將資料模型串行化到不同存放區或從不同存放區進行串行化 (預覽)
為了讓數據模型儲存在資料庫中,它必須轉換成資料庫可以理解的格式。 不同的資料庫需要不同的記憶體架構和格式。 有些有一些需要遵守的嚴格架構,有些則允許使用者定義架構。
映射選項
Semantic Kernel 提供的向量存儲庫連接器提供多種方式來達成此對應。
內建對應器
Semantic Kernel 提供的向量資料庫連接器具有內建對應器,能將您的數據模型與資料庫架構之間進行對應。 如需了解內建映射器如何為每個資料庫映射數據的詳細資訊,請參閱每個連接器的 頁面。
自訂映射器
Semantic Kernel 所提供的向量存放區(vector store)連接器支援以 VectorStoreRecordDefinition搭配提供自定義對應器的功能。 在此情況下,VectorStoreRecordDefinition 可能與所提供的數據模型不同。
VectorStoreRecordDefinition 可用來定義資料庫架構,而數據模型則由開發人員用來與向量存放區互動。
在此情況下,需要自定義對應程式,才能從數據模型對應至 VectorStoreRecordDefinition所定義的自定義資料庫架構。
提示
如需建立您自己的自訂映射器的範例,請參閱 如何為 Vector Store 連接器建置自訂映射器。
為了讓數據模型定義為 類別 或 要儲存在資料庫中的定義 ,它必須串行化為資料庫可以理解的格式。
有兩種方式可以完成,使用語意核心所提供的內建串行化,或提供您自己的串行化邏輯。
下列兩個圖表顯示數據模型與存放區模型之間的串行化和反序列化流程。
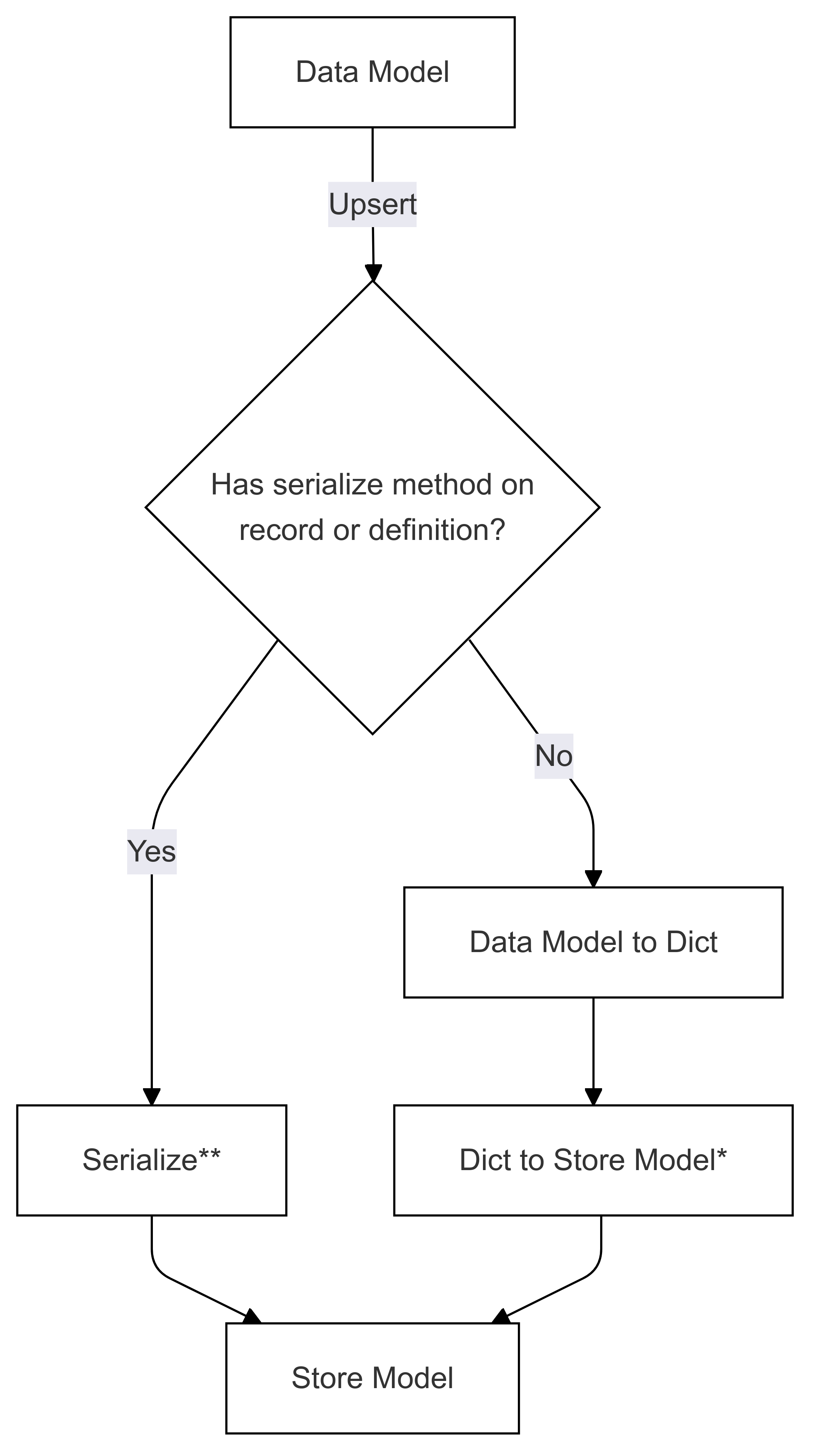
串行化流程(用於 Upsert)
反序列化流程(用於取得和搜尋)
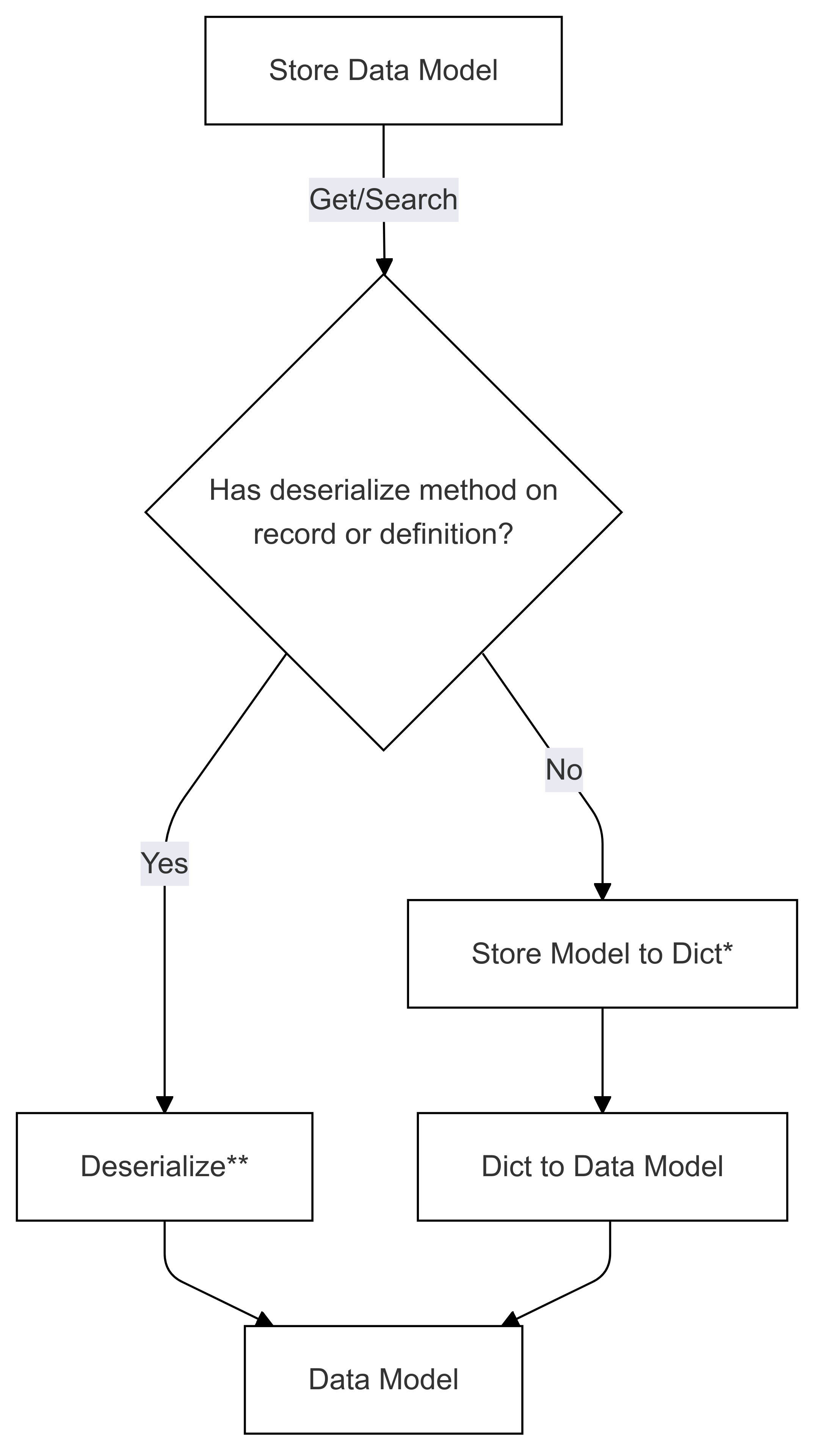
標示為 * 的步驟是由特定連接器的開發人員所實作,而且每個商店都不同。 標示為 **(在這兩個圖表中)的步驟會以記錄上的方法或記錄定義的一部分提供,這一律由使用者提供,如需詳細資訊,請參閱 直接串行化。
(反)序列化方法
直接序列化(從資料模型到存儲模型)
直接串行化是確保完整控制模型如何串行化及優化效能的最佳方式。 缺點是,它是數據存放區特有的,因此使用這個數據存放區時,在具有相同數據模型的不同存放區之間切換並不容易。
您可以在數據模型中實作遵循 SerializeMethodProtocol 通訊協定的方法,或是將遵循 SerializeFunctionProtocol 的函式新增至記錄定義,這兩種方法都可以在 semantic_kernel/data/vector_store_model_protocols.py中找到。
當其中一個函式存在時,它會用來將數據模型直接串行化至存放區模型。
您甚至可以只實作其中一個,並針對另一個方向使用內建的序列化/反序列化。這在處理一個非您所控制的集合時可能很有用,尤其當您需要對反序列化的方式進行一些自定義時(而且無法執行更新插入操作)。
內建的序列化與反序列化(數據模型到字典及字典到儲存模型,反之亦然)
內建串行化會先將數據模型轉換成字典,然後將它串行化為儲存瞭解的每個存放區,並定義為內建連接器的一部分。 還原串行化是以反向順序完成。
序列化步驟 1:資料模型轉換為字典。
視您擁有的數據模型類型而定,這些步驟會以不同的方式完成。 有四種方式會嘗試將數據模型串行化為字典:
- 定義上的
to_dict方法(與數據模型的 to_dict 屬性對齊,並遵循ToDictFunctionProtocol) - 檢查記錄是否為
ToDictMethodProtocol,並使用to_dict方法 - 檢查記錄是否為 Pydantic 模型,並使用模型中的
model_dump,如需更多詳情,請參閱下方附註。 - 迴圈查看定義中的欄位,並建立字典
串行化步驟 2:聽寫以儲存模型
連接器必須提供方法,才能將字典轉換成存放區模型。 這是由連接器的開發人員所完成,而且每個商店都不同。
還原串行化步驟 1:將模型儲存至字典
連接器必須提供一種方法,以將儲存模型轉換為字典。 這是由連接器的開發人員所完成,而且每個商店都不同。
還原串行化步驟 2:對數據模型的聽寫
反序列化是按逆向順序完成的,會嘗試以下選項:
- 定義中的
from_dict方法(對應數據模型的 from_dict 屬性,遵循FromDictFunctionProtocol) - 檢查記錄是否為
FromDictMethodProtocol,並使用from_dict方法 - 檢查該記錄是否為 Pydantic 模型,並使用模型的
model_validate,詳情請參考下方說明。 - 遍歷定義中的欄位並設定值,然後將這個字典傳遞至數據模型的建構函式作為具名參數(除非數據模型本身是字典,在此情況下將原樣返回)
注意
使用 Pydantic 進行內建序列化
當您使用 Pydantic BaseModel 定義模型時,它會使用 model_dump 和 model_validate 方法來串行化和還原串行化數據模型到聽寫和還原串行化。 這項操作是通過不帶任何參數使用 model_dump 方法來完成的。如果你想要控制這一點,請考慮在數據模型上實作 ToDictMethodProtocol,因為會首先嘗試這一點。
向量串行化
當您的資料模型中有向量時,它必須是浮點數清單或 ints 清單,因為這是大部分存放區所需的,如果您想要讓類別以不同的格式儲存向量,您可以使用 serialize_function 註釋中deserialize_function定義的 和 VectorStoreRecordVectorField 。 例如,對於 numpy 陣列,您可以使用下列註釋:
import numpy as np
vector: Annotated[
np.ndarray | None,
VectorStoreRecordVectorField(
dimensions=1536,
serialize_function=np.ndarray.tolist,
deserialize_function=np.array,
),
] = None
如果您使用可以處理原生 numpy 陣列的向量存放區,而且您不想來回轉換它們,您應該設定模型和該存放區的直接串行化和還原串行化 方法
注意
只有在使用內建序列化時才會使用此方法,而在使用直接序列化時,您可以以任何方式處理向量。
即將推出
更多信息即將推出。