使用 Azure Data Studio 連線到 SQL Server 巨量資料叢集
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
本文描述如何從 Azure Data Studio 連線到 SQL Server 2019 巨量資料叢集。
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章和 Microsoft SQL Server 平台上的巨量資料選項。
Prerequisites
- 已部署的 SQL Server 2019 巨量資料叢集。
- SQL Server 2019 巨量資料工具:
- Azure Data Studio
- SQL Server 2019 延伸模組
- kubectl
- azdata
連線至叢集
若要使用 Azure Data Studio 連線到巨量資料叢集,請建立與叢集中 SQL Server 主要執行個體的新連線。 方法如下。
尋找 SQL Server 主要執行個體端點:
azdata bdc endpoint list -e sql-server-master提示
如需如何取得端點的詳細資訊,請參閱擷取端點。
在 Azure Data Studio 中,按 F1 鍵>[新增連線] 。
在 [連線類型] 中,選取 [Microsoft SQL Server] 。
在 [伺服器名稱] 文字方塊中,鍵入在 SQL Server 主要執行個體找到的端點名稱 (例如:<IP_Address>,31433)。
選擇您的驗證類型。 針對在大型資料叢集中執行的 SQL Server 主要執行個體,僅支援 Windows 驗證 和 SQL 登入。
如果使用 SQL 登入,請輸入您的 SQL 登入使用者名稱和密碼。
提示
根據預設,在巨量資料叢集部署期間,將會停用 SA 使用者名稱。 部署期間會佈建一個新的系統管理員使用者,其名稱與密碼會與 AZDATA_USERNAME和 AZDATA_PASSWORD 環境變數相對應,並且會在部署之前或部署期間設定。
將目標資料庫名稱變更為您的關聯式資料庫之一。
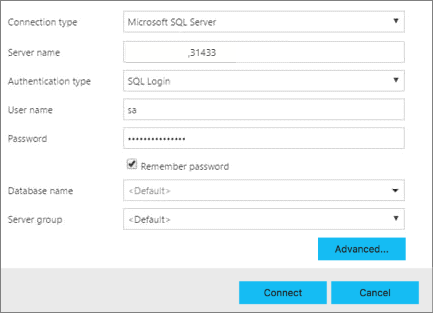
按下 [連線] ,伺服器儀表板應該會隨即出現。
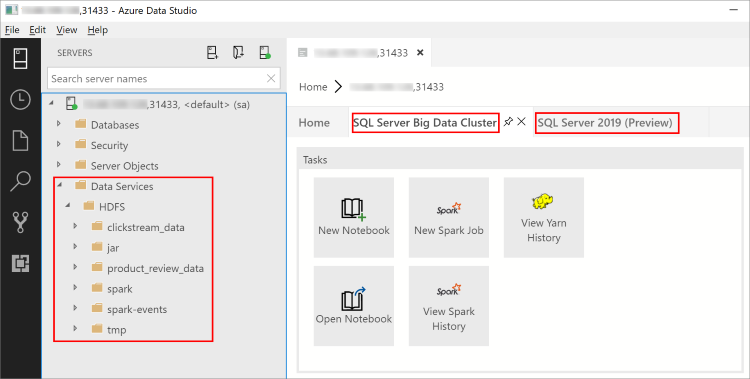
在 2019 年 2 月版的 Azure Data Studio 中,連線到 SQL Server 主要執行個體也可讓您與 HDFS/Spark 閘道互動。 這表示您不需要對 HDFS 和 Spark 使用個別連線 (如下一節所述)。
物件總管現在包含新的 [資料服務] 節點,按一下滑鼠右鍵可取得巨量資料叢集工作的支援,例如建立新的筆記本或提交 Spark 作業。
資料服務 節點也包含 HDFS 資料夾,可讓您探索 HDFS 的內容及執行牽涉到 HDFS 的一般工作,例如,建立外部資料表或開啟筆記本來分析 HDFS 內容。
安裝延伸模組之後,連線的伺服器儀表板也會包含 [SQL Server 巨量資料叢集] 和 [SQL Server 2019] 索引標籤。
下一步
如需 SQL Server 2019 巨量資料叢集的詳細資訊,請參閱什麼是 SQL Server 2019 巨量資料叢集。