Deploy HDFS name node and shared Spark services in a highly available configuration
Applies to: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
The Microsoft SQL Server 2019 Big Data Clusters add-on will be retired. Support for SQL Server 2019 Big Data Clusters will end on February 28, 2025. All existing users of SQL Server 2019 with Software Assurance will be fully supported on the platform and the software will continue to be maintained through SQL Server cumulative updates until that time. For more information, see the announcement blog post and Big data options on the Microsoft SQL Server platform.
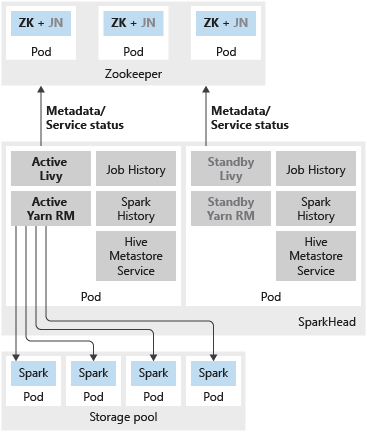
In addition to deploying SQL Server master instance in a highly available configuration using availability groups, you can deploy other mission critical services in the big data cluster to ensure an increased level of reliability. You can configure HDFS name node and the shared Spark services grouped under sparkhead with an additional replica. In this case, Zookeeper is also deployed in the big data cluster to server as cluster coordinator and metadata store for following services:
- HDFS name node
- Livy and Yarn Resource Manager.
Spark History, Job History, and Hive metadata service are stateless services. Zookeeper is not involved in ensuring the service health for these components.
Deploying multiple replicas for these services results in enhanced scalability, reliability, and load balancing of the workloads between the available replicas.
Note
The following services are deployed as containers in the sparkhead pod:
- Livy
- Yarn Resource Manager
- Spark History
- Job History
- Hive metadata service
The following image shows a spark HA deployment in a SQL Server Big Data Cluster:
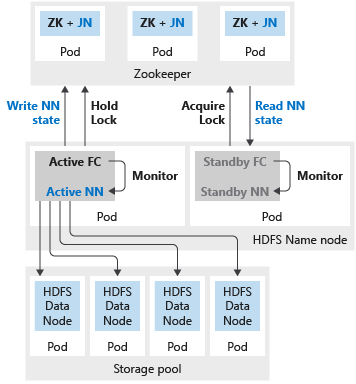
The following image shows an HDFS HA deployment in a SQL Server Big Data Cluster:
Deploy
If either name node or spark head is configured with two replicas, then you must also configure the Zookeeper resource with three replicas. In a highly available configuration for HDFS name node, two pods host the two replicas. Th pods are nmnode-0 and nmnode-1. This configuration is active-passive. Only one of the name nodes is active at a time. The other is in stand-by - it becomes active as a result of a failover event.
You can use either the aks-dev-test-ha or the kubeadm-prod built-in configuration profiles to start customizing your big data cluster deployment. These profiles include the settings required for resources you can configure additional high availability. For example, below is a section in the bdc.json configuration file that is relevant for deploying HDFS name node, Zookeeper and shared Spark resources (sparkhead) with high availability.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
As a best practice, in a production deployment, you must also configure HDFS block replication to 3. This setting is already specified in the aks-dev-test-ha and kubeadm-prod profiles. See below section from bdc.json configuration file:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Known limitations
The known issues and limitations with configuring high availability for the Hadoop services in SQL Server Big Data Clusters include:
- All configurations must be specified at the time of the big data cluster deployment. With SQL Server 2019 CU1 release, you cannot enable the high availability configuration after deployment.
Next steps
- For more information about using configuration files in big data cluster deployments, see How to deploy SQL Server Big Data Clusters on Kubernetes.
- For more information about SQL Server master high availability options in big data clusters, see Deploy SQL Server master instance with high availability topic.