教學課程 2:定型信用風險模型 - 機器學習 Studio (傳統)
適用於: 機器學習 Studio(傳統版)
機器學習 Studio(傳統版) Azure 機器學習
Azure 機器學習
重要
Machine Learning 工作室 (傳統) 的支援將於 2024 年 8 月 31 日結束。 建議您在該日期之前轉換成 Azure Machine Learning。
自 2021 年 12 月 1 日起,您將無法建立新的 Machine Learning 工作室 (傳統) 資源。 在 2024 年 8 月 31 日之前,您可以繼續使用現有的 Machine Learning 工作室 (傳統) 資源。
ML 工作室 (傳統) 文件即將淘汰,未來將不再更新。
在本教學課程中,您會深入瞭解開發預測性分析解決方案的程式。 您可以在 機器學習 Studio 中開發簡單的模型(傳統版)。 接著,您會將模型部署為 機器學習 Web 服務。 此已部署的模型可以使用新的數據進行預測。 本教學課程是 三部分教學課程系列的第二部分。
假設您需要根據他們在信用申請上提供的資訊來預測個人的信用風險。
信用風險評估是一個複雜的問題,但本教學課程會簡化它一點。 您將使用它作為如何使用 機器學習 Studio 建立預測性分析解決方案的範例(傳統版)。 您將針對此解決方案使用 機器學習 Studio(傳統版)和 機器學習 Web 服務。
在本三部分教學課程中,您會從公開可用的信用風險數據開始。 您接著會開發並定型預測模型。 最後,您會將模型部署為 Web 服務。
在本教學課程的第一部分中,您已建立 機器學習 Studio (傳統) 工作區、上傳的數據,以及建立實驗。
在本教學課程的這個部分中,您會:
- 定型多個模型
- 評分和評估模型
在本 教學課程的第三部分中,您會將模型部署為Web服務。
必要條件
完成 本教學課程的第一部分。
定型多個模型
使用 機器學習 Studio(傳統版)建立機器學習模型的優點之一,就是能夠在單一實驗中一次嘗試一種以上的模型,並比較結果。 這種類型的實驗可協助您找出問題的最佳解決方案。
在本教學課程中我們正在開發的實驗中,您將建立兩種不同類型的模型,然後比較其評分結果,以決定要在最終實驗中使用的演算法。
您可以選擇各種模型。 若要查看可用的模型,請展開模組選擇區中的 機器學習 節點,然後展開 [初始化模型] 及其下方的節點。 基於此實驗的目的,您將選取 雙類別支援向量機器 (SVM) 和 雙類別提升判定樹 模組。
您將在此實驗中新增 雙類別提升判定樹 模組和 雙類別支援向量機器 模組。
二級促進式決策樹
首先,設定提升式判定樹模型。
在模組調色盤中尋找雙類別提升判定樹模組,並將其拖曳到畫布上。
將左側執行 R 文稿模組的左側輸出連接到定型模型模組的右輸入埠(在本教學課程中,您已使用來自分割數據模組左側的數據進行定型)。
提示
您不需要此實驗的兩個輸入和其中一個執行 R 腳本模組的輸出,因此您可以將它們保持未連結。
實驗的這個部分現在看起來像這樣:
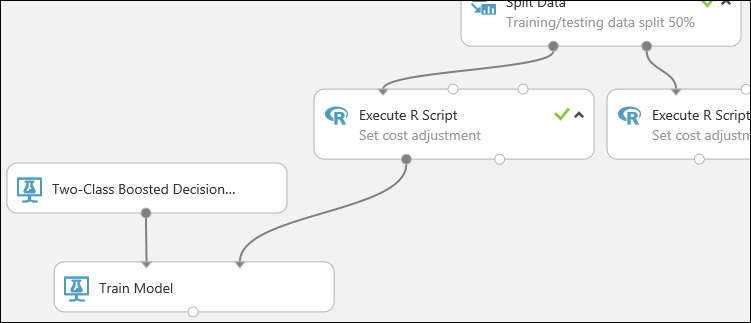
現在,您必須告訴 定型模型 模組,您希望模型預測信用風險值。
選取 [ 定型模型] 模組。 在 [ 屬性] 窗格中,按兩下 [ 啟動資料行選取器]。
在 [選取單一數據行] 對話框中,於 [可用數據行] 底下的搜尋欄位中輸入 「信用風險」,選取下方的 [信用風險],然後按兩下向右鍵按鈕 (>) 將 [信用風險] 移至 [選取的數據行]。
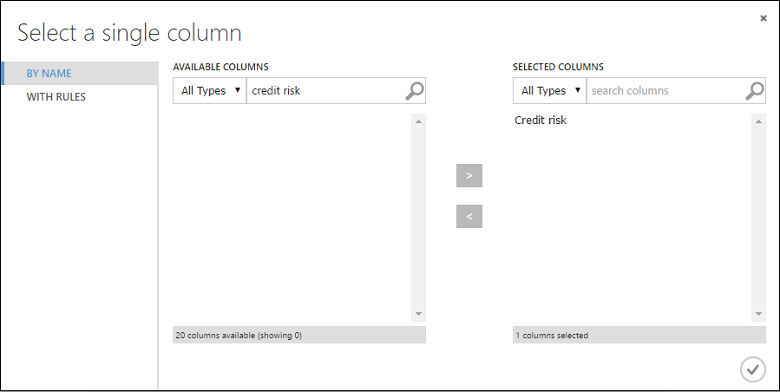
按兩下 [ 確定 ] 複選標記。
雙類別支援向量機
接下來,您會設定 SVM 模型。
首先,關於 SVM 的一些說明。 提升判定樹適用於任何類型的功能。 不過,由於 SVM 模組會產生線性分類器,因此當所有數值特徵具有相同小數字數時,所產生的模型就會產生最佳測試錯誤。 若要將所有數值特徵轉換成相同的小數位數,您可以使用 “Tanh” 轉換(搭配 Normalize Data 模組)。 這會將我們的數字轉換成 [0,1] 範圍。 SVM 模組會將字串功能轉換為類別功能,然後轉換成二進位 0/1 功能,因此您不需要手動轉換字串功能。 此外,您不想要轉換信用風險數據行 (數據行 21) - 它是數值,但這是我們訓練模型來預測的值,因此您必須將它單獨留在其中。
若要設定 SVM 模型,請執行下列動作:
在模組調色盤中尋找雙類別支援向量機器模組,並將其拖曳到畫布上。
以 滑鼠右鍵按兩下 [定型模型] 模組,選取 [複製],然後以滑鼠右鍵按兩下畫布,然後選取 [ 貼上]。 定型模型模組的 複本與原始數據 行選取範圍相同。
尋找標準化數據模組,並將其拖曳到畫布上。
將左側執行 R 腳本模組的左側輸出連接到此模組的輸入(請注意,模組的輸出埠可能連線到一個以上的其他模組)。
將標準化數據模組的左側輸出埠連接到第二個訓練模型模組的右輸入埠。
實驗的這個部分現在看起來應該像這樣:
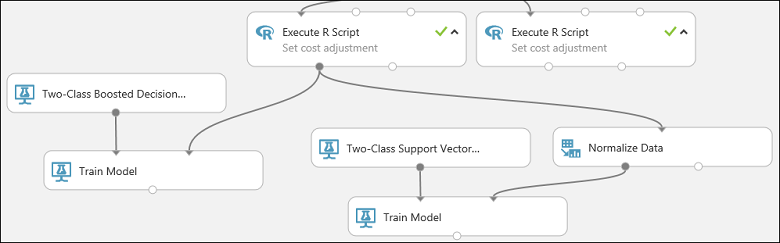
現在設定 Normalize 資料 模組:
按兩下以選取 [標準化數據 ] 模組。 在 [屬性] 窗格中,針對 Transformation 方法參數選取 Tanh。
按兩下 [啟動資料行選取器],選取 [開頭為] 的 [沒有數據行],在第一個下拉式清單中選取 [包含],在第二個下拉式清單中選取數據行類型,然後在第三個下拉式清單中選取 [數值]。 這會指定所有數值數據行(且只有數值)都會轉換。
按兩下此資料列右邊的加號 (+) - 這會建立下拉式清單的數據列。 在第 一個下拉式清單中選取 [排除 ],在第二個下拉式清單中選取 數據行名稱 ,然後在文字欄位中輸入「信用風險」。 這會指定應該忽略信用風險數據行(您需要這麼做,因為此數據行是數值,因此如果您未排除,則會轉換它)。
按兩下 [ 確定 ] 複選標記。
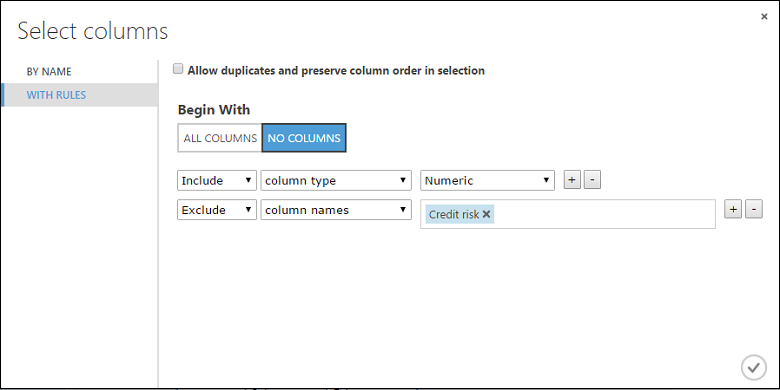
標準化數據模組現在會設定為對所有數值數據行執行 Tanh 轉換,但信用風險數據行除外。
評分和評估模型
您可以使用分割資料模組分隔 的測試數據 來為定型的模型評分。 然後,您可以比較兩個模型的結果,以查看產生更好的結果。
新增評分模型模組
尋找評分模型模組,並將其拖曳到畫布上。
將正確的執行 R 文稿模組 (我們的測試資料) 連接到評分模型模組的正確輸入埠。
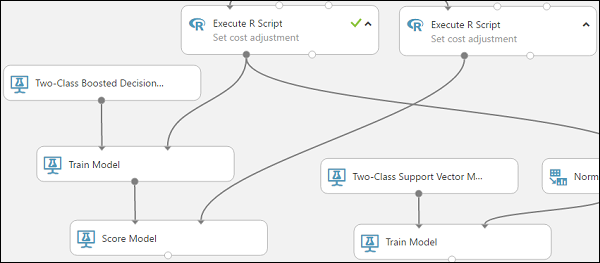
評分 模型 模組現在可以從測試數據擷取信用資訊、透過模型執行,以及比較模型在測試數據中產生的預測與實際信用風險數據行。
複製並貼上 評分模型 模組,以建立第二個複本。
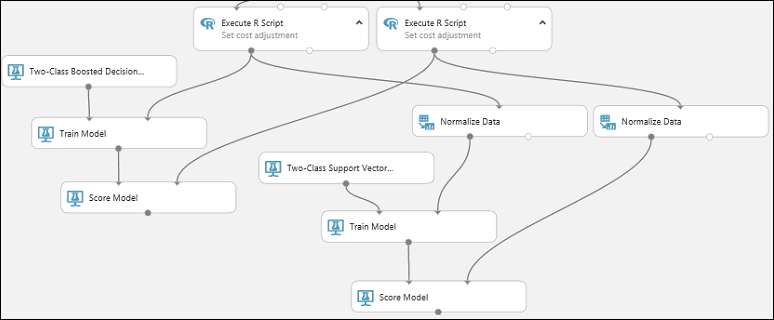
將 SVM 模型的輸出(也就是連接到雙類別支援向量機器模組的定型模型模組的輸出埠)連接到第二個評分模型模組的輸入埠。
針對 SVM 模型,您必須對測試資料執行與定型數據相同的轉換。 因此,複製並貼上 Normalize 數據 模組以建立第二個複本,並將其連線到正確的 執行 R 腳本 模組。
將第二個 標準化數據 模組的左側輸出連接到第二 個評分模型 模組的右輸入埠。
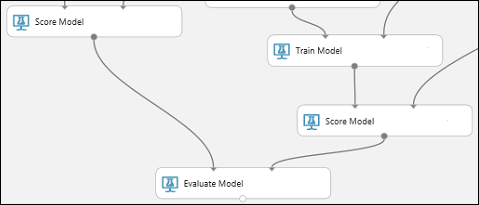
新增評估模型模組
若要評估兩個 評分結果並加以比較,請使用評估模型 模組。
執行實驗並檢查結果
若要執行實驗,請按下畫布下方的 [執行] 按鈕。 這可能需要幾分鐘的時間。 每個模組上的旋轉指示器會顯示其正在執行中,然後在模組完成時顯示綠色複選標記。 當所有模組都有複選標記時,實驗已完成執行。
實驗現在看起來應該像這樣:
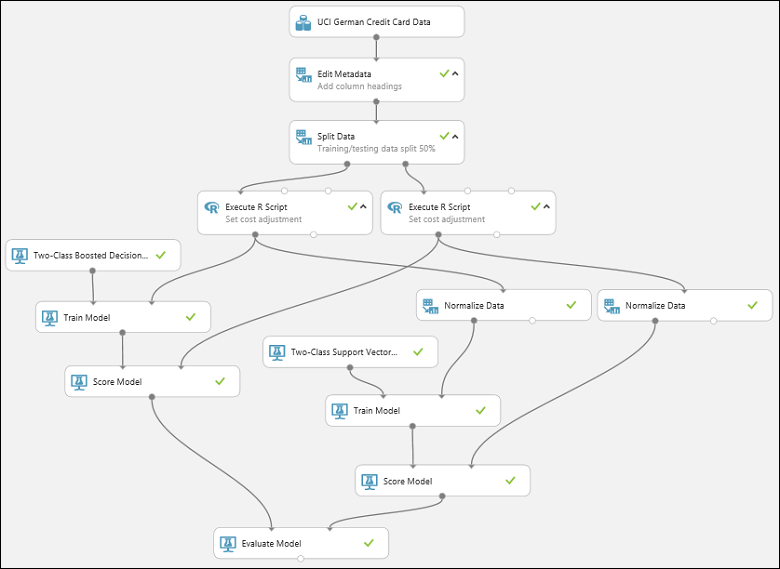
若要檢查結果,請按兩下評估模型模組的輸出埠,然後選取 [可視化]。
評估 模型 模組會產生一組曲線和計量,可讓您比較兩個評分模型的結果。 您可以將結果檢視為接收者運算子特性 (ROC) 曲線、精確度/回收曲線或增益曲線。 顯示的其他數據包括混淆矩陣、曲線下區域的累計值(AUC),以及其他計量。 您可以藉由向左或向右移動滑桿來變更閾值,並查看其如何影響計量集合。
在圖形右側,按兩下 [評分數據集] 或 [評分數據集] 進行比較,以反白顯示相關聯的曲線,並顯示下方相關聯的計量。 在曲線圖例中,「評分數據集」會對應至評估模型模組的左側輸入埠-在我們的案例中,這是提升的判定樹模型。 「要比較的評分數據集」對應至正確的輸入埠 - 在我們的案例中為 SVM 模型。 當您按兩下其中一個標籤時,該模型的曲線會反白顯示,並顯示對應的計量,如下圖所示。
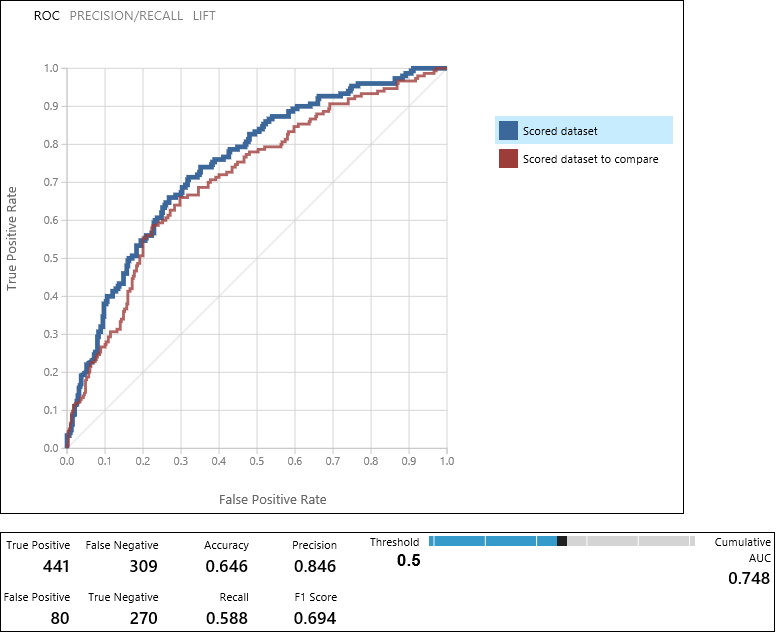
藉由檢查這些值,您可以決定哪一個模型最接近提供您要尋找的結果。 您可以變更不同模型中的參數值,來返回並逐一查看您的實驗。
解譯這些結果及微調模型效能的科學與藝術,已超出本教學課程的範圍。 如需其他說明,您可能會閱讀下列文章:
提示
每次執行實驗時,該反覆項目的記錄都會保留在執行歷程記錄中。 您可以按下 畫布下方的 [檢視執行歷程記錄 ] 來檢視這些反覆專案,並返回其中任何一個反覆運算。 您也可以按下 [屬性] 窗格中的 [先前執行],回到您開啟前的反復專案。
您可以按下 畫布下方的 [另存新檔 ],製作實驗的任何反覆項目複本。 使用實驗的 [摘要 ] 和 [描述 ] 屬性來記錄您在實驗反覆項目中嘗試的內容。
如需詳細資訊,請參閱在 機器學習 Studio 中管理實驗反覆專案(傳統版)。
清除資源
如果您不再需要使用本文建立的資源,請將其刪除,以避免產生任何費用。 瞭解如何在文章中匯出 和刪除產品內用戶數據。
下一步
在本教學課程中,您已完成下列步驟:
- 建立實驗
- 定型多個模型
- 評分和評估模型
您現在已準備好部署此數據的模型。