Known issues in Machine Learning Server
Important
This content is being retired and may not be updated in the future. The support for Machine Learning Server will end on July 1, 2022. For more information, see What's happening to Machine Learning Server?
The following issues are known in the 9.4 release.
Known issues in 9.4
1. Missing azure-ml-admin-cli extension on DSVM environments
If for some reason your azure-ml-admin-cli extension is not available or has been removed, you will be met with the following error:
# With elevated privileges, run the following commands.
$ az mlserver admin --help
az: error: argument _command_package: invalid choice: mlserver
usage: az [-h] [--verbose] [--debug] [--output {tsv,table,json,jsonc}]
[--query JMESPATH]
{aks,backup,redis,network,cosmosdb,batch,iot,dla,group,webapp,acr,dls,
storage,mysql,vm,reservations,account,keyvault,sql,vmss,eventgrid,
managedapp,ad,advisor,postgres,container,policy,lab,batchai,
functionapp,identity,role,cognitiveservices,monitor,sf,resource,cdn,
tag,feedback,snapshot,disk,extension,acs,provider,cloud,lock,image,
find,billing,appservice,login,consumption,feature,logout,configure,
interactive}
If you encounter this error, you can re-add the extension as such:
Windows:
$ az extension add --source "C:\Program Files\Microsoft\ML Server\Setup\azure_ml_admin_cli-0.0.1-py2.py3-none-any.whl" --yes
Linux:
az extension add --source /opt/microsoft/mlserver/9.4.7/o16n/azure_ml_admin_cli-0.0.1-py2.py3-none-any.whl --yes
2. Compute nodes fail on a Python-only install on Ubuntu 14.04
This issue applies to both 9.3 and 9.2.1 installations. On an Ubuntu 14.04 installation of a Python-only Machine Learning Server configured for operationalization, the compute node eventually fails. For example, if you run diagnostics, the script fails with "BackEndBusy Exception".
To work around this issue, comment out the stop service entry in the config file:
- On the compute node, edit the /etc/init/computenode.service file.
- Comment out the command: "stop on stopping rserve" by inserting # at beginning of the line.
- Restart the compute node:
az ml admin node start --computenode
For more information on service restarts, see Monitor, stop, and start web & compute nodes.
3. ImportError for Matplotlib.pyplot
This is a known Anaconda issue not specific to Machine Learning Server, but Matplotlib.pyplot fails to load on some systems. Since using Matplotlib.pyplot with revoscalepy is a common scenario, we recommend the following workaround if you are blocked by an import error. The workaround is to assign a non-interactive backend to matplotlib prior to loading pyplot:
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
For more information, search for "Agg backend" in the Matplotlib FAQ.
4. Model deserialization on older remote servers
Applies to: rxSerializeModel (RevoScaleR), referencing "Error in memDecompress(data, type = decompress)"
If you customarily switch the compute context among multiple machines, you might have trouble deserializing a model if the RevoScaleR library is out of sync. Specifically, if you serialized the model on a newer client, and then attempt deserialization on a remote server having older copies of those libraries, you might encounter this error:
"Error in memDecompress(data, type = decompress) :
internal error -3 in memDecompress(2)"
To deserialize the model, switch to a newer server or consider upgrading the older remote server. As a best practice, it helps when all servers and client apps are at the same functional level.
5. azureml-model-management-sdk only supports up to 3 arguments as the input of the web service
When consuming the web services using python, sending multiple variables (more than three) as inputs of consume() or the alias function is returning KeyError or TypeError. Alternative: use DataFrames as the input type.
# example:
def func(Age, Gender, Height, Weight):
pred = mod.predict(Age, Gender, Height, Weight)
return pred
#error 1:
service.consume(Age = 25.0, Gender = 1.0, Height = 180.0, Weight = 200.0)
#--------------------------------------------------------------------------------------------
#TypeError: consume() got multiple values for argument 'Weight'
#--------------------------------------------------------------------------------------------
#error 2:
service.consume(25.0, 1.0, 180.0, 200.0)
#--------------------------------------------------------------------------------------------
#KeyError: 'weight'
#--------------------------------------------------------------------------------------------
#workaround:
def func(inputDatf):
features = ['Age', 'Gender', 'Height', 'Weight']
inputDatf = inputDatf[features]
pred = mod.predict(inputDatf)
inputDatf['predicted']=pred
outputDatf = inputDatf
return outputDatf
service = client.service(service_name)\
.version('1.0')\
.code_fn(func)\
.inputs(inputDatf=pd.DataFrame)\
.outputs(outputDatf=pd.DataFrame)\
.models(mod=mod)\
.description('Calories python model')\
.deploy()
res=service.consume(pd.DataFrame({ 'Age':[1], 'Gender':[2], 'Height':[3], 'Weight':[4] }))
6. Python 3 Kernel error when using Jupyter Notebooks and Python Client 9.4.7
A Python 3 Kernel error may occur when using Jupyter Notebooks for Microsoft Machine Learning Server with ML Python Client 9.4.7.
For example:
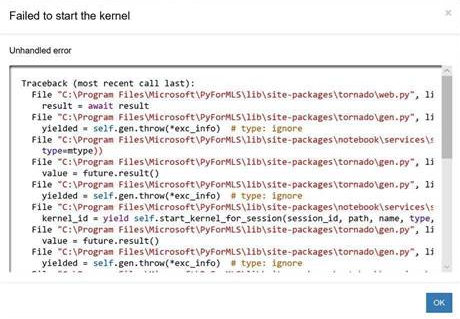
The workaround is to edit the file C:\Program Files\Microsoft\PyForMLS\share\jupyter\kernels\python3\kernel.json and replace all the contents with the following:
{
"display_name": "Python 3",
"language": "python",
"argv": [
"C:\\Program Files\\Microsoft\\PyForMLS\\python.exe",
"-m",
"ipykernel_launcher",
"-f",
"{connection_file}"
]
}
The file paths of kernel.json and python.exe may be different if the client was installed to a different folder.
Previous releases
This document also describes the known issues for the last several releases:
- Known issues for 9.3
- Known issues for 9.2.1
- Known issues for 9.1.0
- Known issues for 9.0.1
- Known issues for 8.0.5
Machine Learning Server 9.3
1. Missing azure-ml-admin-cli extension on DSVM environments
If for some reason your azure-ml-admin-cli extension is not available or has been removed, you will be met with the following error:
# With elevated privileges, run the following commands.
$ az ml admin --help
az: error: argument _command_package: invalid choice: ml
usage: az [-h] [--verbose] [--debug] [--output {tsv,table,json,jsonc}]
[--query JMESPATH]
{aks,backup,redis,network,cosmosdb,batch,iot,dla,group,webapp,acr,dls,
storage,mysql,vm,reservations,account,keyvault,sql,vmss,eventgrid,
managedapp,ad,advisor,postgres,container,policy,lab,batchai,
functionapp,identity,role,cognitiveservices,monitor,sf,resource,cdn,
tag,feedback,snapshot,disk,extension,acs,provider,cloud,lock,image,
find,billing,appservice,login,consumption,feature,logout,configure,
interactive}
If you encounter this error, you can re-add the extension as such:
Windows:
$ az extension add --source 'C:\Program Files\Microsoft\ML Server\Setup\azure_ml_admin_cli-0.0.1-py2.py3-none-any. whl' --yes
Linux:
az extension add --source /opt/microsoft/mlserver/9.3.0/o16n/azure_ml_admin_cli-0.0.1-py2.py3-none-any.whl --yes
2. Compute nodes fail on a Python-only install on Ubuntu 14.04
This issue applies to both 9.3 and 9.2.1 installations. On an Ubuntu 14.04 installation of a Python-only Machine Learning Server configured for operationalization, the compute node eventually fails. For example, if you run diagnostics, the script fails with "BackEndBusy Exception".
To work around this issue, comment out the stop service entry in the config file:
- On the compute node, edit the /etc/init/computenode.service file.
- Comment out the command: "stop on stopping rserve" by inserting # at beginning of the line.
- Restart the compute node:
az ml admin node start --computenode
For more information on service restarts, see Monitor, stop, and start web & compute nodes.
3. ImportError for Matplotlib.pyplot
This is a known Anaconda issue not specific to Machine Learning Server, but Matplotlib.pyplot fails to load on some systems. Since using Matplotlib.pyplot with revoscalepy is a common scenario, we recommend the following workaround if you are blocked by an import error. The workaround is to assign a non-interactive backend to matplotlib prior to loading pyplot:
import matplotlib as mpl
mpl.use('Agg')
import matplotlib.pyplot as plt
For more information, search for "Agg backend" in the Matplotlib FAQ.
4. Model deserialization on older remote servers
Applies to: rxSerializeModel (RevoScaleR), referencing "Error in memDecompress(data, type = decompress)"
If you customarily switch the compute context among multiple machines, you might have trouble deserializing a model if the RevoScaleR library is out of sync. Specifically, if you serialized the model on a newer client, and then attempt deserialization on a remote server having older copies of those libraries, you might encounter this error:
"Error in memDecompress(data, type = decompress) :
internal error -3 in memDecompress(2)"
To deserialize the model, switch to a newer server or consider upgrading the older remote server. As a best practice, it helps when all servers and client apps are at the same functional level.
5. azureml-model-management-sdk only supports up to 3 arguments as the input of the web service
When consuming the web services using python, sending multiple variables (more than three) as inputs of consume() or the alias function is returning KeyError or TypeError. Alternative: use DataFrames as the input type.
# example:
def func(Age, Gender, Height, Weight):
pred = mod.predict(Age, Gender, Height, Weight)
return pred
#error 1:
service.consume(Age = 25.0, Gender = 1.0, Height = 180.0, Weight = 200.0)
#--------------------------------------------------------------------------------------------
#TypeError: consume() got multiple values for argument 'Weight'
#--------------------------------------------------------------------------------------------
#error 2:
service.consume(25.0, 1.0, 180.0, 200.0)
#--------------------------------------------------------------------------------------------
#KeyError: 'weight'
#--------------------------------------------------------------------------------------------
#workaround:
def func(inputDatf):
features = ['Age', 'Gender', 'Height', 'Weight']
inputDatf = inputDatf[features]
pred = mod.predict(inputDatf)
inputDatf['predicted']=pred
outputDatf = inputDatf
return outputDatf
service = client.service(service_name)\
.version('1.0')\
.code_fn(func)\
.inputs(inputDatf=pd.DataFrame)\
.outputs(outputDatf=pd.DataFrame)\
.models(mod=mod)\
.description('Calories python model')\
.deploy()
res=service.consume(pd.DataFrame({ 'Age':[1], 'Gender':[2], 'Height':[3], 'Weight':[4] }))
Machine Learning Server 9.2.1
The following issues are known in this release:
- Configure Machine Learning Server web node warning: "Web Node was not able to start because it is not configured."
- Client certificate is ignored when the Subject or Issue is blank.
- Web node connection to compute node times out during a batch execution.
Note
Other release-specific pages include What's New in 9.2.1 and Deprecated and Discontinued Features. For known issues in the previous releases, see Previous Releases.
1. Configure Machine Learning Server web node warning: "Web Node was not able to start because it is not configured."
When configuring your web node, you might see the following message: "Web Node was not able to start because it is not configured." Typically, this is not really an issue since the web node is automatically restarted within 5 minutes by an auto-recovery mechanism. After five minutes, run the diagnostics.
2. Client certificate is ignored when the Subject or Issue is blank.
If you are using a client certificate, both the Subject AND Issuer need to be set to a value in order for the certificate to be used. If any of those is not set, the certificate settings are ignored without warning.
3. Web node connection to compute node times out during a batch execution.
If you are consuming a long-running web service via batch mode, you may encounter a connection timeout between the web and compute node. In batch executions, if a web service is still running after 10 minutes, the connection from the web node to the compute node times out. The web node then starts another session on another compute node or shell. The initial shell that was running when the connection timed out continues to run but never returns a result.
The workaround to bypass the timeout is to modify the web node appsetting.json file.
Change the field "ConnectionTimeout" under the "ComputeNodesConfiguration" section. The default value is "01:00:00", which is one hour.
Add a new field "BatchExecutionCheckoutTimeSpan" at the base level of the json file. For example:
"MaxNumberOfThreadsPerBatchExecution": 100, "BatchExecutionCheckoutTimeSpan": "03:00:00",
The value of "BatchExecutionCheckoutTimeSpan" and "ConnectionTimeout" should be set to same value. If both web and compute nodes are on the same machine (a one-box configuration) or on the same virtual network, then the "ConnectionTimeout" can be shorter because there is minimal latency.
To reduce the risk of timeouts, we recommend same-machine or same-network deployments. On Azure, you can set these up easily using a template. For more information, see Configure Machine Learning Server using Resource Manager templates.
Microsoft R Server 9.1.0
- RevoScaleR: rxMerge() behaviors in RxSpark compute context
- RevoScaleR: rxExecBy() terminates unexpectedly when NA values do not have a factor level
- MicrosoftML error: "Transform pipeline 0 contains transforms that do not implement IRowToRowMapper"
- Spark compute context: modelCount=1 does not work with rxTextData
- Cloudera: "install_mrs_parcel.py" does not exist
- Cloudera: Connection error due to libjvm and libhdfs package dependencies
- Long delays when consuming web service on Spark
Other release-specific pages include What's New in 9.1 and Deprecated and Discontinued Features. For known issues in the 9.0.1 or 8.0.5 releases, see Previous Releases.
1. rxMerge() behaviors in RxSpark compute context
Applies to: RevoScaleR package > rxMerge function
In comparison with the local compute context, rxMerge() used in a RxSpark compute context has slightly different behaviors:
- NULL return value.
- Column order may be different.
- Factor columns may be written as character type.
- In a local compute context, duplicate column names are made unique by adding “.”, plus the extensions provided by the user via the duplicateVarExt parameter (for example “Visibility.Origin”). In an RxSpark compute context, the “.” is omitted.
2. rxExecBy() terminates unexpectedly when NA values do not have a factor level
Applies to: RevoScaleR package > rxExecBy function
R script using rxExecBy suddenly aborts when the data set presents factor columns containing NA values, and NA is not a factor level. For example, consider a variable for Gender with three factor levels: Female, Male, Unknown. If an existing value is not represented by one of the factors, the function fails.
There are two possible workarounds:
- Option 1: Add an 'NA' level using addNA() to catch the "not applicable" case.
- Option 2: Clean the input dataset (remove the NA values).
Pseudo code for the first option might be:
> dat$Gender = addNA(dat$Gender)
Output would now include a fourth factor level called NA that would catch all values not covered by the other factors:
> rxGetInfo(dat, getVarInfo = TRUE)
Data frame: dat
Number of observations: 97
Number of variables: 1
Variable information:
Var 1: Gender
4 factor levels: Female Male Unknown NA
3. MicrosoftML error: "Transform pipeline 0 contains transforms that do not implement IRowToRowMapper"
Applies to: MicrosoftML package > Ensembling
Certain machine learning transforms that don’t implement the IRowToRowMapper interface fail during Ensembling. Examples include getSentiment() and featurizeImage().
To work around this error, you can pre-featurize data using rxFeaturize(). The only other alternative is to avoid mixing Ensembling with transforms that produce this error. Finally, you could also wait until the issue is fixed in the next release.
4. Spark compute context: modelCount=1 does not work with rxTextData
Applies to: MicrosoftML package > Ensembling
modelCount = 1 does not work when used with rxTextData() on Hadoop/Spark. To work around this issue, set the property to greater than 1.
5. Cloudera: "install_mrs_parcel.py" does not exist
If you are performing a parcel installation of R Server in Cloudera, you might notice a message directing you to use a python installation script for automated deployment. The exact message is "If you wish to automate the Parcel installation please run:", followed by "install_mrs_parcel.py". Currently, that script is not available. Ignore the message.
6. Cloudera: Connection error related to libjvm or libhdfs package dependencies
R Server has a package dependency that is triggered only under a very specific configuration:
- R Server was installed on CDH via parcel generator
- RStudio is the IDE
- Operation runs in local compute context on an edge node in a Hadoop cluster
Under this configuration, a failed operation could be the result of a package dependency, which is evident in the error message stack through warnings about a missing libjvm or libhdfs package.
The workaround is to recreate the symbolic link, update the site file, and restart R Studio.
Create this symlink:
sudo ln -s /usr/java/jdk1.7.0_67-cloudera/jre/lib/amd64/server/libjvm.so /opt/cloudera/parcels/MRS/hadoop/libjvm.soCopy the site file to the parcel repo and rename it to RevoHadoopEnvVars.site:
sudo cp ~/.RevoHadoopEnvVars.site /opt/cloudera/parcels/MRS/hadoop sudo mv /opt/cloudera/parcels/MRS/hadoop/.RevoHadoopEnvVars.site /opt/cloudera/parcels/MRS/hadoop/RevoHadoopEnvVars.siteRestart RStudio after the changes:
sudo rstudio-server restart
7. Long delays when consuming web service on Spark
If you encounter long delays when trying to consume a web service created with mrsdeploy functions in a Spark compute context, you may need to add some missing folders. The Spark application belongs to a user called 'rserve2' whenever it is invoked from a web service using mrsdeploy functions.
To work around this issue, create these required folders for user 'rserve2' in local and hdfs:
hadoop fs -mkdir /user/RevoShare/rserve2
hadoop fs -chmod 777 /user/RevoShare/rserve2
mkdir /var/RevoShare/rserve2
chmod 777 /var/RevoShare/rserve2
Next, create a new Spark compute context:
rxSparkConnect(reset = TRUE)
When 'reset = TRUE', all cached Spark Data Frames are freed and all existing Spark applications belonging to the current user are shut down. If you encounter long delays when trying to consume a web service created with mrsdeploy functions in a Spark compute context, you may need to add some missing folders. The Spark application belongs to a user called “rserve2” whenever it is invoked from a web service using mrsdeploy functions.
To work around this issue, create these required folders for user “rserve2” in local and hdfs:
hadoop fs -mkdir /user/RevoShare/rserve2
hadoop fs -chmod 777 /user/RevoShare/rserve2
mkdir /var/RevoShare/rserve2
chmod 777 /var/RevoShare/rserve2
Now, to create a clean Spark compute context, then run:
rxSparkConnect(reset = TRUE)
The 'reset' parameter kills all pre-existing yarn applications, and create a new one.
8. Web node connection to compute node times out during a batch execution.
If you are consuming a long-running web service via batch mode, you may encounter a connection timeout between the web and compute node. In batch executions, if a web service is still running after 10 minutes, the connection from the web node to the compute node times out. The web node then starts another session on another compute node or shell. The initial shell that was running when the connection timed out continues to run but never returns a result.
Microsoft R Server 9.0.1
Package: RevoScaleR > Distributed Computing
- On SLES 11 systems, there have been reports of threading interference between the Boost and MKL libraries.
- The value of consoleOutput that is set in the
RxHadoopMRcompute context whenwait=FALSEdetermines whether or notconsoleOutputis displayed whenrxGetJobResultsis called; the value ofconsoleOutputin the latter function is ignored. - When using
RxInTeradata, if you encounter an intermittent failure, try resubmitting your R command. - The
rxDataStepfunction does not support thevarsToKeepandvarsToDroparguments inRxInTeradata. - The
dataPathandoutDataPatharguments for theRxHadoopMRcompute context are not yet supported. - The
rxSetVarInfofunction is not supported when accessing xdf files with theRxHadoopMRcompute context. - When specifying a non-default
RNGkindas an argument torxExec, identical random number streams can be generated unless theRNGseedis also specified. - When using small test data sets on a Teradata appliance, some test failures may occur due to insufficient data on each AMP.
- Adding multiple new columns using
rxDataStepwithRxTeradatadata sources fails in local compute context. As a workaround, useRxOdbcDatadata sources or theRxInTeradatacompute context.
Package: RevoScaleR > Data Import and Manipulation
- Appending to an existing table is not supported when writing to a Teradata database.
- When reading
VARCHARcolumns from a database, white space is trimmed. To prevent this, enclose strings in non-white-space characters. - When using functions such as
rxDataStepto create database tables withVARCHARcolumns, the column width is estimated based on a sample of the data. If the width can vary, it may be necessary to pad all strings to a common length. - Using a transform to change a variable's data type is not supported when repeated calls to
rxImportorrxTextToXdfare used to import and append rows, combining multiple input files into a single .xdf file. - When importing data from the Hadoop Distributed File System, attempting to interrupt the computation may result in exiting the software.
Package: RevoScaleR > Analysis Functions
- Composite xdf data set columns are removed when running
rxPredict(.)withrxDForest(.)in Hadoop and writing to the input file. - The
rxDTreefunction does not currently support in-formula transformations; in particular, using theF()syntax for creating factors on the fly is not supported. However, numeric data is automatically binned. - Ordered factors are treated the same as factors in all RevoScaleR analysis functions except
rxDTree.
Package: RevoIOQ
- If the
RevoIOQfunction is run concurrently in separate processes, some tests may fail.
Package: RevoMods
- The
RevoModstimestamp() function, which masks the standard version from the utils package, is unable to find theC_addhistoryobject when running in an Rgui, Rscript, etc. session. If you are callingtimestamp(), call theutilsversion directly asutils::timestamp().
R Base and Recommended Packages
- In the
nlsfunction, use of theportalgorithm occasionally causes the R front end to stop unexpectedly. Thenlshelp file advises caution when using this algorithm. We recommend avoiding it altogether and using either the default Gauss-Newton or plinear algorithms.
Operationalize (Deploy & Consume Web Services) features formerly referred to as DeployR
- When Azure active directory authentication is the only form of authentication enabled, it is not possible to run diagnostics.
Microsoft R Server 8.0.5
Package: RevoScaleR > Distributed Computing
- On SLES 11 systems, there have been reports of threading interference between the Boost and MKL libraries.
- The value of consoleOutput defined in the
RxHadoopMRcompute context whenwait=FALSEdetermines whetherconsoleOutputis displayed whenrxGetJobResultsis called. The value ofconsoleOutputin the latter function is ignored. - When using
RxInTeradata, if you encounter an intermittent failure, try resubmitting your R command. - The
rxDataStepfunction does not support thevarsToKeepandvarsToDroparguments inRxInTeradata. - The
dataPathandoutDataPatharguments for theRxHadoopMRcompute context are not yet supported. - The
rxSetVarInfofunction is not supported when accessing xdf files with theRxHadoopMRcompute context.
Package: RevoScaleR > Data Import and Manipulation
- Appending to an existing table is not supported when writing to a Teradata database.
- When reading
VARCHARcolumns from a database, white space is trimmed. To prevent this, enclose strings in non-white-space characters. - When using functions such as
rxDataStepto create database tables withVARCHARcolumns, the column width is estimated based on a sample of the data. If the width can vary, it may be necessary to pad all strings to a common length. - Using a transform to change a variable's data type is not supported when repeated calls to
rxImportorrxTextToXdfare used to import and append rows, combining multiple input files into a single .xdf file. - When importing data from the Hadoop Distributed File System, attempting to interrupt the computation may result in exiting the software.
Package: RevoScaleR > Analysis Functions
- Composite xdf data set columns are removed when running
rxPredict(.)withrxDForest(.)in Hadoop and writing to the input file. - The
rxDTreefunction does not currently support in-formula transformations; in particular, using theF()syntax for creating factors on the fly is not supported. However, numeric data is automatically binned. - Ordered factors are treated the same as factors in all RevoScaleR analysis functions except
rxDTree.
DeployR
On Linux, if you attempt to change the DeployR RServe port using the
adminUtilities.sh, the script incorrectly updates Tomcat'sserver.xmlfile, which prevents Tomcat from starting, and does not update the necessary theRserv.conffile. You must revert back to an earlier version ofserver.xmlto restore service.Using
deployrExternal()on the DeployR Server to reference a file that in a specified folder produces a ‘Connection Error’ due to an improperly defined environment variable. For this reason, you must log into the Administration Console and go to The Grid tab. In that tab, edit Storage Context value for each and every node and specify the full path to the external data directory on that node’s machine, such as<DEPLOYR_INSTALLATION_DIRECTORY>/deployr/external/data.
RevoIOQ Package
- If the
RevoIOQfunction is run concurrently in separate processes, some tests may fail.
RevoMods Package
- The
RevoModstimestamp() function, which masks the standard version from the utils package, is unable to find theC_addhistoryobject when running in an Rgui, Rscript, etc. session. If you are callingtimestamp(), call theutilsversion directly asutils::timestamp().
R Base and Recommended Packages
- In the nls function, use of the
portalgorithm occasionally causes the R front end to stop unexpectedly. The nls help file advises caution when using this algorithm. We recommend avoiding it altogether and using either the default Gauss-Newton or plinear algorithms.