尋
MissingIndex。![執行計畫的 XML 螢幕擷取畫面。[尋找] 對話方塊已開啟,而且已在文件中搜尋 MissingIndex 一詞。](media/missing-index-node-in-execution-plan-xml.png?view=azuresqldb-current)
在此範例中,有兩個
MissingIndex元素。

![執行計畫的 XML 螢幕擷取畫面。[尋找] 對話方塊已開啟,而且已在文件中搜尋 MissingIndex 一詞。](media/missing-index-node-in-execution-plan-xml.png?view=azuresqldb-current#lightbox)
資料庫中每個以磁碟為基礎的非叢集索引都會佔用空間,還會提高插入、更新和刪除作業的額外負荷,而且可能需要維護。 基於這些原因,最佳做法是先檢閱資料表和資料表上現有索引的所有遺漏索引要求,再根據查詢執行計畫新增索引。
在 DMV 中檢視遺漏索引建議
您可查詢下表中所列的動態管理物件,以擷取遺漏索引相關資訊。
| 動態管理檢視 | 傳回的資訊 |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | 傳回遺漏索引群組的摘要資訊 (例如,透過實作特定遺漏索引的群組而取得的效能改進)。 |
| sys.dm_db_missing_index_groups (Transact-SQL) | 傳回特定遺漏索引群組的資訊 (例如,群組識別碼和該群組所包含之所有遺漏索引的識別碼)。 |
| sys.dm_db_missing_index_details (Transact-SQL) | 傳回遺漏索引的詳細資訊;例如,它會傳回遺漏索引之資料表的名稱和識別碼,以及應組成遺漏索引的資料行和資料行類型。 |
| sys.dm_db_missing_index_columns (Transact-SQL) | 傳回遺漏索引之資料庫資料表資料行的資訊。 |
下列查詢會使用遺漏索引 DMV 來產生 CREATE INDEX 陳述式。 此處的索引建立陳述式,旨在協助您先檢查資料表的所有要求以及資料表上現有的索引,之後製作自己的 DDL。
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
此查詢在排序建議時,會依據名為 estimated_improvement 的資料行。 預估的改進效果是以下列項目的組合為準:
- 遺漏索引要求的相關聯查詢估計查詢成本。
- 加入索引所造成的估計影響。 這是非叢集索引可降低查詢成本的估計值。
- 對遺漏索引要求相關查詢所執行的查詢運算子 (seeks 和 scans) 的執行總和。 如同在使用查詢存放區保存遺漏索引時所述,此資訊會定期清除。
注意
Microsoft Tiger 工具箱中的 Index-Creation 指令碼會檢查遺漏索引 DMV,並自動移除任何多餘的建議索引、剖析出低影響索引,並產生索引建立指令碼以供檢閱。 如同上述查詢,它「不會」執行索引建立命令。 Index-Creation 指令碼適用於 SQL Server 和 Azure SQL 受控執行個體。 若為 Azure SQL 資料庫,請考慮實作自動索引調整。
請檢閱遺漏索引功能的限制,以及如何在建立索引之前套用遺漏索引建議,並修改索引名稱以符合資料庫的命名慣例。
使用查詢存放區保存遺漏索引
DMV 中的遺漏索引建議,會因執行個體重新啟動、容錯移轉和將資料庫設為離線等事件而清除。 此外,資料表的中繼資料變更時,會從這些動態管理物件中刪除該資料表的所有遺漏索引資訊。 例如,在資料表中加入或卸除資料行時,或在資料表的資料行建立索引時,都會變更資料表中繼資料。 在資料表上的索引上執行 ALTER INDEX REBUILD 作業,也會清除該資料表的遺漏索引要求。
儲存在計畫快取中的執行計畫,同樣會因執行個體重新啟動、容錯移轉和將資料庫設為離線等事件而清除。 執行計畫可能會因為記憶體壓力和重新編譯,而從快取中移除。
執行計畫中的遺漏索引建議,可以透過啟用查詢存放區在這些事件中加以保存。
下列查詢會根據查詢的總邏輯讀取量粗略估計,擷取前 20 個查詢計劃,其中包含來自 查詢存放區 的遺漏索引要求。 資料僅限於過去 48 小時內的查詢執行。
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
套用遺漏索引建議
若要有效地使用遺漏索引建議,請遵循非叢集索引設計指導方針。 使用遺漏索引建議調整非叢集索引時,請檢閱基底資料表結構、小心合併索引、考量索引鍵資料行順序,以及檢閱包含的資料行建議。
檢閱基底資料表結構
根據遺漏索引建議在資料表上建立非叢集索引之前,請先檢閱資料表的叢集索引。
檢查叢集索引的方法之一,是使用 sp_helpindex 系統預存程序。 例如,我們可藉由執行下列陳述式,來檢視 Person.Address 資料表上的索引摘要:
exec sp_helpindex 'Person.Address';
GO
檢閱 index_description 資料行。 資料表只能有一個叢集索引。 如果已實作資料表的叢集索引,則 index_description 將包含 'clustered' 一詞。

如果沒有叢集索引,資料表將是堆積。 在此情況下,請檢查資料表是否刻意建立為堆積,以解決特定效能問題。 大部分資料表都會受益於叢集索引,但資料表常會意外實作為堆積。 請考慮根據叢集索引設計指導方針來實作叢集索引。
檢閱遺漏索引和現有索引以尋找重疊
遺漏索引可能會對查詢之間相同的資料表和資料行,提供類似的非叢集索引變化版本。 遺漏索引也可能類似於資料表上的現有索引。 為了獲得最佳效能,最好檢查遺漏索引和現有索引是否重疊,並避免建立重複的索引。
編寫資料表上現有索引的指令碼
檢查資料表上現有索引定義的方法之一,就是使用「物件總管詳細資料」編寫索引指令碼:
- 將物件總管連線到您的執行個體或資料庫。
- 在物件總管中展開指定資料庫的節點。
- 展開 [資料表] 資料夾。
- 展開您要編寫索引指令碼的資料表。
- 選取 [索引] 資料夾。
- 如果尚未開啟 [物件總管詳細資料] 窗格,請在 [檢視] 功能表上,選取 [物件總管詳細資料] 或按 F7。
- 使用快速鍵 CTRL+a,選取 [物件總管詳細資料] 窗格上所列的所有索引。
- 以滑鼠右鍵按一下所選區域中的任何位置,然後選取功能表選項 [Script index as]\(將指令碼編寫為\),然後選取 [建立至] 和 [新增查詢編輯器視窗]。
![螢幕快照:使用 SSMS 中的 [物件總管 詳細數據] 窗格,在數據表上編寫所有索引的腳本。](media/object-explorer-details-script-all-indexes.png?view=azuresqldb-current#lightbox)
檢閱索引,並盡可能合併
可以用群組形式檢閱資料表的遺漏索引建議,以及資料表上現有索引的定義。 請記得一點,在定義索引時,通常建議在不等資料行之前放置相等資料行,而且它們應當要形成索引的索引鍵。 若要決定相等資料行的有效次序,請依據其選擇性排列這些資料行:將選擇性最高的資料行列在最前面 (資料行清單的最左邊)。 不重複資料行最具選擇性,而具有許多重複值的資料行選擇性較低。
您應該使用 INCLUDE 子句,將內含資料行加入 CREATE INDEX 陳述式中。 內含資料行的順序不會影響查詢效能。 因此,合併索引時可能會合併內含資料行,而不需要擔心順序。 深入瞭解內含資料行指導方針。
例如,您可能有一個資料表 Person.Address,其索引鍵資料行 StateProvinceID 上有現有的索引。 您可能會看到下列資料行的 Person.Address 資料表遺漏索引建議:
StateProvinceID和City的 EQUALITY 篩選條件StateProvinceID和City(包含PostalCode) 的 EQUALITY 篩選條件
若修改現有的索引以符合第二項建議 (索引具有索引鍵 StateProvinceID 和包含 PostalCode 的 City),則可能會滿足產生這兩個索引建議的查詢。
索引調整經常需要權衡取捨。 對於許多資料集而言,資料行 City 可能比資料行 StateProvinceID 在挑選時更具選擇性。 不過,如果已大量使用 StateProvinceID 上的現有索引,而其他要求主要同時搜尋 StateProvinceID 和 City,則對於資料庫總體來說,使用單一索引並將兩個欄位作為索引鍵的負擔較低,而以 StateProvinceID 做為前置 (儘管這並不是最具選擇性的欄位)。
索引可透過多種方式修改:
- 可使用 CREATE INDEX 陳述式搭配 DROP_EXISTING 子句。 可依照修改情況來重新命名索引,如此便能根據命名慣例,讓名稱仍能精確地描述索引定義。
- 可使用 DROP INDEX (Transact-SQL) 陳述式,後接 CREATE INDEX 陳述式。
合併索引建議時,索引鍵的順序很重要:City 作為前置資料行與 StateProvinceID 作為前置資料行不同。 深入瞭解非叢集索引設計指導方針。
建立索引時,請考慮在提供使用時,使用線上索引作業。
雖然索引在某些情況下可以大幅改善查詢效能,但索引也具有額外負荷和管理成本。 請參閱一般索引設計指導方針,以利在建立索引之前評估索引的效益。
確認索引變更是否成功
請務必確認您的索引變更是否成功:查詢最佳化工具是否在使用您的索引?
驗證索引變更的其中一種方式,是使用查詢存放區來識別使用遺漏索引要求的查詢。 請注意查詢的 query_id。 可使用查詢存放區中的 [追蹤查詢] 檢視,檢查某個查詢的執行計畫是否經過變更,以及最佳化工具是否在使用新的或修改過的索引。 若要深入瞭解追蹤查詢,請參閱查詢效能疑難排解入門中,。
相關內容
可透過下列文章,深入瞭解索引和效能微調: