SQL Server 巨量資料叢集中的存放集區簡介
適用於:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
本文說明 SQL Server 巨量資料叢集中的「SQL Server 存放集區」角色。 下列各節說明存放集區的架構和功能。
重要
Microsoft SQL Server 2019 巨量資料叢集附加元件將會淘汰。 SQL Server 2019 巨量資料叢集的支援將於 2025 年 2 月 28 日結束。 平台上將完全支援含軟體保證 SQL Server 2019 的所有現有使用者,而且軟體將會持續透過 SQL Server 累積更新來維護,直到該時間為止。 如需詳細資訊,請參閱公告部落格文章 \(英文\) 與 Microsoft SQL Server 平台上的巨量資料選項。
存放集區架構
存放集區是 SQL Server 巨量資料叢集中的本機 HDFS (Hadoop) 叢集。 其提供非結構化與半結構化資料的永續性儲存體。 資料檔案 (例如 Parquet 或分隔的文字) 可以儲存在存放集區中。 集區中的每個 Pod 都要附加永久性磁碟區,才能讓儲存體變成永久性。 存放集區檔案可以透過 SQL Server 使用 PolyBase 或直接使用 Apache Knox Gateway 來存取。
傳統 HDFS 設定是由一組已附加存放裝置的商用硬體電腦所組成。 資料會分散在各個節點的區塊中,以供容錯及平行處理用途使用。 叢集中某一個節點會當作名稱節點使用,並包含資料節點中的檔案中繼資料資訊。
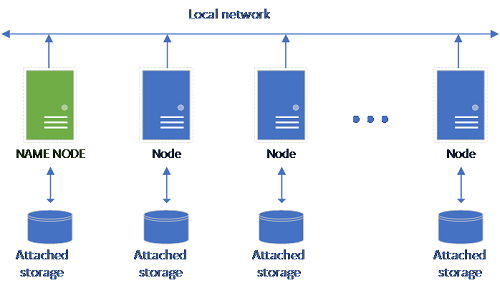
存放集區是由屬於 HDFS 叢集成員的儲存體節點所組成。 其會使用裝載下列容器的每個 Pod 來執行一或多個 Kubernetes Pod:
- 連結至永久性磁碟區 (儲存體) 的 Hadoop 容器。 此類型的所有容器會共同形成 Hadoop 叢集。 在 Hadoop 容器內是一個 YARN 節點管理員處理序,可以建立隨選 Apache Spark 背景工作處理序。 Spark 前端節點會裝載 Hive 中繼存放區、Spark 歷程記錄與 YARN 作業歷程記錄容器。
- 使用 OpenRowSet 技術從 HDFS 讀取資料的 SQL Server 執行個體。
collectd用於收集計量資料。fluentbit用於收集計量資料。
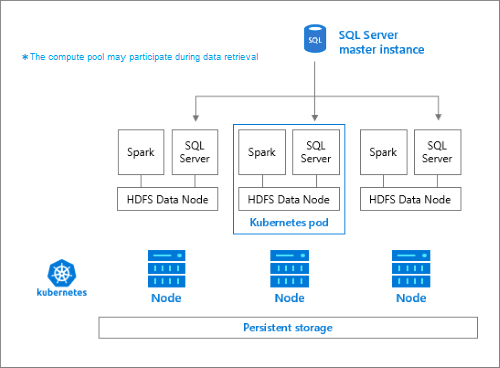
職責
存放裝置節點負責:
- 透過 Apache Spark 的資料擷取。
- HDFS 中的資料儲存區 (Parquet 和分隔符號文字格式)。 HDFS 也提供資料持續性,因為 HDFS 資料會散佈到 SQL BDC 中的所有存放裝置節點。
- 透過 HDFS 和 SQL Server 端點的資料存取。
存取資料
存取存放集區中資料的主要方法如下:
- Spark 作業。
- SQL Server 外部資料表允許使用 PolyBase 計算節點與在 HDFS 節點中執行的 SQL Server 執行個體來查詢資料的使用率。
您也可以使用下列項目來與 HDFS 互動:
- Azure Data Studio。
- Azure Data CLI (
azdata)。 - kubectl 以向 Hadoop 容器發出命令。
- HDFS http 閘道。
後續步驟
若要深入了解 SQL Server 巨量資料叢集,請參閱下列資源: