設定分散式 Always On 可用性群組
適用於:![]() SQL Server
SQL Server
若要建立分散式可用性群組,您必須建立兩個各有其專用接聽程式的可用性群組。 隨後您再將這些可用性群組合併成分散式的可用性群組。 下列步驟提供 TRANSACT-SQL 中的基本範例。 本範例未涵蓋關於建立可用性群組與接聽程式的所有詳細資料,而僅著重探討與其相關的重要需求。
如需分散式可用性群組的技術概觀,請參閱分散式可用性群組。
必要條件
要設定分散式可用性群組,您必須具備下列條件:
- 支援的 SQL Server 版本。
注意
如果您在 Azure VM 上的 SQL Server 上,使用分散式網路名稱(DNN)設定可用性群組的接聽程式,則無法支援在該可用性群組上設定分散式可用性群組。 若要深入了解,請參閱 Azure VM 上的 SQL Server 具有與 AG 和 DNN 接聽程式的功能互通性。
設定端點接聽程式來接聽所有 IP 位址
請確定端點可以在分散式可用性群組的不同可用性群組之間進行通訊。 如果某個可用性群組設定為端點上的特定網路,分散式可用性群組將無法正常運作。 在裝載分散式可用性群組中某個複本的每部伺服器上,請設定用來接聽所有 IP 位址的接聽程式 (LISTENER_IP = ALL)。
建立端點以接聽所有 IP 位址
例如,下列指令碼會在 TCP 通訊埠 5022 上建立接聽程式端點,接聽所有 IP 位址。
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
改變端點以接聽所有 IP 位址
例如,下列指令碼會變更接聽程式端點,接聽所有 IP 位址。
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
建立第一個可用性群組
在第一個叢集上建立主要可用性群組
在第一個 Windows Server 容錯移轉叢集 (WSFC) 上建立可用性群組。 在此範例中,會針對資料庫 ag1 將可用性群組命名為 db1。 主要可用性群組的主要複本在分散式可用性群組中稱為「全域主要」。 Server1 在此範例中是全域主要。
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
上一個範例係採用自動植入,並針對複本與分散式可用性群組將 SEEDING_MODE 設為 AUTOMATIC。 這個組態會將次要複本與次要可用性群組設定成自動填入,無須手動備份和還原主要資料庫。
將次要複本聯結至主要可用性群組
任何次要複本皆必須透過 JOIN 選項,聯結至具 ALTER AVAILABILITY GROUP 的可用性群組。 由於此範例採用自動植入,因此您還必須透過 GRANT CREATE ANY DATABASE 選項呼叫 ALTER AVAILABILITY GROUP。 此設定可讓可用性群組建立資料庫,並開始自動從主要複本將其植入。
在此範例中,系統會在次要複本 server2執行下列命令,以聯結 ag1 可用性群組。 接著會允許可用性群組在次要複本上建立資料庫。
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
注意
當可用性群組在次要複本上建立資料庫時,它會將資料庫擁有者設成執行 ALTER AVAILABILITY GROUP 陳述式以授與建立任何資料庫權限的帳戶。 如需完整資訊,請參閱授與可用性群組在次要複本上建立資料庫的權限。
建立主要可用性群組的接聽程式
接下來要在第一個 WSFC 上建立主要可用性群組。 在此範例中,接聽程式會命名為 ag1-listener。 如需建立接聽程式的詳細指示,請參閱建立或設定可用性群組接聽程式 (SQL Server)。
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
建立第二個可用性群組
接著在第二個 WSFC 上,建立第二個可用性群組 ag2。 在此情況下,不會指定資料庫,因為它會自動從主要可用性群組植入。 次要可用性群組的主要複本在分散式可用性群組中稱為「轉寄站」。 在此範例中,server3 是轉寄站。
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
注意
次要可用性群組必須使用相同的資料庫鏡像端點 (在本範例中為通訊埠 5022)。 否則在執行本機容錯移轉後將會停止複寫。
將次要複本聯結至次要可用性群組
在此範例中,系統會在次要複本 server4執行下列命令,以聯結 ag2 可用性群組。 接著會允許可用性群組在次要複本上建立資料庫,以支援自動植入。
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
建立次要可用性群組的接聽程式
接下來要在第二個 WSFC 上建立次要可用性群組。 在此範例中,接聽程式會命名為 ag2-listener。 如需建立接聽程式的詳細指示,請參閱建立或設定可用性群組接聽程式 (SQL Server)。
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
在第一個叢集上建立分散式可用性群組
在第一個 WSFC 上,建立分散式可用性群組 (在此範例中名為 distributedAG )。 使用 CREATE AVAILABILITY GROUP 命令搭配 DISTRIBUTED 選項。
AVAILABILITY GROUP ON 參數會指定成員可用性群組 ag1 和 ag2。
若要使用自動植入來建立分散式可用性群組,請使用下列 Transact-SQL 程式碼:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
注意
LISTENER_URL 會指定每個可用性群組的接聽程式,以及可用性群組的資料庫鏡像端點。 在此範例中,其為通訊埠 5022 (非用於建立接聽程式的通訊埠 60173 )。 如果您使用負載平衡器,例如在 Azure 中,為分散式可用性群組埠新增負載平衡規則。 除了 SQL Server 執行個體連接埠之外,還需要新增接聽程式連接埠的規則。
取消自動植入轉寄站
無論出於什麼原因,若在同步兩個可用性群組「之前」必須取消轉寄站的初始化,請透過將轉寄站的 SEEDING_MODE 參數設為 MANUAL 並立即取消植入來 ALTER 分散式可用性群組。 在全域主要上執行命令:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
將分散式可用性群組加入第二個叢集
然後在第二個 WSFC 上聯結分散式可用性群組。
若要使用自動植入來聯結分散式可用性群組,請使用下列 Transact-SQL 程式碼:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
聯結第二個可用性群組次要複本上的資料庫
如果已將第二個可用性群組設定為使用自動植入,請移至步驟 2。
如果第二個可用性群組使用手動植入,則將您採用全域主要的備份還原到第二個可用性群組的次要:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;在第二個可用性群組的次要複本上的資料庫處於還原中狀態後,您必須手動將它聯結至可用性群組。
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
容錯移轉分散式可用性群組
自 SQL Server 2022 (16.x) 引入 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定的分散式可用性群組支援後,SQL Server 2022 及更新版本的分散式可用性容錯移轉指示與 SQL Server 2019 及更早版本不同。
對於分散式可用性群組,唯一支援的容錯移轉類型是手動使用者啟動的 FORCE_FAILOVER_ALLOW_DATA_LOSS。 因此,若要防止資料遺失,您必須採取額外的步驟 (本節中詳述),以確保在啟動容錯移轉之前,兩個複本之間的資料會同步處理。
如果發生可接受資料遺失的緊急狀況,您可以啟動容錯移轉,而不需執行下列動作來確保資料同步處理:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
您可以使用相同的命令來容錯移轉至轉寄站,以及容錯回復至全域主要複本。
在 SQL Server 2022 (16.x) 及更新版本上,您可以設定分散式可用性群組的 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定,旨在保證分散式可用性群組容錯移轉時不會遺失任何資料。 如果設定此設定,請遵循本節中的步驟來容錯移轉您的分散式可用性群組。 如果您不想使用 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定,請遵循指示,在 SQL Server 2019 及更早版本中容錯移轉分散式可用性群組。
注意
將 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 設定為 1 表示主要副本會先等候次要副本上的交易完成,再在主要副本上完成,這樣可能會降低效能。 雖然不需要在 SQL Server 2022(16.x)中對全域初始副本限制或停止交易以便分散式可用性群組同步,但這樣做可提升使用者交易和分散式可用性群組與設為 1 的 REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT 同步處理的效能。
確保不會遺失數據的步驟
若要確保不會遺失數據,您必須先設定分散式可用性群組,以遵循下列步驟來不支援數據遺失:
- 若要準備故障轉移,請確認全域主要 和 全域轉寄站均處於
SYNCHRONOUS_COMMIT模式。 如果沒有,請將它們從SYNCHRONOUS_COMMIT設定到 ,然後使用 ALTER AVAILABILITY GROUP。 - 在 和 上將分散式可用性群組設定為同步認可的全域主要和轉寄站。
- 等待分散式可用性群組同步完成。
- 在全域主要複本上,使用 ALTER AVAILABILITY GROUP,將分散式可用性群組
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT的設定選項設為 1。 - 確認本地可用性群組和分散式可用性群組中的所有複本皆為健康,且分散式可用性群組 SYNCHRONIZED。
- 在全域主要複本上,將分散式可用性群組角色設定為
SECONDARY,使分散式可用性群組無法使用。 - 在轉送器(即預定的新主要復本)上,使用 ALTER AVAILABILITY GROUP 搭配
FORCE_FAILOVER_ALLOW_DATA_LOSS來執行故障轉移分散式可用性群組。 - 在新的次要複本(先前的全域主要複本)上,將分散式可用性群組
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT設定為 0。 - 選擇性:如果可用性群組跨越造成延遲的地理距離,請將可用性模式變更為
ASYNCHRONOUS_COMMIT。 如有必要,這會將第一步的變更還原。
T-SQL 範例
本節提供詳細範例中的步驟,示範如何使用 Transact-SQL 來故障轉移名為 distributedAG 的分散式可用性群組。 範例環境共有 4 個節點供分散式可用性群組使用。 全域主要 N1 和 N2 主機可用性群組 ag1,以及全域轉寄站 N3 和 N4 主機可用性群組 ag2。 分散式可用性群組 distributedAG 會將變更從 ag1 推送至 ag2。
用來確認是組成分散式可用性群組的一部分的本機可用性群組的主副本的
SYNCHRONOUS_COMMIT查詢。 直接在全域轉寄站 和 全域主要上執行下列 T-SQL:SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);在 全域主要和轉寄站上,於
執行下列程式碼,將分散式可用性群組設定為同步提交: -- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);注意
在分散式可用性群組中,兩個可用性群組之間的同步處理狀態會取決於這兩個複本的可用性模式。 使用同步認可模式時,目前的主要可用性群組與目前的次要可用性群組都必須具有
SYNCHRONOUS_COMMIT可用性模式。 基於這個理由,您必須在全域主要復本和轉寄站上執行此腳本。等到分散式可用性群組的狀態變更為
SYNCHRONIZED。 在全域主要資料庫上執行下列查詢:-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];在可用性群組 的同步狀態描述 為
SYNCHRONIZED時繼續進行。針對 SQL Server 2022 (16.x) 和更新版本,在全域主伺服器上,使用下列 T-SQL 將
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT設定為 1:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);檢查所有副本的可用性群組狀態是否良好,方法是查詢全域主節點 和轉送者。
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');在全域主要上,將分散式可用性群組角色設定為
SECONDARY。 目前無法使用分散式可用性群組。 在此步驟完成之後,您無法回復到先前狀態,直到執行其餘步驟為止。ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);在轉寄器上執行下列查詢以切換可用性群組,並將分散式可用性群組恢復為線上狀態,以便從全域主節點進行故障轉移:
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;在此步驟之後:
- 全域主要從
N1轉換至N3。 - 全域轉寄站會從
N3轉換為N1。 - 分散式可用性群組可供使用。
- 全域主要從
在新的轉寄站上(先前的全域主要複本,
N1),將分散式可用性群組屬性REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT設定為0,以清除該屬性。ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);OPTIONAL:如果可用性群組跨越地理距離而產生延遲,請考慮在全域主要和轉寄站上將可用性模式變更回
ASYNCHRONOUS_COMMIT。 如果需要,這會還原第一個步驟中所做的變更。-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
移除分散式可用性群組
下列 Transact-SQL 陳述式會移除名為 distributedAG的分散式可用性群組:
DROP AVAILABILITY GROUP distributedAG;
在容錯移轉叢集執行個體上建立分散式可用性群組
您可以使用容錯移轉叢集執行個體 (FCI) 上的可用性群組,建立分散式可用性群組。 在此情況下,您不需要可用性群組接聽程式。 請使用 FCI 執行個體之主要複本的虛擬網路名稱 (VNN)。 下列範例顯示稱為 SQLFCIDAG 的分散式可用性群組。 一個可用性群組為 SQLFCIAG。 SQLFCIAG 有兩個 FCI 複本。 主要 FCI 複本的 VNN 是 SQLFCIAG-1,而次要 FCI 複本的 VNN 是 SQLFCIAG-2。 分散式可用性群組也包含 SQLAG-DR,可用於災害復原。
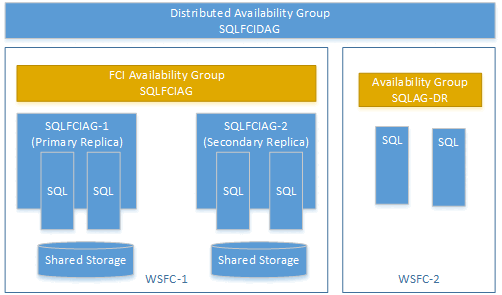
下列 DDL 會建立此分散式可用性群組:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
接聽程式 URL 會是主要 FCI 執行個體的 VNN。
手動容錯移轉分散式可用性群組中的 FCI
若要手動容錯移轉 FCI 可用性群組,請更新分散式可用性群組以反映接聽程式 URL 的變更。 例如,在分散式 AG 的全域主要和 SQLFCIDAG 分散式 AG 的轉寄站上,執行下列 DDL:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)