設定 Windows 和 Linux 上的 SQL Server Always On 可用性群組 (跨平台)
適用於:![]() SQL Server 2017 (14.x) 和更新版本
SQL Server 2017 (14.x) 和更新版本
本文說明使用 Windows 伺服器上某個複本和 Linux 伺服器上另一個複本建立 Always On 可用性群組 (AG) 的步驟。
重要
SQL Server 跨平台可用性群組,其中包含具有完整高可用性和災害復原支援的異質複本,可供 DH2i DxEnterprise 使用。 如需詳細資訊,請參閱使用混合作業系統的 SQL Server 可用性群組。
檢視下列影片,以瞭解使用 DH2i 的跨平台可用性群組。
由於複本位於不同的作業系統上,因此這是一種跨平台設定。 您可將此設定用於從某個平台移轉至其他平台或災害復原 (DR)。 此組態不支援高可用性。

在繼續之前,您應該先熟悉 Windows 和 Linux 上的 SQL Server 執行個體安裝和設定。
狀況
在此案例中,兩部伺服器位於不同的作業系統。 裝載主要複本、名為 WinSQLInstance 的 Windows Server 2022。 次要複本裝載在名為 LinuxSQLInstance 的 Linux 伺服器。
設定 AG
建立 AG 的步驟與建立用於讀取級別工作負載 AG 步驟相同。 AG 叢集類型為 NONE,因為沒有叢集管理員。
本文中指令碼會使用角括弧 < 和 > 來識別您必須依據環境取代的值。 指令碼本身不需要角括弧。
在 Windows Server 2022 上安裝 SQL Server 2022 (16.x)、從 SQL Server 組態管理員啟用 Always On 可用性群組,以及設定混合模式驗證。
提示
如果您要在 Azure 中驗證此解決方案,請將這兩部伺服器放在相同的可用性設定組中,確保它們會在資料中心內區隔開來。
啟用可用性群組
如需指示,請參閱啟用或停用 Always On 可用性群組功能。
SQL Server 組態管理員會注意到電腦不是容錯移轉叢集中的節點。
啟用可用性群組之後,請重新啟動 SQL Server。
設定混合模式驗證
如需指示,請參閱變更伺服器驗證模式。
在 Linux 上安裝 SQL Server 2022 (16.x)。 如需指示,請參閱 Linux 上的 SQL Server 安裝指引。 使用 mssql-conf 啟用
hadr。若要從殼層提示透過 mssql-conf 啟用
hadr,請發出下列命令:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1啟用
hadr之後,請重新啟動 SQL Server 執行個體:sudo systemctl restart mssql-server.service在兩部伺服器上設定
hosts檔案,或向 DNS 註冊伺服器名稱。在 Windows 和 Linux 上開啟 TCP 1433 和 5022 的防火牆連接埠。
在主要複本上,建立資料庫登入和密碼。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO警告
您的密碼應遵循 SQL Server 預設 密碼原則。 依預設,密碼長度必須至少有 8 個字元,並包含下列四種字元組合中其中三種組合的字元:大寫字母、小寫字母、以 10 為底數的數字以及符號。 密碼長度最多可達 128 個字元。 盡可能使用長且複雜的密碼。
在主要複本上,建立主要金鑰和憑證,然後使用私密金鑰來備份憑證。
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GO警告
您的密碼應遵循 SQL Server 預設 密碼原則。 依預設,密碼長度必須至少有 8 個字元,並包含下列四種字元組合中其中三種組合的字元:大寫字母、小寫字母、以 10 為底數的數字以及符號。 密碼長度最多可達 128 個字元。 盡可能使用長且複雜的密碼。
將憑證和私密金鑰複製到 Linux 伺服器 (次要複本) 的
/var/opt/mssql/data位置。 您可以使用pscp,將檔案複製到 Linux 伺服器。將私密金鑰與憑證的群組和擁有權設定為
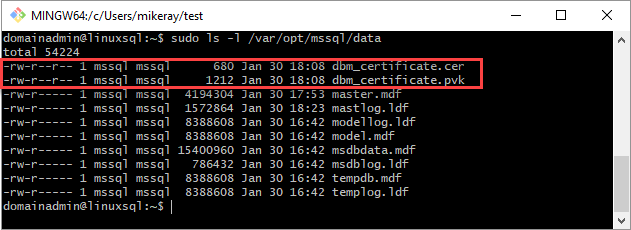
mssql:mssql。下列指令碼會設定這些檔案的群組和擁有權。
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cer下圖已正確設定憑證與金鑰的擁有權和群組。
在次要複本上,建立資料庫登入和密碼,然後建立主要金鑰。
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GO警告
您的密碼應遵循 SQL Server 預設 密碼原則。 依預設,密碼長度必須至少有 8 個字元,並包含下列四種字元組合中其中三種組合的字元:大寫字母、小寫字母、以 10 為底數的數字以及符號。 密碼長度最多可達 128 個字元。 盡可能使用長且複雜的密碼。
在次要複本上,還原您複製到
/var/opt/mssql/data的憑證。CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GO在上一個範例中,將 取代
<private-key-password>為您在主要複本上建立憑證時所使用的相同密碼。在主要複本上,建立端點。
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GO重要
您必須為接聽程式 TCP 通訊埠開啟防火牆。 在前一段指令碼中,連接埠為 5022。 使用任何可用的 TCP 通訊埠。
在次要複本上,建立端點。 在次要複本上重複前一段指令碼,以建立端點。
在主要複本上,建立
CLUSTER_TYPE = NONE的 AG。 範例指令碼會使用SEEDING_MODE = AUTOMATIC來建立 AG。注意
當 SQL Server 的 Windows 執行個體使用不同資料和記錄檔路徑時,自動植入 SQL Server 的 Linux 執行個體會失敗,因為這些路徑不存在於次要複本上。 若要針對跨平台 AG 使用下列指令碼,資料庫必須具備 Windows 伺服器上資料和記錄檔的相同路徑。 或者,您可以更新指令碼以設定
SEEDING_MODE = MANUAL,然後使用NORECOVERY來備份和還原資料庫,以植入資料庫。上述行為適用於 Azure Marketplace 映像。
如需自動植入的詳細資訊,請參閱自動植入 - 磁碟配置。
執行指令碼之前,請先更新 AG 的值。
將
<WinSQLInstance>取代為主要複本 SQL Server 執行個體的伺服器名稱。將
<LinuxSQLInstance>取代為次要複本 SQL Server 執行個體的伺服器名稱。
若要建立 AG,請更新值,並在主要複本上執行指令碼。
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); ) GO如需詳細資訊,請參閱 CREATE AVAILABILITY GROUP。
在次要複本上,加入 AG。
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GO建立 AG 的資料庫。 範例步驟會使用名為
TestDB的資料庫。 如果您使用自動植入,請為資料和記錄檔設定相同的路徑。執行指令碼之前,請先更新資料庫的值。
將
TestDB取代為您的資料庫名稱。將
<F:\Path>取代為您的資料庫和記錄檔路徑。 針對資料庫和記錄檔使用相同的路徑。
您也可以使用預設路徑。
若要建立您的資料庫,請執行指令碼。
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY(NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GO完整備份資料庫。
如果您不是使用自動植入,請在次要複本 (Linux) 伺服器上還原資料庫。 使用備份與還原將 SQL Server 資料庫從 Windows 移轉至 Linux。 在次要複本上還原資料庫
WITH NORECOVERY。將資料庫新增至 AG。 更新範例指令碼。 將
TestDB取代為您的資料庫名稱。 在主要複本上,執行 T-SQL 查詢以將資料庫新增至 AG。ALTER AG [ag1] ADD DATABASE TestDB; GO驗證資料庫是否開始填入次要複本。

容錯移轉主要複本
每個可用性群組只有一個主要複本。 主要複本允許讀取和寫入。 若要變更作為主要的複本,您可以進行容錯移轉。 在一般可用性群組中,叢集管理員會自動化容錯移轉程序。 在叢集類型為 NONE 的可用性群組中,容錯移轉程序是手動的。
叢集類型為 NONE 的可用性群組中,有兩種方式可進行主要複本容錯移轉:
- 手動容錯移轉 (不會遺失資料)
- 強制手動容錯移轉 (可能遺失資料)
手動容錯移轉 (不會遺失資料)
當主要複本可以使用,但您需要暫時或永久變更裝載主要複本的執行個體時,請使用這個方法。 若要避免遺失資料的可能性,發出手動容錯移轉之前,請確定目標次要複本是最新狀態。
若要手動容錯移轉 (不會遺失資料):
請製作目前的主要複本與目標次要複本
SYNCHRONOUS_COMMIT。ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);若要識別使用中交易已認可至主要複本及至少一個同步次要複本,請執行下列查詢:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;當
synchronization_state_desc為SYNCHRONIZED時,即會同步處理次要複本。將
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT更新為 1。下列指令碼會將名為
ag1的可用性群組上的REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT設為 1。 執行下列指令碼之前,以您的可用性群組名稱取代ag1:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);這項設定可確保所有使用中交易都已認可至主要複本及至少一個同步次要複本。
注意
這項設定非容錯移轉所特定,且應該根據環境的需求進行設定。
以離線方式設定未參與容錯移轉的主要複本和次要複本,以準備進行角色變更:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE將目標次要複本升階為主要。
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;將舊的主要複本和其他次要複本的角色更新為
SECONDARY,並在裝載舊主要複本的 SQL Server 執行個體上執行下列命令:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);注意
若要刪除可用性群組,請使用 DROP AVAILABILITY GROUP。 針對以叢集類型 NONE 或 EXTERNAL 建立的可用性群組,請在屬於可用性群組的所有複本上執行此命令。
繼續進行資料移動,在裝載主要複本的 SQL Server 執行個體上,針對可用性群組中的每個資料庫執行下列命令:
ALTER DATABASE [db1] SET HADR RESUME重新建立為讀取縮放目的而建立的任何接聽程式,且不由叢集管理員所管理。 如果原始接聽程式指向舊的主要複本,請將其捨棄,然後重新建立接聽程式以指向新的主要複本。
強制手動容錯移轉 (可能遺失資料)
如果主要複本無法使用且無法立即復原,則您必須在會遺失資料的情況下強制容錯移轉至次要複本。 不過,如果原始的主要複本在容錯移轉後復原,其便會擔任主要角色。 若要避免讓每個複本處於不同的狀態,請在會遺失資料的情況下進行強制容錯移轉之後,從可用性群組移除原始的主要複本。 一旦原始主要複本重新上線,請從其中完全移除可用性群組。
若要在會遺失資料的情況下從主要複本 N1 強制手動容錯移轉至次要複本 N2,請遵循下列步驟:
在次要複本 (N2) 上,起始強制容錯移轉:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;在新的主要複本 (N2) 上,移除原始的主要複本 (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';驗證所有應用程式流量都指向接聽程式和/或新的主要複本。
如果原始的主要複本 (N1) 上線,請立即讓原始主要複本 (N1) 上的 AGRScale 可用性群組離線:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINE如果有資料或未同步的變更,請透過備份或其他符合您業務需求的資料複寫選項來保留此資料。
接下來,從原始的主要複本 (N1) 移除該可用性群組:
DROP AVAILABILITY GROUP [AGRScale];在原始主要複本 (N1) 上卸載可用性群組資料庫:
USE [master] GO DROP DATABASE [AGDBRScale] GO(選用) 如有需要,您現在可以將 N1 以新次要複本的形式重新新增回 AGRScale 可用性群組。
本文複習建立跨平台 AG 以支援移轉或讀取級別工作負載的步驟。 本文可用於手動災害復原, 同時說明如何容錯移轉 AG。 跨平台 AG 會使用叢集類型 NONE,且不支援高可用性。