Always On 可用性群組租用、叢集和健全狀況檢查逾時的機制和方針
硬體、軟體和叢集組態中的差異,以及執行時間和效能的不同應用程式需求,都需要特別設定租用、叢集和健全狀況檢查逾時值。 有些應用程式和工作負載需要更主動的監視,以限制永久性失敗 (Hard Failure) 之後的停機時間。 其他則需要對高資源使用量所造成的暫時性網路問題和等候有較高的容忍度,而且容錯移轉速度可以較慢。
每個節點上會執行多項服務來偵測失敗。 叢集服務可偵測仲裁遺失,資源 DLL 可偵測 Always On 健康情況偵測所呈現的問題,您也可以在主要執行個體上直接起始手動容錯移轉。 叢集服務、資源裝載和 SQL Server 執行個體會透過 RPC、共用記憶體和 T-SQL 彼此同步處理。 在大部分案例中,這些服務會順利通訊,但此通訊即使在相同機器的服務之間也不完全可靠。 此外,可用性群組 (AG) 必須能夠承受全系統事件 (例如網路和磁碟失敗),這些事件可能會導致無法通訊或中斷功能。 由於許多失敗案例,以及服務之間沒有完全可靠的通訊,AG 需要各種容錯移轉偵測機制來獨立偵測及回應失敗,以確保所有節點永遠都會有一致的叢集狀態。
叢集節點和資源偵測
叢集中的每個節點會執行單一叢集服務,來操作容錯移轉叢集,並監視所有叢集資源。 資源裝載會以個別處理序運作,而且是叢集服務與叢集資源之間的介面。 資源裝載會在叢集服務呼叫的叢集資源上執行作業。 感知叢集應用程式 (例如 SQL Server) 會透過資源 DLL 提供自訂介面給資源監視器。 資源 DLL 會對自訂資源實作線上和離線作業,以及健全狀況監視。 資源裝載是叢集服務的子處理序,只要終止叢集服務,就會一併終止。
對於 SQL Server,AG 資源 DLL 會根據 AG 租用機制和 Always On 健全狀況偵測來判斷 AG 的健全狀況。 AG 資源 DLL 會透過 IsAlive 作業公開資源健全狀況。 資源監視器會依叢集活動訊號間隔輪詢 IsAlive,這是由整個叢集的 CrossSubnetDelay 和 SameSubnetDelay 值所設定。 在主要節點上,只要資源 DLL 的 IsAlive 呼叫傳回 AG 狀況不良,叢集服務就會起始容錯移轉。
叢集服務會將活動訊號傳送至叢集中的其他節點,並確認從中收到活動訊號。 當節點從一連串未認可的活動訊號偵測到通訊失敗時,它會廣播訊息,使所有可連線的節點協調其叢集節點健全狀況檢視。 此事件稱為「復原群組事件」 ,可維護節點之間的叢集狀態一致性。 在復原群組事件之後,如果仲裁遺失,則此分割區中的所有叢集資源 (包括 AG) 都會離線。 此分割區中的所有節點會轉換成解析中狀態。 如果存在持有仲裁的分割區,則 AG 會指派至分割區中的一個節點並成為主要複本,而其他所有節點則會成為次要複本。
Always On 健全狀況偵測
Always On 資源 DLL 會監視內部 SQL Server 元件的狀態。 sp_server_diagnostics 會依 HealthCheckTimeout 所控制的間隔來回報這些 SQL Server 元件的健全狀況。 sp_server_diagnostics 會回報五個執行個體層級元件的健全狀態:系統、資源、查詢處理、IO 子系統和事件。 它也會回報每個 AG 的健全狀況。 每次更新時,資源 DLL 都會根據 AG 的失敗層級來更新 AG 資源的健全狀態。 當 sp_server_diagnostics 傳回資料時,它會顯示每個元件處於初始、警告、錯誤或不明狀態,並提供描述元件狀態的一些 XML 資料。 對於健全狀況偵測,資源 DLL 只有在元件處於錯誤狀態時,才會採取動作。
如果健全狀況偵測依間隔多次無法回報資源 DLL 的更新,則會判定 AG 狀況不良,並在呼叫 IsAlive 時回報失敗。
租用機制
不同於其他容錯移轉機制,SQL Server 執行個體在租用機制中扮演著主動的角色。 租用機制會用來作為叢集資源裝載和 SQL Server 處理序間的簡單確定資源運作驗證。 此機制會用來確認兩邊 (叢集服務和 SQL Server 服務) 都有頻繁接觸、檢查彼此的狀態,最終防止核心分裂案例。 將 AG 連線為主要複本時,SQL Server 執行個體會繁衍 AG 的專用租用背景工作執行緒。 租用背景工作會與含有租用更新和租用停止事件的資源裝載共用很小的記憶體區域。 租用背景工作和資源裝載會以循環方式發出其各自的租用更新事件訊號,然後睡眠並等候另一方發出自己的租用更新事件或停止事件訊號。 資源裝載和 SQL Server 租用執行緒都有存留時間值,每次執行緒在另一個執行緒發出信號後喚醒時,即會更新此值。 如果等候信號期間達到存留時間上限,租用會過期,然後複本會轉換成該特定 AG 的解析中狀態。 如果發出租用停止事件信號,則複本會轉換成解析中角色。
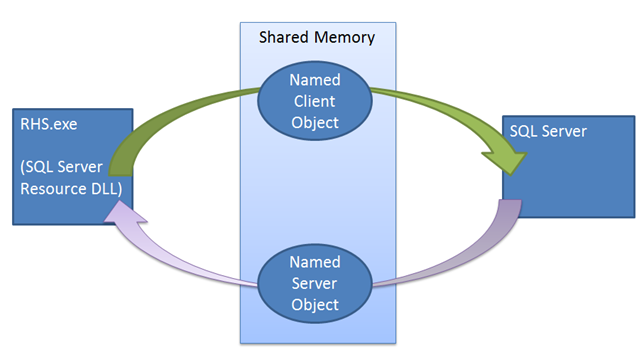
租用機制會強制在 SQL Server 與 Windows Server 容錯移轉叢集之間同步處理。 發出容錯移轉命令時,叢集服務會對目前主要複本的資源 DLL 發出 Offline 呼叫。 資源 DLL 會先嘗試使用預存程序將 AG 離線。 如果此預存程序失敗或逾時,則會對叢集服務回報失敗,然後發出終止命令。 此終止會再次嘗試執行相同的預存程序,但叢集這次不會等候資源 DLL 回報成功或失敗,就會將 AG 連線到新的複本。 如果第二個程序呼叫失敗,則資源裝載必須依賴租賃機制將執行個體離線。 呼叫資源 DLL 將 AG 離線時,資源 DLL 會發出租用停止事件信號,並喚醒 SQL Server 租用背景工作執行緒來將 AG 離線。 即使未發出此停止事件訊號,租賃仍會過期,且複本會轉換成解析中狀態。
租用基本上是主要執行個體與叢集之間的同步處理機制,但它也可以建立不需要容錯移轉的失敗狀況。 例如,高 CPU、記憶體不足的情況 (虛擬記憶體不足、處理序分頁)、SQL 處理序在產生記憶體傾印時沒有回應、系統沒有回應、叢集 (WSFC) 離線 (例如因為仲裁遺失),都可能導致從 SQL 執行個體續訂租賃失敗,並引發重新啟動或容錯移轉。
叢集逾時值方針
請謹慎考慮對 SQL Server 叢集使用較不主動的監視之權衡取捨,並了解使用後果。 增加叢集逾時值會提高暫時性網路問題的容忍度,但會使永久性失敗的反應變慢。 增加逾時來處理資源壓力或很大的地理延遲,也會增加從永久性或無法復原的失敗中復原的時間。 雖然這對許多應用程式都是可接受的,但並非在所有情況下都很理想。
預設設定已經過最佳化,可快速回應永久性失敗的徵兆並限制停機時間,但這些設定也可能對某些工作負載和組態的效果太強。 不建議將 LeaseTimeout、CrossSubnetDelay、CrossSubnetThreshold、SameSubnetDelay、SameSubnetThreshold 或 HealthCheckTimeout 的任何一個降得比其預設值還要低。 每個部署的正確設定會有所不同,而且可能需要微調久一點才能找到。 變更上述任何值時,請以漸進方式執行,並考慮這些值之間的關聯性和相依性。
叢集逾時與租用逾時之間的關聯性
租賃機制的主要功能是在叢集服務無法與執行個體通訊時,將 SQL Server 資源離線,同時執行容錯移轉至另一個節點。 當叢集在 AG 叢集資源上執行離線作業時,叢集服務會對 rhs.exe 發出 RPC 呼叫來將資源離線。 資源 DLL 使用預存程序來通知 SQL Server 將 AG 離線,但此預存程序可能會失敗或逾時。資源裝載也會在離線呼叫期間停止自己的租賃續訂執行緒。 在最壞情況下,SQL Server 會使租賃不到 ½ * LeaseTimeout 就過期,並將執行個體轉換成解析中狀態。 容錯移轉可由多方起始,但叢集狀態檢視絕對必須在叢集內與 SQL Server 執行個體之間是一致的。 例如,假設主要執行個體失去與叢集其餘部分的連線。 由於叢集逾時值,叢集中的每個節點會在類似的時間判斷失敗,但只有主要節點可以與主要 SQL Server 執行個體互動,以強制它放棄主要角色。
從主要節點的觀點來看,叢集服務會遺失仲裁,而服務會開始自行終止。 叢集服務會對資源裝載發出 RPC 呼叫來終止處理序。 此終止呼叫會負責將 SQL Server 執行個體上的 AG 離線。 此離線呼叫是透過 T-SQL 完成,但無法保證會成功建立 SQL 與資源 DLL 之間的連線。
從叢集其餘部分的觀點來看,目前沒有主要複本,因此叢集會投票並為叢集中的其餘節點建立一個新的主要複本。 如果資源 DLL 呼叫的預存程序失敗或逾時,叢集可能很容易發生核心分裂情況。
租用逾時可防止面對通訊錯誤時的核心分裂情況。 即使所有通訊失敗,資源 DLL 處理序仍會終止且無法更新租用。 一旦租賃過期,就會自行將 AG 離線。 請務必注意,在叢集建立新的主要複本之前,SQL Server 執行個體不會再裝載主要複本。 由於負責選擇新主要複本的叢集其餘部分沒有與目前主要複本協調的方法,因此逾時值可確保在目前主要複本自行離線之前,不會建立新的主要複本。
當叢集容錯移轉時,裝載舊版主要複本的 SQL Server 執行個體必須轉換成解析中狀態,新的主要複本才能連線。 任何時間點的 SQL Server 租用執行緒都會剩下 ½ * LeaseTimeout 的存留時間,因為每次更新租用,都會將新的存留時間更新為 LeaseInterval 或 ½ * LeaseTimeout。 如果叢集服務或資源裝載未發出租用停止事件信號就停止或終止,叢集會在 SameSubnetThreshold\ SameSubnetDelay 毫秒後將主要節點宣告為無法使用。 在這段期間內,租用必須過期,因此主要複本一定會離線。 由於租用逾時的最大存留時間為 ½ * LeaseTimeout,因此 ½ * LeaseTimeout 必須小於 SameSubnetThreshold * SameSubnetDelay。
所有 SQL Server 叢集的 SameSubnetThreshold \<= CrossSubnetThreshold 和 SameSubnetDelay \<= CrossSubnetDelay 都應該為 True。
健全狀況檢查逾時作業
健全狀況檢查逾時的彈性更高,因為沒有其他容錯移轉機制直接相依於它。 預設值 30 秒會將 sp_server_diagnostics 間隔設定為 10 秒,並將逾時的最小值和間隔分別設定為 15 秒和 5 秒。 但在更普遍的情況下,sp_server_diagnostics 更新間隔一律為 1/3 * HealthCheckTimeout。 當資源 DLL 隔一段時間未收到一組新的健康情況資料時,它會繼續使用先前間隔中的健康情況資料,來判斷目前的 AG 和執行個體健康情況。 增加健康情況檢查逾時值會提高主要複本對 CPU 壓力的容忍度,但可能會使 sp_server_diagnostics 無法每隔一段時間就提供新的資料,而會更長時間依賴過期的資料健康情況檢查。 不論逾時值為何,一旦收到資料指出複本狀況不良,下一個 IsAlive 呼叫就會會傳回執行個體狀況不良,且叢集服務會起始容錯移轉。
AG 的失敗狀況層級會變更健全狀況檢查的失敗狀況。 針對任何失敗層級,如果 sp_server_diagnostics 回報 AG 元素狀況不良,則健康情況檢查將會失敗。 每個層級會繼承其下方層級的所有失敗狀況。
| 層級 | 將執行個體視為無法使用的狀況 |
|---|---|
| 1:OnServerDown | 如果 AG 以外的任何資源失敗,健全狀況檢查不會採取任何動作。 如果在 5 次間隔或 5/3 * HealthCheckTimeout 內未收到 AG 資料 |
| 2:OnServerUnresponsive | 如果在 HealthCheckTimeout 內 sp_server_diagnostics 未收到任何資料 |
| 3:OnCriticalServerError | (預設) 如果系統元件回報錯誤 |
| 4:OnModerateServerError | 如果資源元件回報錯誤 |
| 5:OnAnyQualifiedFailureConitions | 如果查詢處理元件回報錯誤 |
更新叢集和 Always On 逾時值
叢集值
WSFC 組態中有四個值,負責決定叢集逾時值:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
延遲值會決定叢集服務活動訊號之間的等候時間,而閾值會設定從目標節點或資源未收到任何認可的活動訊號數目,之後叢集會將物件宣告為無法使用。 如果相同子網路中的節點之間沒有成功的活動訊號超過 SameSubnetDelay \* SameSubnetThreshold 毫秒,則會判定節點無法使用。 這也適用於使用跨子網路值的跨子網路通訊。
若要列出所有目前的叢集值,請在目標叢集中的任何節點上,開啟提升權限的 PowerShell 終端機。 執行以下命令:
Get-Cluster | fl *
若要更新任何值,請在提升權限的 PowerShell 終端機中執行下列命令:
(Get-Cluster).<ValueName> = <NewValue>
增加延遲 * 閾值乘積來提高叢集逾時的容忍度時,先增加延遲值再增加閾值,會比較有效。 藉由增加延遲,就會增加每個活動訊號的間隔時間。 活動訊號的間隔時間越長,就能讓暫時性網路問題有越多時間自行解決,而且會降低與同一期間傳送更多活動訊號有關的網路壅塞情況。
租用逾時
租用機制是由 WSFC 叢集中每個 AG 的單一特定值所控制。 租賃逾時可能會導致下列錯誤:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
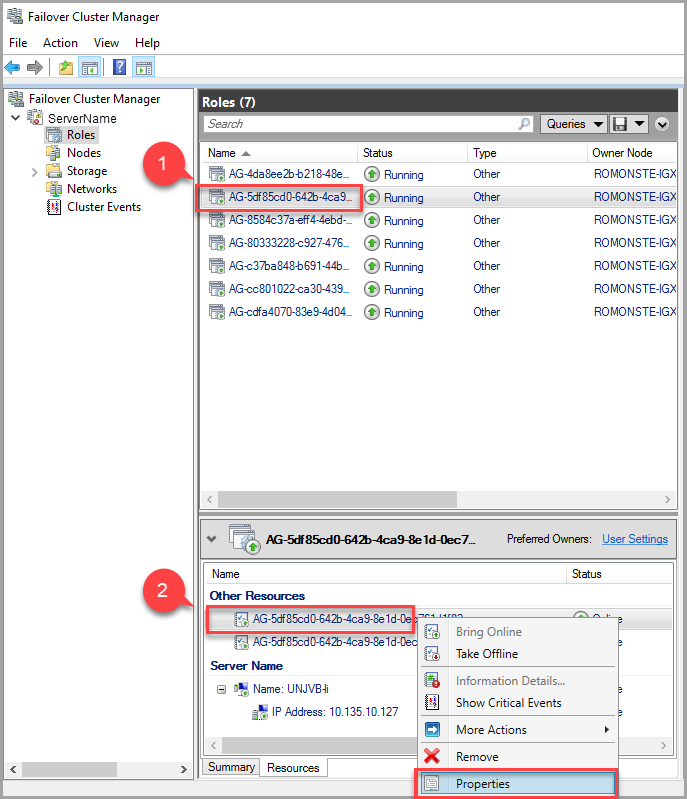
若要修改租用逾時值,請使用容錯移轉叢集管理員並遵循下列步驟:
在 [角色] 索引標籤中,尋找目標 AG 角色。 選取目標 AG 角色。
以滑鼠右鍵按一下視窗底部的 AG 資源,然後選取 [內容] 。
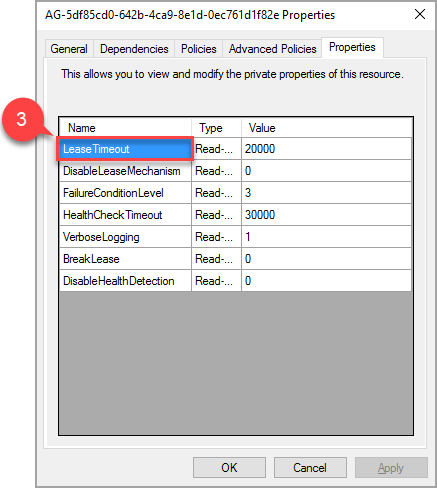
在快顯視窗中,巡覽至 [內容] 索引標籤,以檢視此 AG 的特定值清單。 選取 LeaseTimeout 值加以變更。
根據 AG 的設定,可能會有接聽程式、共用磁碟、檔案共用等其他資源,這些資源不需要任何額外設定。
注意
屬性 'LeaseTimeout' 的新值會在資源離線後並再次上線時生效。
健康情況檢查值
控制 Always On 健全狀況檢查的兩個值:FailureConditionLevel 和 HealthCheckTimeout。 FailureConditionLevel 會指出 sp_server_diagnostics 所回報之特定失敗狀況的容忍度,而 HealthCheckTimeout 會設定資源 DLL 未從 sp_server_diagnostics 收到更新可執行的時間。 sp_server_diagnostics 的更新間隔一律為 HealthCheckTimeout / 3。
若要設定容錯移轉狀況層級,請使用 CREATE 或 ALTER AVAILABILITY GROUP 陳述式的 FAILURE_CONDITION_LEVEL = <n> 選項,其中 <n> 是介於 1 到 5 之間的整數。 下列命令會將 AG 'AG1' 的失敗狀況層級設為 1:
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
若要設定健康情況檢查逾時,請使用 CREATE 或 ALTER AVAILABILITY GROUP 陳述式的 HEALTH_CHECK_TIMEOUT 選項。 下列命令會將 AG AG1 的健全狀況檢查逾時設定為 60,000 毫秒:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
逾時方針摘要
不建議將任何逾時值降得比其預設值低。
租用間隔 (½ * LeaseTimeout) 必須小於 SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| 逾時設定 | 目的 | 介於 | 使用 | IsAlive LooksAlive | 原因 | 成果 |
|---|---|---|---|---|---|---|
| 租用逾時 預設:20000 |
防止核心分裂 | 主要至叢集 (HADR) |
Windows 事件物件 | 用於兩者 | OS 沒有回應、虛擬記憶體不足、工作集分頁、正在產生傾印、限制的 CPU、WSFC 關閉 (遺失仲裁) | AG 資源離線/連線、容錯移轉 |
| 工作階段逾時 預設:10000 |
通知主要與次要之間發生通訊問題 | 次要至主要 (HADR) |
TCP 通訊端 (透過 DBM 端點傳送訊息) | 不用於兩者 | 網路通訊, 次要相關問題 - 關閉、OS 沒有回應、資源爭用 |
次要 - 已中斷連線 |
| 健康情況檢查逾時 預設:30000 |
表示嘗試判斷主要複本健全狀況時逾時 | 叢集至主要 (FCI 和 HADR) |
T-SQL sp_server_diagnostics | 用於兩者 | 符合失敗條件、OS 沒有回應、虛擬記憶體不足、修剪工作集、正在產生傾印、WSFC (遺失仲裁)、排程器問題 (鎖死的排程器) | AG 資源離線/連線或容錯移轉、FCI 重新啟動/容錯移轉 |